Wat is query-optimalisatie in SQL Server? Het is een groot onderwerp. Elke techniek of elk probleem heeft een apart artikel nodig om de basis te dekken. Maar als je net begint met het verbeteren van je spel met vragen, heb je iets eenvoudigers nodig om op te vertrouwen. Dit is het doel van dit artikel.
Je zou kunnen zeggen dat je zoekopdrachten optimaal zijn, dat alles goed presteert en dat gebruikers tevreden zijn. Prestaties zijn natuurlijk niet alles. De resultaten moeten ook correct zijn. Of het nu een join, een subquery, een synoniem, een CTE, een weergave of wat dan ook is, het moet acceptabel presteren.
En aan het eind van de dag kunt u met uw gebruikers naar huis. Je wilt niet van de ene op de andere dag op kantoor blijven zitten om de traag lopende vragen op te lossen.
Voordat we beginnen, wil ik je verzekeren dat de reis niet zwaar zal zijn. Dit zal slechts een inleiding zijn. We zullen voorbeelden hebben die ook voor jou niet te vreemd zullen zijn. Tot slot, wanneer u klaar bent voor een diepere studie, zullen we enkele links presenteren die u kunt bekijken.
Laten we beginnen.
1. Optimalisatie van SQL-query's begint bij ontwerp en architectuur
Verrast? Optimalisatie van SQL-query's is geen bijzaak of een pleister als er iets kapot gaat. Uw zoekopdracht wordt zo snel uitgevoerd als uw ontwerp toelaat. We hebben het over genormaliseerde tabellen, de juiste datatypes, het gebruik van indexen, archivering van oude data en alle best practices die je maar kunt bedenken.
Een goed database-ontwerp werkt in synergie met de juiste hardware en SQL Server-instellingen. Heb je het zo ontworpen dat het een aantal jaren soepel loopt en nog steeds als nieuw aanvoelt? Dat is een grote droom, maar we hebben maar een bepaalde (meestal – korte) tijd om erover na te denken.
Het zal niet perfect zijn op dag 1 in productie, maar we hadden de basis moeten afdekken. We minimaliseren de technische schuld. Als je met een team werkt, is dat geweldig in vergelijking met een eenmansshow. Je kunt veel van de toeters en bellen afdekken.
Maar wat als de database live draait en u de prestatiemuur raakt? Hier zijn enkele tips en trucs voor het optimaliseren van SQL-query's.
2. Spot problematische vragen met het standaardrapport van SQL Server
Wanneer u aan het coderen bent, is het gemakkelijk om een lange reeks code of een opgeslagen procedure te herkennen. Je kunt het regel voor regel debuggen. De lijn die achterblijft, is degene die moet worden gerepareerd.
Maar wat als uw helpdesk een dozijn tickets weggooit omdat het traag is? Gebruikers kunnen de exacte locatie in de code niet bepalen, en de helpdesk ook niet. Tijd is je ergste vijand.
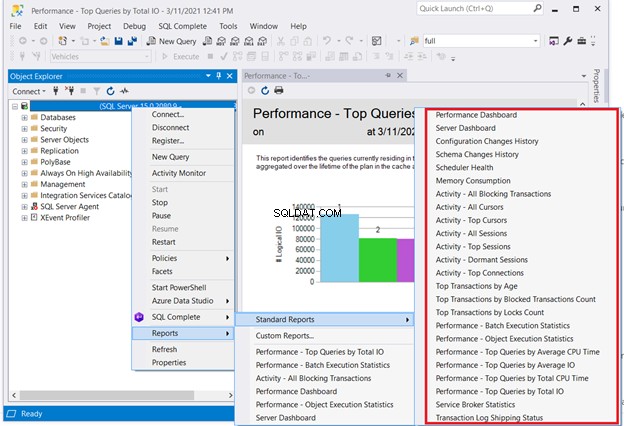
Een oplossing die geen codering vereist, is het controleren van de standaardrapporten van SQL Server. Klik met de rechtermuisknop op de benodigde server in SQL Server Management Studio> Rapporten> Standaardrapporten . Ons interessante punt kan zijn Prestatiedashboard of Prestaties – Topquery's op basis van totale I/O . Kies de eerste zoekopdracht die slecht presteert. Start vervolgens de optimalisatie van de SQL-query of het afstemmen van de SQL-prestaties vanaf daar.
3. SQL-query afstemmen met STATISTICS IO
Na het lokaliseren van de betreffende query, kunt u beginnen met het controleren van logische reads in STATISTICS IO. Dit is een van de hulpprogramma's voor het optimaliseren van SQL-query's.
Er zijn een paar I/O-punten, maar u moet zich concentreren op logische uitlezingen. Hoe hoger de logische uitlezingen, hoe problematischer de queryprestaties zijn.
