In mijn vorige artikel over SQL Server-systeemdatabases hebben we geleerd over elke systeemdatabase die deel uitmaakt van de installatie van SQL Server. Het huidige artikel richt zich op veelvoorkomende problemen rond de tempdb-database en hoe u deze correct kunt oplossen.
SQL Server TempDB
Zoals de naam van deze systeemdatabase aangeeft, tempdb bevat tijdelijke objecten gemaakt door SQL Server. Ze hebben betrekking op verschillende bewerkingen en fungeren als een wereldwijd werkgebied voor alle gebruikers die verbinding maken met SQL Server-instanties.
De Tempdb-database bevat de onderstaande objecttypen terwijl gebruikers hun bewerkingen uitvoeren:
- Tijdelijke objecten worden expliciet door gebruikers gemaakt. Dit kunnen lokale of globale tijdelijke tabellen en indexen zijn, tabelvariabelen, tabellen die worden gebruikt in functies met tabelwaarde en cursors.
- Interne objecten gemaakt door de database-engine zoals
- Werktabellen met tussentijdse resultaten voor spools, cursors, sorteringen en tijdelijke grote objecten (LOB).
- Werkbestanden tijdens het uitvoeren van Hash Join- of Hash-aggregatiebewerkingen.
- Tussenliggende sorteerresultaten tijdens het maken of opnieuw opbouwen van indexen als SORT_IN_TEMPDB is ingesteld op AAN, en andere bewerkingen zoals GROUP BY, ORDER BY of SQL UNION-query's.
- Versiearchieven die de functie Rijversiebeheer ondersteunen, ofwel Common version store of Online Index build version store, gebruiken de tempdb-databasebestanden.
Elke keer dat SQL Server Service wordt gestart, wordt de Tempdb-database gemaakt. Daarom kan de tijd van het maken van de tempdb-database worden beschouwd als een geschatte opstarttijd van SQL Server Service. We kunnen het identificeren aan de hand van sys.databases DMV met behulp van de onderstaande zoekopdracht:
SELECT name, database_id, create_date
FROM sys.databases
WHERE name = 'tempdb'
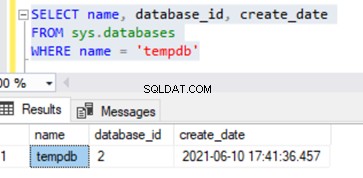
Het daadwerkelijke opstarten van SQL Server Service omvat echter het opstarten van alle systeemdatabases in een bepaalde volgorde. Het kan iets eerder gebeuren dan de aanmaaktijd van tempdb. We kunnen de waarde verkrijgen met behulp van sys.databases DMV door de onderstaande query uit te voeren op sys.dm_os_sys_info DMV .
SELECT ms_ticks, sqlserver_start_time_ms_ticks, sqlserver_start_time
FROM sys.dm_os_sys_info
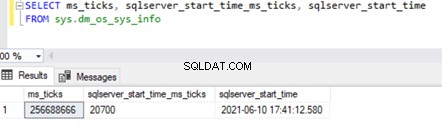
De ms_ticks kolom geeft het aantal milliseconden aan sinds de computer of server is gestart. De sqlserver_start_time_ms_ticks kolom specificeert het aantal milliseconden sinds de ms_ticks nummer toen de SQL Server-service begon.
We kunnen meer informatie vinden over de volgorde van databases die zijn opgestart tijdens het starten van de SQL Server-services in het SQL Server-foutlogboek.