Door de volgende 3 factoren te verminderen, kunt u de prestatieafstemmingsquery's in SQL versnellen:
- hoge logische waarden,
- hoge LOB logische uitlezingen,
- of hoge logische waarden voor WorkTable/WorkFile.
Om de informatie over logische uitlezingen te krijgen, schakelt u STATISTICS IO in het queryvenster van SQL Server Management Studio in.
STATISTIEKEN INSTELLEN IO AAN
U kunt de uitvoer op het tabblad Berichten krijgen nadat de query is voltooid. Afbeelding 2 toont de voorbeelduitvoer:
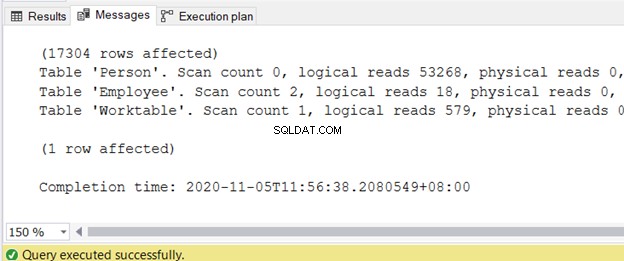
Ik heb een apart artikel geschreven over het verminderen van logische reads in 3 Nasty I/O-statistieken die achterblijven bij de prestaties van SQL-query's. Raadpleeg het voor de exacte stappen en codevoorbeelden met hoge logische waarden en manieren om ze te verminderen.
4. Afstemming van SQL-query's met uitvoeringsplannen
Logisch lezen alleen geeft je niet het hele plaatje. De reeks stappen die door de query-optimizer zijn gekozen, vertellen het verhaal van uw resultatenset. Hoe begint het allemaal nadat je de query hebt uitgevoerd?
Afbeelding 3 hieronder is een diagram van wat er gebeurt nadat u de uitvoering heeft geactiveerd tot het moment dat u de resultatenset krijgt.
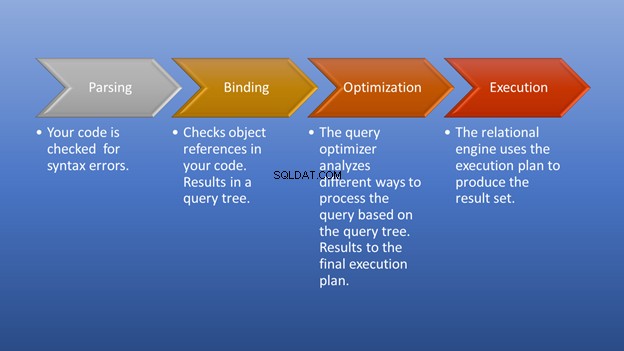
Parseren en binden gebeurt in een flits. Het geweldige deel is de optimalisatiefase, waar onze focus op ligt. In dit stadium speelt de query-optimizer een cruciale rol bij het selecteren van het best mogelijke uitvoeringsplan. Hoewel dit onderdeel wat middelen nodig heeft, bespaart het veel tijd wanneer het een efficiënt uitvoeringsplan kiest. Dit gebeurt dynamisch, omdat de database in de loop van de tijd verandert. Op deze manier kan de programmeur zich concentreren op het vormen van het uiteindelijke resultaat.
Elk plan dat de query-optimizer beschouwt, heeft zijn querykosten. Van de vele opties kiest de optimizer het plan met de meest redelijke kosten. Opmerking :Redelijke kosten zijn niet gelijk aan de laagste kosten. Het moet ook overwegen welk plan de snelste resultaten zal opleveren. Het plan met de minste kosten is niet altijd het snelste. De optimizer kan er bijvoorbeeld voor kiezen om meerdere processorkernen te gebruiken. We noemen dit parallelle uitvoering. Dit zal meer bronnen verbruiken, maar sneller werken in vergelijking met seriële uitvoering.
Een ander aandachtspunt is de statistiek. De query-optimizer vertrouwt erop om uitvoeringsplannen te maken. Als de statistieken verouderd zijn, verwacht dan niet de beste beslissing van de query-optimizer.
Wanneer het plan is vastgesteld en de uitvoering vordert, ziet u de resultaten. Wat nu?
Inspecteer het uitvoeringsplan voor query's in SQL Server
Wanneer u een query maakt, wilt u eerst de resultaten zien. De resultaten moeten kloppen. Als dat zo is, ben je klaar.
Is dat zo?
Als u weinig tijd heeft en de baan op het spel staat, kunt u daarmee instemmen. Bovendien kun je altijd terugkomen. Als er echter andere problemen optreden, kunt u ze keer op keer vergeten. En dan zal de geest van het verleden je opjagen.
Wat kun je nu het beste doen nadat je de juiste resultaten hebt gekregen?