Vouw in SSMS Beheer . uit > SQL Server-foutlogboeken > open de huidige foutenlogboek. Pas de Begin . toe database omhoog filter en klik op Datum om het in oplopende volgorde te sorteren:
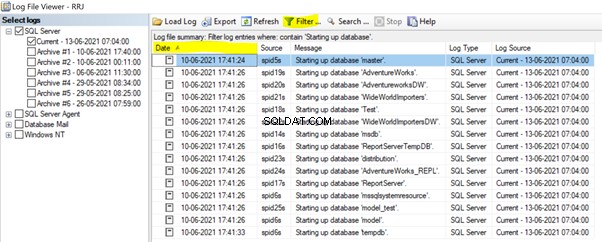
We kunnen zien dat de hoofddatabase als eerste is gestart tijdens het starten van de SQL Server-service. Daarna volgden alle gebruikersdatabases en alle andere systeemdatabases. Eindelijk begon de tempdb. U kunt deze informatie ook programmatisch ophalen door de xp_readerrorlog uit te voeren systeemprocedure:
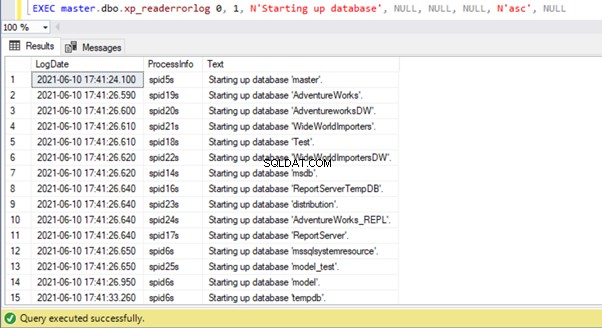
Opmerking :Beide bovenstaande benaderingen tonen mogelijk niet de benodigde informatie als de SQL Server-service niet recentelijk opnieuw is opgestart en het SQL Server-foutlogboek is gerecycled, waardoor oudere foutlogboeken mogelijk naar oudere bestanden zijn gepusht. In dat geval moeten we mogelijk de gegevens in de gearchiveerde SQL Server Error Log-bestanden scannen.
Veelvoorkomende problemen in SQL TempDB-database
Aangezien tempdb een globaal werkgebied biedt voor alle gebruikerssessies of -activiteiten, kan het een prestatieknelpunt worden voor gebruikersbewerkingen als het niet zorgvuldig wordt geconfigureerd. In mijn vorige artikel hebben we de aanbevolen best practices besproken om in de tempdb-database te implementeren. Maar zelfs nadat we ze hebben geïmplementeerd, kunnen we regelmatig problemen tegenkomen:
- Ongelijkmatige bestandsgroei in tempdb-gegevensbestanden.
- Tempdb-gegevensbestanden groeien naar een enorme waarde en moeten Tempdb verkleinen.
Ongelijkmatige bestandsgroei over TempDB-gegevensbestanden
Vanaf SQL Server 2000 is de standaardaanbeveling om meerdere gegevensbestanden te hebben op basis van het aantal logische kernen dat beschikbaar is in de server.
Wanneer we meerdere gegevensbestanden hebben, bijvoorbeeld 4 tempdb-gegevensbestanden zoals in de onderstaande afbeelding, zal de automatische groei van tempdb-gegevensbestanden plaatsvinden met 64 MB op een round-robin-manier vanaf tempdev> temp2> temp3> temp4> tempdev> enzovoort.
Als een van de bestandsgroottes om de een of andere reden niet automatisch kan groeien, zal dit resulteren in de enorme omvang van bepaalde bestanden in vergelijking met andere bestanden. Het leidt tot extra overbelasting van enorme bestanden en een negatieve invloed op de prestaties van de tempdb-database.
We moeten er handmatig voor zorgen dat alle tempdb-gegevensbestanden op elk moment handmatig de grootte hebben om de strijd of prestatieproblemen tot SQL Server 2014 te voorkomen. Microsoft veranderde dit gedrag vanaf SQL Server 2016 en latere versies door enkele functies te implementeren die zullen worden verderop in dit artikel besproken.
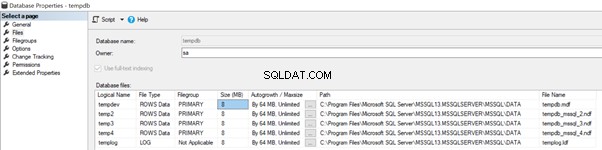
Om de bovenstaande prestatieproblemen te verhelpen, heeft SQL Server 2 Trace Flags . geïntroduceerd genaamd 1117 en 1118 om de twistproblemen rond tempdb te vermijden.
- Vlag 1117 traceren – maakt automatische groei van alle bestanden binnen een enkele bestandsgroep mogelijk
- Vlag 1118 traceren - schakelt UNIFORM VOLLEDIGE EXTENTS in voor tempdb
Vlag 1117 traceren
Als de traceringsvlag 1117 niet is ingeschakeld, zal SQL Server, wanneer tempdb is geconfigureerd met meerdere gegevensbestanden die even groot zijn en gegevensbestanden automatisch moeten groeien, standaard proberen de bestandsgrootte op een round-robin-manier te vergroten als alle bestanden. Als gegevensbestanden niet gelijk zijn qua grootte, zal SQL Server proberen de grootte van het grootste gegevensbestand van tempdb te vergroten en dit grotere bestand gebruiken voor de meeste gebruikersbewerkingen, wat resulteert in tempdb-conflicten.
Om dit probleem op te lossen, heeft SQL Server Trace Flag 1117 geïntroduceerd. Eenmaal ingeschakeld, als een bestand binnen een bestandsgroep automatisch moet groeien, zal het automatisch alle bestanden binnen die bestandsgroep laten groeien. Het lost de tempdb-conflicten op. Het nadeel is echter dat zodra Trace-vlag 1117 is ingeschakeld, automatische groei ook wordt geconfigureerd voor alle gebruikersdatabases.
Vlag 1118 traceren
Trace Flag 1118 wordt gebruikt om UNIFORM VOLLEDIGE EXTENTS in te schakelen. Laten we een stap terug doen om te begrijpen hoe SQL Server de basisgegevens opslaat.
Pagina is de fundamentele opslageenheid in SQL Server met een grootte van 8 kilobytes (KB).
Omvang is een set van 8 fysiek aaneengesloten pagina's met de grootte van 64KB (8*8KB). Op basis van hoeveel objecten of eigenaren de gegevens binnen een Omvang opslaan, kan Omvang worden ingedeeld in:
- Uniforme omvang zijn 8 aaneengesloten pagina's die worden gebruikt of geopend door een enkel object of eigenaar;
- Gemengd Omvang – zijn 8 aaneengesloten pagina's die worden gebruikt of geopend door minimaal 2 en maximaal 8 objecten of eigenaren
Door Trace Flag 1118 in te schakelen, kan tempdb uniforme extensies hebben, wat resulteert in betere prestaties.
Traceervlaggen 1117 &1118 inschakelen
Traceervlaggen kunnen op verschillende manieren worden ingeschakeld. U kunt de geschikte manier definiëren uit de onderstaande opties:
Opstartparameters SQL Server-service
Permanent beschikbaar, zelfs nadat de SQL-service opnieuw is opgestart. De aanbevolen manier is om Trace Flags 1117 en 1118 in te schakelen via de opstartparameters van SQL Server Service .
Open SQL Server Configuration Manager en klik op SQL Server Services om de beschikbare services op die server op te sommen:

- Klik met de rechtermuisknop op SQL Server (MSSQLSERVER) > Eigenschappen > Opstartparameters .
- Type –T in het lege veld om de Trace Flag . aan te geven .
- Geef waarden op 1117 en 1118 zoals hieronder weergegeven.
- Klik op Toevoegen om de traceervlaggen als opstartparameters toe te voegen.
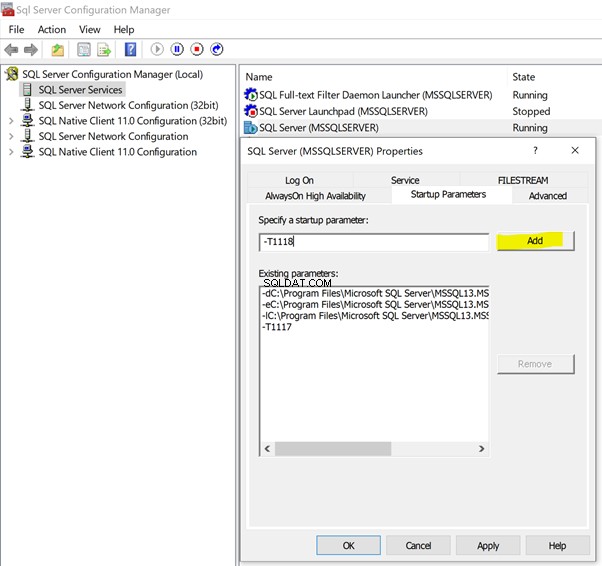
Klik vervolgens op OK om de traceringsvlaggen permanent te laten toevoegen voor dit exemplaar van SQL Server. Start de SQL Server-service opnieuw om de wijzigingen weer te geven.