Inspecteer het Daadwerkelijke uitvoeringsplan of de Live Query-statistieken !
Dit laatste is goed als uw zoekopdracht traag verloopt en u wilt zien wat er elke seconde gebeurt terwijl de rijen worden verwerkt.
Soms dwingt de situatie u om het plan onmiddellijk te inspecteren. Druk om te beginnen op Control-M of klik op Inclusief daadwerkelijk uitvoeringsplan uit de werkbalk van SQL Server Management Studio. Als u de voorkeur geeft aan dbForge Studio voor SQL Server, ga dan naar Query Profiler - het biedt dezelfde informatie + een aantal toeters en bellen die je niet kunt vinden in SSMS.
We hebben het Daadwerkelijke uitvoeringsplan gezien . Laten we verder gaan.
Is er een ontbrekende index of indexaanbevelingen?
Een ontbrekende index is gemakkelijk te herkennen - u krijgt onmiddellijk een waarschuwing.
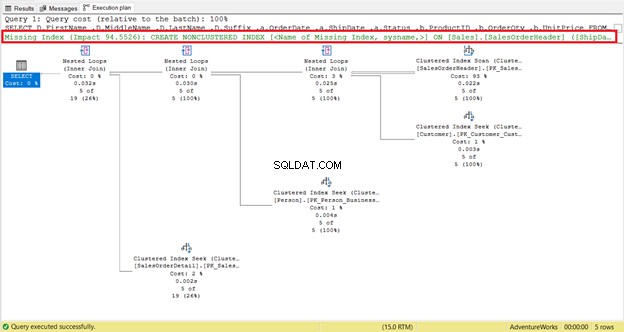
Klik met de rechtermuisknop op de Ontbrekende index . om direct een code te krijgen om de index te maken bericht (omkaderd in rood). Selecteer vervolgens Ontbrekende indexdetails . Er verschijnt een nieuw queryvenster met de code om de ontbrekende index te maken. Maak de index.
Dit deel is gemakkelijk te volgen. Het is een goed uitgangspunt om tot een snellere uitvoering te komen. Maar in sommige gevallen heeft het geen effect. Waarom? Sommige kolommen die nodig zijn voor uw zoekopdracht staan niet in de index. Daarom zal het terugkeren naar een geclusterde indexscan.
U moet het uitvoeringsplan opnieuw inspecteren nadat u de index hebt gemaakt om te zien of Opgenomen kolommen nodig zijn. Pas vervolgens de index dienovereenkomstig aan en voer uw zoekopdracht opnieuw uit. Controleer daarna het uitvoeringsplan opnieuw.
Maar wat als er geen ontbrekende index is?
Lees het uitvoeringsplan
Je moet een paar basisdingen weten om te beginnen:
- Operators
- Eigenschappen
- Leesrichting
- Waarschuwingen
OPERATOREN
De query-optimizer gebruikt een soort miniprogramma's die operators worden genoemd. Je hebt er een aantal gezien in figuur 4 – Geclusterde index zoeken , Geclusterde indexscan , Geneste lussen , en Selecteer .
Voor een uitgebreide lijst met namen, pictogrammen en beschrijvingen kunt u deze referentie van Microsoft raadplegen.
EIGENSCHAPPEN
Grafische diagrammen zijn niet voldoende om te begrijpen wat er achter de schermen gebeurt. U moet dieper in de eigenschappen van elke operator graven. Bijvoorbeeld de Geclusterde Index Scan in Afbeelding 4 heeft de volgende eigenschappen:
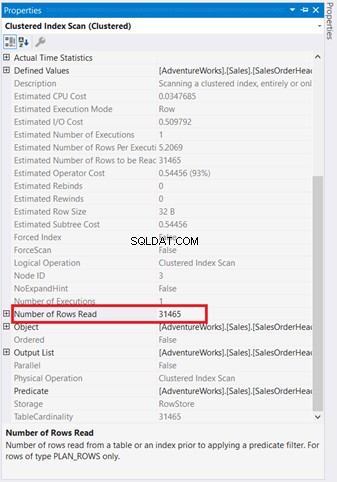
Als u het zorgvuldig onderzoekt, de Clustered Index Scan bediener is verschrikkelijk. Zoals figuur 5 laat zien, werden 31.465 rijen weergegeven, maar de uiteindelijke resultatenset is slechts 5 rijen. Daarom is er een indexaanbeveling in figuur 4 om het aantal gelezen rijen te verminderen. De logische uitlezingen van de query zijn ook hoog en dit verklaart waarom.
Als u meer van deze eigenschappen wilt weten, bekijk dan de lijst met algemene operatoreigenschappen en planeigenschappen.
LEESRICHTING
Over het algemeen is het alsof je Japanse manga leest - van rechts naar links. Volg de pijlen die naar links wijzen. Hier is een eenvoudig voorbeeld van dbForge Studio voor SQL Server.