DBCC TRACEON (, -1)
Een traceervlag globaal inschakelen. SQL Server-service verliest de traceringsvlaggen bij het opnieuw opstarten van de service. Om een traceervlag globaal in te schakelen, voert u het onderstaande script uit in een nieuw queryvenster:
DBCC TRACEON(1117,-1);
DBCC TRACEON(1118,-1);
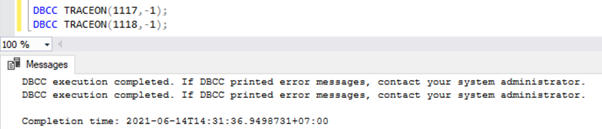
DBCC TRACEON ()
Schakel de traceringsvlag in op sessieniveau. Het is alleen van toepassing op de huidige sessie die door de gebruiker is gemaakt. Om een traceringsvlag op sessieniveau in te schakelen, voert u het onderstaande script uit in een nieuw queryvenster:
DBCC TRACEON(1117);
DBCC TRACEON(1118);
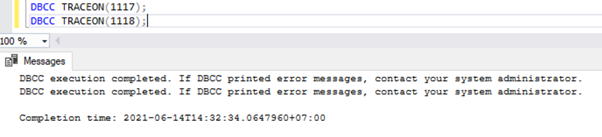
Om de lijst met traceervlaggen te bekijken die zijn ingeschakeld in een exemplaar van SQL Server, kunnen we de DBCC TRACESTATUS gebruiken commando:
DBCC TRACESTATUS();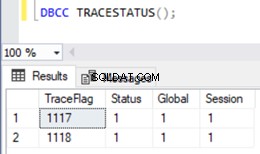
Zoals we kunnen zien, zijn Trace Flags 1117 en 1118 in mijn geval wereldwijd ingeschakeld samen met Session .
Om een traceervlag uit te schakelen, kunnen we het DBCC TRACEOFF-commando gebruiken zoals:
DBCC TRACEOFF(1117,-1);
DBCC TRACEOFF(1118,-1);
SQL Server 2016 TempDB-verbeteringen
In de SQL Server-versies SQL Server 2000 tot SQL Server 2014 moeten we Trace Flags 1117 en 1118 inschakelen, samen met volledige bewaking van tempdb om problemen met tempdb-conflicten te voorkomen. Vanaf SQL Server 2016 en latere versies zijn traceervlaggen 1117 en 1118 standaard geïmplementeerd.
Echter, op basis van mijn persoonlijke ervaring is het beter om tempdb vooraf te laten groeien tot een enorme grootte om de noodzaak van autogrowth meerdere keren te voorkomen en om ongelijke bestandsgroottes of afzonderlijke bestanden te elimineren die veelvuldig door SQL Server worden gebruikt .
We kunnen controleren hoe Trace Flag 1117 en 1118 zijn geïmplementeerd in SQL Server 2016:
Vlag 1117 traceren die de Autogrowth van alle bestanden binnen een bestandsgroep instelt, is nu een eigenschap van de bestandsgroep . We kunnen het configureren terwijl we een nieuwe bestandsgroep maken of een bestaande wijzigen.
Om de eigenschap voor automatisch groeien van de bestandsgroep te controleren , voer het onderstaande script uit vanuit sys.filegroups DMV :
SELECT name Filegroup_Name, is_autogrow_all_files
FROM sys.filegroups
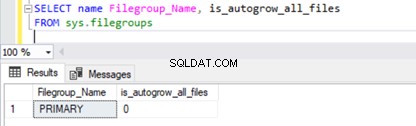
Om de eigenschap voor automatisch groeien van de primaire bestandsgroep van de AdventureWorks-database te wijzigen , voeren we het onderstaande script uit met AUTOGROW_ALL_FILES om alle bestanden automatisch gelijk te laten groeien, of AUTOGROW_SINGLE_FILE om automatische groei van slechts één gegevensbestand toe te staan.
ALTER DATABASE Adventureworks MODIFY FILEGROUP [PRIMARY]
AUTOGROW_SINGLE_FILE
-- AUTOGROW_ALL_FILES is the default behavior
GO
Vlag 1118 traceren die de eigenschap Uniforme omvang van gegevensbestanden instelt is standaard ingeschakeld voor tempdb en alle gebruikersdatabases vanaf SQL Server 2016 . We kunnen de eigenschappen voor tempdb niet wijzigen, omdat het nu alleen de optie Uniforme omvang ondersteunt.
Voor gebruikersdatabases kunnen we deze parameter wijzigen. De master, het model en de msdb van de systeemdatabases ondersteunen standaard gemengde extensies en kunnen ook niet worden gewijzigd.
Gebruik het onderstaande script om de eigenschapswaarden voor de toewijzing van gemengde pagina's voor gebruikersdatabases te wijzigen:
ALTER DATABASE Adventureworks SET MIXED_PAGE_ALLOCATION ON
-- OFF is the default behavior
GO
Om de eigenschap Gemengde paginatoewijzing te verifiëren, kunnen we de is_mixed_page_allocation_on opvragen kolom uit sys.databases DMV met een waarde als 0, wat een uniforme toewijzing van een uitgebreide pagina aangeeft, en een 1 om de toewijzing van een gemengde extensie aan te geven.
SELECT name, is_mixed_page_allocation_on
FROM sys.databases
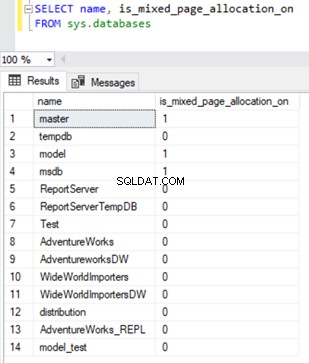
TempDB-gegevensbestanden groeien tot een enorme waarde en vereisen krimp TempDB
Als in SQL Server 2014 of eerdere versies de traceringsvlaggen 1117 en 1118 niet correct zijn geconfigureerd, samen met meerdere gegevensbestanden die zijn gemaakt voor de tempdb-database, zullen sommige van die bestanden onvermijdelijk enorm worden. Als dit gebeurt, probeert een DBA meestal de tempdb-gegevensbestanden te verkleinen. Maar het is een onjuiste aanpak om met dit scenario om te gaan.
Er zijn andere opties beschikbaar om de tempdb te verkleinen.
Laten we eens kijken naar de DBCC-opdrachten die beschikbaar zijn voor Shrink tempdb en de gevolgen van het uitvoeren van deze bewerkingen.
DBCC SRINKDATABASE
De DBCC SHRINKDATABASE console-opdracht werkt door het einde van de Data\Log-bestanden te verkleinen .
Om een database met succes te verkleinen, heeft de opdracht vrije ruimte nodig aan het einde van het bestand. Als er aan het einde van het bestand actieve transacties zijn, kunnen de databasebestanden niet worden verkleind.
De impact van het uitvoeren van DBCC SHRINKDATABASE is dat het zal proberen de beschikbare vrije ruimte aan het einde van elk gegevensbestand of logbestand vrij te maken dat mogelijk is gereserveerd voor toekomstige groei van tabelgegevens. Daarom kan het uitvoeren van deze opdracht resulteren in ongelijke bestandsgroottes, wat kan leiden tot problemen met tempdb-conflicten.
Syntaxis om een gebruikersdatabase te verkleinen, bijvoorbeeld de Adventureworks-database zou zijn
DBCC SHRINKDATABASE (AdventureWorks, TRUNCATEONLY);DBCC SHRINKFILE
Het DBCC SHRINKFILE console-opdracht werkt vergelijkbaar met DBCC SHRINKDATABASE, maar het verkleint de opgegeven databasegegevens of logbestanden .
Als u vaststelt dat een bepaald tempdb-gegevensbestand enorm is, kunnen we proberen dat specifieke item te verkleinen met DBCC SHRINKFILE, zoals hieronder wordt weergegeven.
Wees voorzichtig bij het gebruik van deze opdracht op tempdb, want als een bestand wordt verkleind tot een waarde die lager of hoger is dan andere gegevensbestanden, zal dat specifieke gegevensbestand niet effectief worden gebruikt. Of het zal vaker worden gebruikt, wat leidt tot problemen met de tempdb-conflicten.