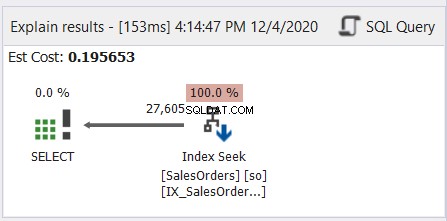
Zoals figuur 6 laat zien, wijst de pijl naar links van de Index Seek-operator naar de SELECT-operator.
Het lezen van rechts naar links is echter niet altijd correct. Zie figuur 7 met een voorbeeld uit SSMS:
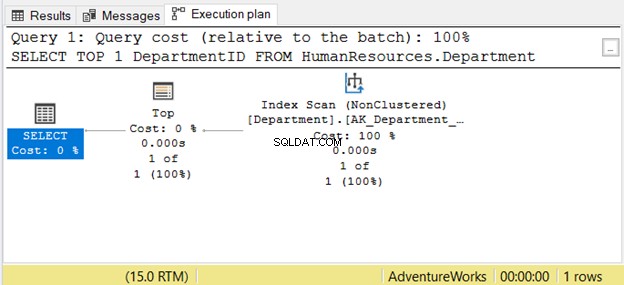
Als u het van rechts naar links leest, ziet u dat de Index Scan operator output is 1 van 1 rij. Hoe kon het maar 1 rij weten om op te halen? Het komt door de Top exploitant. Dit zal ons in verwarring brengen als we het van rechts naar links lezen.
Om dit geval beter te begrijpen, leest u het als "de SELECT-operator gebruikt Top om 1 rij op te halen met Index Scan". Dat is van links naar rechts.
Wat moeten we gebruiken? Van rechts naar links of van links naar rechts?
Het is een beetje van beide - wat u ook helpt het plan te begrijpen.
Terwijl de pijl ons de richting van de gegevensstroom geeft, geeft de dikte ons enkele hints over de grootte van de gegevens. Laten we nogmaals naar figuur 4 verwijzen.
De geclusterde indexscan naar de geneste lus . gaan heeft een dikkere pijl in vergelijking met de andere. De Eigenschappen details van Index Scan vertel ons in figuur 5 waarom het dik is (31.465 rijen gelezen voor een eindresultaat van 5 rijen).
WAARSCHUWINGEN
Een waarschuwingspictogram dat verschijnt in de uitvoeringsplan-operator vertelt ons dat er iets ergs is gebeurd in die operator. Dit kan de optimalisatie van uw SQL-query's belemmeren door meer bronnen te verbruiken.
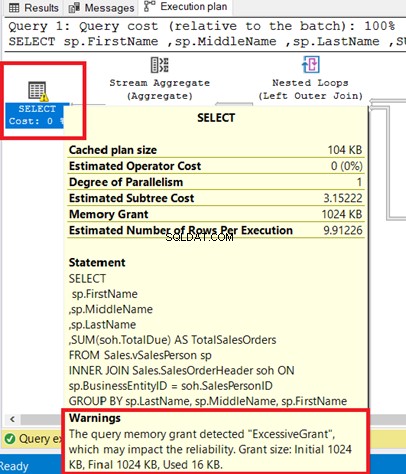
U kunt de waarschuwing zien in de SELECT-operator. Als u naar die operator zweeft, wordt het waarschuwingsbericht weergegeven. Een Excessive Grant heeft deze waarschuwing veroorzaakt.
ExcessiveGrant gebeurt wanneer er minder geheugen wordt gebruikt dan was gereserveerd voor de query. Raadpleeg deze Microsoft-documentatie voor meer informatie.
Afbeelding 8 toont de query die wordt gebruikt als INNER JOIN van een weergave naar een tabel. U kunt de waarschuwing verwijderen door basistabellen samen te voegen in plaats van de weergave.
Nu u een basisidee heeft van het lezen van uitvoeringsplannen, hoe kunt u bepalen wat uw zoekopdracht traag maakt?
Ken de 5 veelvoorkomende schurken van planoperators
De vertraging bij het uitvoeren van uw zoekopdracht is als een misdaad. Je moet deze schurken achtervolgen en arresteren.
1. Geclusterde of niet-geclusterde indexscan
De eerste schurk waar iedereen iets over te weten komt, is Geclusterd of Niet-geclusterde indexscan . Het is algemeen bekend dat scans slecht zijn en zoekopdrachten goed zijn bij het optimaliseren van SQL-query's. We hebben er een gezien in figuur 4. Vanwege de ontbrekende index, de Clustered Index Scan leest 31.465 om 5 rijen te krijgen.
Het is echter niet altijd het geval. Beschouw 2 zoekopdrachten in dezelfde tabel in figuur 9. De ene heeft een zoekopdracht en de andere heeft een scan.
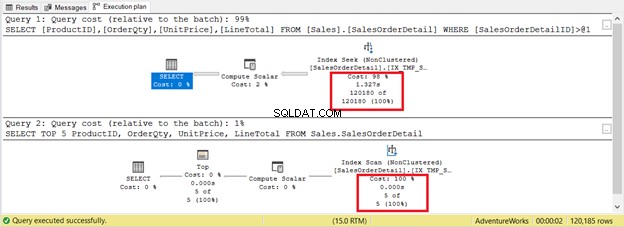
Als je de criteria alleen baseert op het aantal records, wint de indexscan met slechts 5 records vs. 120.180. Het zoeken naar de index duurt langer.
Hier is nog een voorbeeld waarbij scannen of zoeken er bijna niet toe doet. Ze retourneren dezelfde 6 records uit dezelfde tabel. De logische uitlezingen zijn hetzelfde en de verstreken tijd is in beide gevallen nul. De tafel is erg klein met slechts 6 platen. Voeg het daadwerkelijke uitvoeringsplan toe en voer de onderstaande instructies uit.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Sla vervolgens het uitvoeringsplan op om later te vergelijken. Klik met de rechtermuisknop op het uitvoeringsplan> Bewaar uitvoeringsplan als .
Voer nu de onderstaande query uit.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Klik vervolgens met de rechtermuisknop op het uitvoeringsplan en selecteer Showplan vergelijken . Selecteer vervolgens het bestand dat u eerder hebt opgeslagen. U zou dezelfde output moeten hebben als in Afbeelding 10 hieronder.
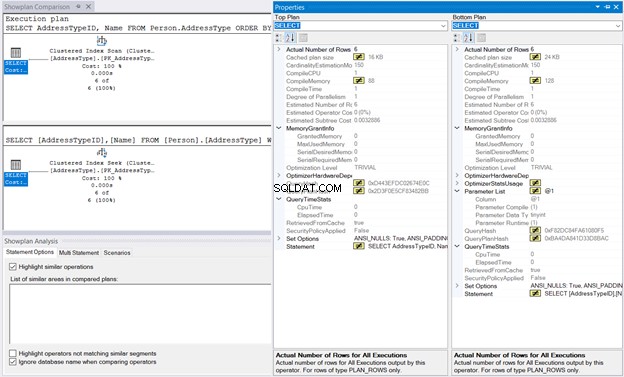
De MemoryGrant en QueryTimeStats zijn hetzelfde. Het 128 KB CompileMemory gebruikt in de Geclusterde Index Zoeken vergeleken met 88 KB van de Clustered Index Scan is bijna te verwaarlozen. Zonder deze cijfers om te vergelijken, zal de uitvoering hetzelfde aanvoelen.
2. Tabelscans vermijden
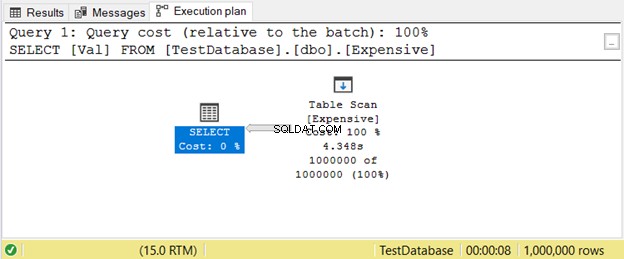
Dit gebeurt wanneer u geen index heeft. In plaats van naar waarden te zoeken met behulp van een index, scant SQL Server de rijen één voor één totdat het krijgt wat u nodig hebt in uw query. Dit zal veel achterblijven op grote tafels. De eenvoudige oplossing is om de juiste index toe te voegen.
Hier is een voorbeeld van een uitvoeringsplan met Tabelscan operator in Afbeelding 11.
3. Sorteerprestaties beheren
Zoals het uit de naam komt, verandert het de volgorde van rijen. Dit kan een dure operatie zijn.
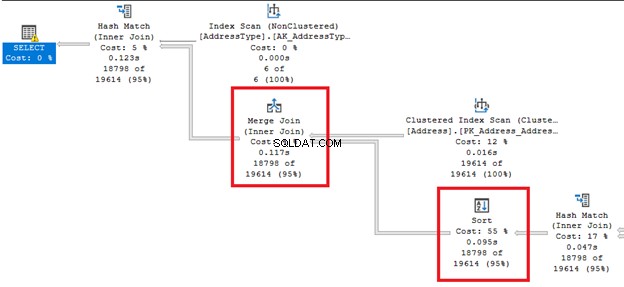
Kijk naar die dikke pijllijnen rechts en links van de Sorteren exploitant. Aangezien de query-optimizer besloot om een Samenvoeg-join te doen , een sortering Is benodigd. Merk ook op dat het de hoogste procentuele kosten heeft van alle operators (55%).
Sorteren kan lastiger zijn als SQL Server meerdere keren rijen moet bestellen. U kunt deze operator vermijden als uw tabel is voorgesorteerd op basis van de queryvereiste. Of u kunt een enkele zoekopdracht opsplitsen in meerdere.
4. Elimineer sleutelzoekopdrachten
In figuur 4 hiervoor raadde SQL Server aan om nog een index toe te voegen. Ik deed het, maar het gaf me niet precies wat ik wilde. In plaats daarvan gaf het me een Index Seek naar de nieuwe index gecombineerd met een Key Lookup telefoniste.
Dus de nieuwe index voegde een extra stap toe.
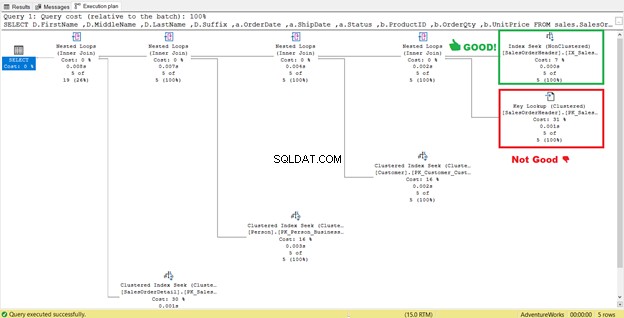
Wat doet deze Key Lookup operator doen?
De queryprocessor heeft een nieuwe niet-geclusterde index gebruikt die in het groen is weergegeven in Afbeelding 13. Omdat onze query kolommen vereist die niet in de nieuwe index staan, moet deze die gegevens ophalen met behulp van een Key Lookup uit de geclusterde index. Hoe weten we dit? Beweeg uw muis naar de Key Lookup onthult enkele van zijn eigenschappen en bewijst ons punt.
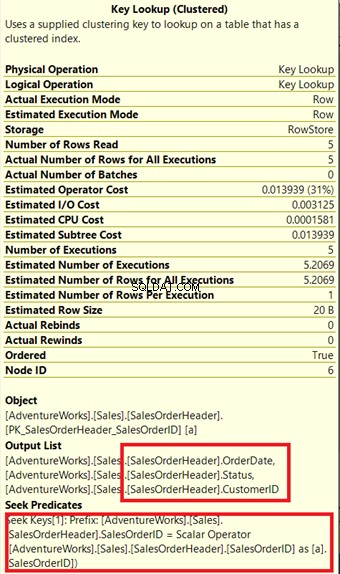
Let in Afbeelding 14 op de Uitvoerlijst. We moeten 3 kolommen ophalen met de PK_SalesOrderHeader_SalesOrderID geclusterde index. Om dit te verwijderen, moet u deze kolommen opnemen in de nieuwe index. Dit is het nieuwe plan zodra deze kolommen zijn opgenomen.
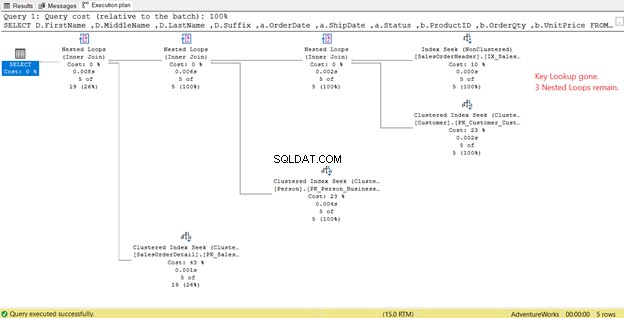
In figuur 14 zagen we 4 geneste lussen . De vierde is nodig voor de toegevoegde Key Lookup . Maar na het toevoegen van 3 kolommen als Inbegrepen kolommen aan de nieuwe index, zijn er slechts 3 Nested Loops blijven, en de Key Lookup is verwijderd. We hebben geen extra stappen nodig.
5. Parallellisme in uitvoeringsplan voor SQL Server
Tot nu toe zag je executieplannen in seriële uitvoering. Maar hier is het plan dat gebruikmaakt van parallelle uitvoering. Dit betekent dat meer dan 1 processor wordt gebruikt door de query-optimizer om de query uit te voeren. Wanneer we parallelle uitvoering gebruiken, zien we Parallisme operators in het plan, en ook andere wijzigingen.
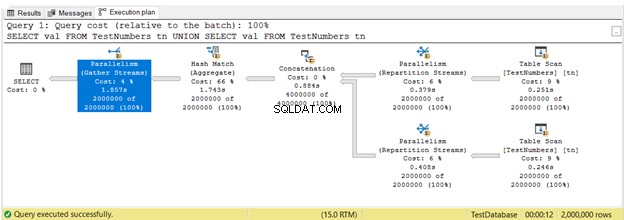
In Afbeelding 16, 3 Parallisme operatoren werden ingezet. Merk ook op dat de Tabelscan operator icoon is een beetje anders. Dit gebeurt wanneer parallelle uitvoering wordt gebruikt.
Parallellisme is niet per se slecht. Het verhoogt de snelheid van zoekopdrachten door meer processorkernen te gebruiken. Het gebruikt echter meer CPU-bronnen. Wanneer veel van uw zoekopdrachten parallellismen gebruiken, vertraagt dit de server. Misschien wilt u de kostendrempel voor de instelling van parallellisme in uw SQL Server controleren.
5. Aanbevolen procedures voor het optimaliseren van SQL-query's
Tot nu toe hebben we de optimalisatie van SQL-query's behandeld met methoden die moeilijk te herkennen problemen aan het licht brengen. Maar er zijn manieren om het in code te herkennen. Hier zijn enkele codegeuren in SQL.
Gebruik SELECT *
Haast hebben? Dan kan het typen van * gemakkelijker zijn dan het specificeren van kolomnamen. Er is echter een addertje onder het gras. Kolommen die u niet nodig heeft, blijven achter bij uw zoekopdracht.
Er is bewijs. De voorbeeldquery die ik voor Afbeelding 15 heb gebruikt, is deze:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
We hebben het al geoptimaliseerd. Maar laten we het veranderen in SELECT *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Het is korter, maar bekijk het Uitvoeringsplan hieronder:
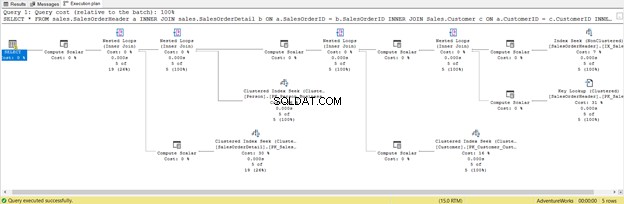
Dit is het gevolg van het opnemen van alle kolommen, ook de kolommen die u niet nodig heeft. Het retourneerde Key Lookup en veel Compute Scalar . Kortom, deze query is zwaar belast en zal daardoor achterblijven. Let ook op de waarschuwing in de SELECT-operator. Het was er niet eerder. Wat een verspilling!
Functies in een WHERE-clausule of JOIN
Een andere codegeur heeft een functie in de WHERE-component. Beschouw de volgende 2 SELECT-instructies met dezelfde resultatenset. Het verschil zit in de WHERE-clausule.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
De eerste SELECT gebruikt de datumfuncties JAAR en MAAND om de verzenddatums binnen juli 2011 aan te geven. De tweede SELECT-instructie gebruikt de operator BETWEEN met letterlijke datums.
De eerste SELECT-instructie heeft een uitvoeringsplan dat lijkt op Afbeelding 4, maar zonder de indexaanbeveling. De tweede heeft een beter uitvoeringsplan vergelijkbaar met figuur 15.
Degene die beter is geoptimaliseerd, ligt voor de hand.
Gebruik van jokertekens
Hoe wild kunnen jokertekens onze SQL-queryoptimalisatie beïnvloeden? Laten we een voorbeeld nemen.
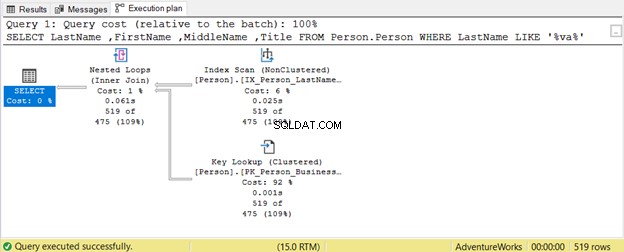
De zoekopdracht probeert te zoeken naar de aanwezigheid van een tekenreeks binnen Achternaam in elke positie. Vandaar, Achternaam LIKE '%va%' . Dit is inefficiënt op grote tabellen omdat rijen één voor één worden gecontroleerd op de aanwezigheid van die string. Daarom een Index Scan is gebruikt. Aangezien geen enkele index de Titel bevat kolom, een Key Lookup wordt ook gebruikt.
Dit kan door het ontwerp worden opgelost.
Vereist de bellende app dat? Of is het voldoende om LIKE 'va%' te gebruiken?
LIKE 'va%' gebruikt een Index Seek omdat de tabel een index heeft op achternaam , voornaam , en tweede naam .
Kun je ook meer filters toevoegen aan de WHERE-component om het lezen van de records te verminderen?
Uw antwoorden op deze vragen helpen u deze vraag op te lossen.
Impliciete conversie
SQL Server voert impliciete conversie achter de schermen uit om gegevenstypen met elkaar te verzoenen bij het vergelijken van waarden. Het is bijvoorbeeld handig om een nummer toe te wijzen aan een tekenreekskolom zonder aanhalingstekens. Maar er is een addertje onder het gras. Het effect is vergelijkbaar wanneer u een functie in een WHERE-component gebruikt.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
De NationalIDNumner is NVARCHAR (15) maar wordt gelijkgesteld aan een getal. Het zal succesvol worden uitgevoerd vanwege impliciete conversie. Maar let op het uitvoeringsplan in Afbeelding 19 hieronder.
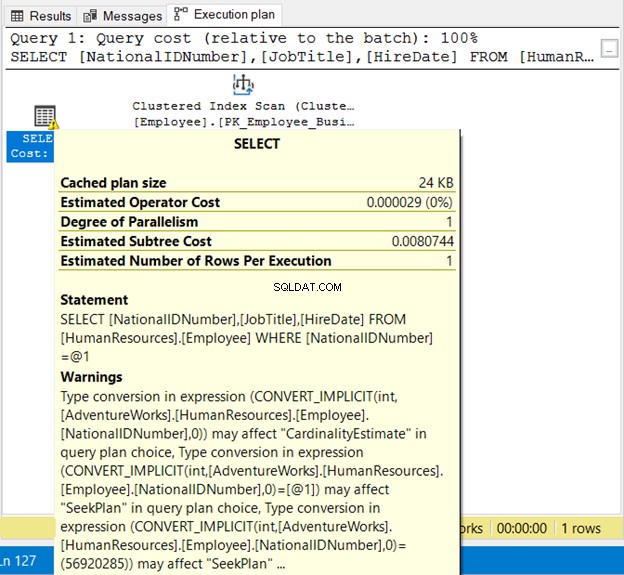
We zien hier 2 slechte dingen. Eerst de waarschuwing. Vervolgens wordt de Indexscan . De indexscan is uitgevoerd vanwege impliciete conversie. Zorg er dus voor dat u tekenreeksen tussen aanhalingstekens plaatst of test letterlijke waarden met hetzelfde gegevenstype als de kolom.
SQL Query Optimalisatie Takeaways
Dat is het. Hebben de basisprincipes van SQL-queryoptimalisatie ervoor gezorgd dat u zich een beetje klaar voelt voor uw query's? Laten we het even samenvatten.
- Als u uw zoekopdrachten wilt optimaliseren, begin dan met een goed database-ontwerp.
- Als de database al in productie is, zoek dan naar de problematische zoekopdrachten met behulp van standaardrapporten van SQL Server.
- Ontdek hoe groot de impact is van de langzame query met logische reads van STATISTICS IO.
- Graaf dieper in het verhaal van uw langzame zoekopdracht met Uitvoeringsplannen.
- Bekijk 4 codegeuren die uw zoekopdrachten vertragen.
Er zijn andere tips voor het optimaliseren van SQL-query's om een langzame query snel te laten verlopen. Zoals ik in het begin al zei, dit is een groot onderwerp. Laat ons dus in het gedeelte Opmerkingen weten wat we nog meer hebben gemist.
En als je dit bericht leuk vindt, deel het dan op je favoriete sociale mediaplatforms.
Meer optimalisatie van SQL-query's uit eerdere artikelen
Als je meer voorbeelden nodig hebt, zijn hier enkele nuttige berichten met betrekking tot query-optimalisatietechnieken in SQL Server.
- Zijn subquery's slecht voor de prestaties? Bekijk De eenvoudige handleiding voor het gebruik van subquery's in SQL Server .
- HierarchyID gebruiken versus ouder/kind-ontwerp - wat is sneller? Bezoek Hoe SQL Server HierarchyID te gebruiken via eenvoudige voorbeelden .
- Kunnen grafische databasequery's beter presteren dan hun relationele equivalenten in een realtime aanbevelingssysteem? Bekijk Gebruik maken van SQL Server Graph Database-functies .
- Wat is sneller:COALESCE of ISNULL? Ontdek het in Belangrijkste antwoorden op 5 brandende vragen over de SQL COALESCE-functie .
- SELECT FROM View vs. SELECT FROM Base Tables – welke zal sneller werken? Bezoek Top 3 tips die u moet weten om snellere SQL-weergaven te schrijven .
- CTE versus tijdelijke tabellen versus subquery's. Weet welke zal winnen in Alles wat u moet weten over SQL CTE op één plek .
- SQL SUBSTRING gebruiken in een WHERE-clausule - een prestatieval? Kijk of het waar is met voorbeelden in Hoe tekenreeksen als een professional te ontleden met de functie SQL SUBSTRING()?
- SQL UNION ALL is sneller dan UNION. Weet waarom in SQL UNION Cheatsheet met 10 eenvoudige en handige tips .