Syntaxis om DBCC SHRINKFILE-bewerking uit te voeren op AdventureWorks-gegevensbestand tot 1 GB (1024 MB) zou zijn:
DBCC SHRINKFILE (AdventureWorks, 1024);
GO
DBCC DROPCLEANBUFFERS
De DBCC DROPCLEANBUFFERS console-opdracht wordt gebruikt om alle schone buffers uit de bufferpool en columnstore-objecten uit de columnstore-objectpool te wissen .
Voer eenvoudig het onderstaande commando uit:
DBCC DROPCLEANBUFFERSDBCC GRATIS PROCCACHE
De DBCC FREEPROCCACHE commando wist alle opgeslagen cache van het uitvoeringsplan voor procedures .
De Procedure Execution Plan Cache wordt door SQL Server gebruikt om dezelfde procedure-aanroepen sneller uit te voeren. Na het uitvoeren van de DBCC FREEPROCCACHE wordt de plancache gewist. SQL Server moet die cache dus opnieuw maken wanneer de opgeslagen procedure in de instantie wordt uitgevoerd. Het laat een ernstige negatieve impact achter wanneer het wordt uitgevoerd in de productie-DB-instanties.
Het wordt niet aanbevolen om DBCC FREEPROCCACHE uit te voeren op de productiedatabase-instantie!
De syntaxis om DBCC FREEPROCCACHE uit te voeren is hieronder:
DBCC FREEPROCCACHEDBCC FREESESSIONCACHE
De DBCC FREESESSIONCACHE opdracht wist de verbindingscache van de distributiequery uit de SQL Server-instantie . Het is handig als er veel gedistribueerde query's worden uitgevoerd op een bepaalde SQL Server-instantie.
De syntaxis om DBCC FREESESSIONCACHE uit te voeren zou zijn:
DBCC FREESESSIONCACHEDBCC FREESYSTEMCACHE
De DBCC FREESYSTEMCACHE opdracht wist alle ongebruikte cache-items uit alle cache . SQL Server doet dit standaard om meer geheugen beschikbaar te maken voor nieuwe bewerkingen. We kunnen het echter handmatig uitvoeren met het onderstaande commando:
DBCC FREESYSTEMCACHEZoals we weten, slaat tempdb alle tijdelijke gebruikersobjecten of interne objecten op, inclusief uitvoeringsplancache, bufferpoolgegevens, sessiecaches en systeemcaches. Daarom zal het uitvoeren van de bovenstaande 6 DBCC-opdrachten helpen bij het wissen van de tempdb-gegevensbestanden die het normale krimpproces voorkomen.
Ook al hebben we stappen doorlopen om tempdb via verschillende benaderingen te verkleinen, de aanbevolen best practices om met tempdb-database om te gaan, worden hieronder vermeld:
a. Start SQL Server Services indien mogelijk opnieuw om tempdb-gegevensbestanden gelijkmatig opnieuw te maken. Mogelijke impact zou zijn dat we alle uitvoeringsplannen en andere cache-informatie die hierboven zijn besproken, kwijtraken.
b. Laat tempdb-gegevensbestanden vooraf groeien tot een enorme bestandsgrootte die beschikbaar is in de schijf met tempdb-gegevensbestanden. Dit voorkomt dat SQL Server de bestandsgrootte ongelijkmatig vergroot in SQL Server-versies 2014 en eerder.
c. Als SQL Server Services niet opnieuw kan worden gestart vanwege RTO of RPO, probeer dan de bovenstaande DBCC-opdrachten nadat u de gevolgen duidelijk hebt begrepen.
d. Het verkleinen van de tempdb-database of gegevensbestanden is geen aanbevolen aanpak en doe dat daarom nooit in uw productieomgeving, tenzij er geen andere opties zijn.
Conclusie
We hebben meer geleerd over de interne aspecten van hoe tempdb werkt, zodat we tempdb kunnen configureren voor betere prestaties en zo conflictproblemen op tempdb kunnen voorkomen. We hebben ook de veelvoorkomende problemen in tempdb doorgenomen, maatregelen die beschikbaar zijn in SQL Server in verschillende versies en hoe dit efficiënt kan worden aangepakt. Daarnaast hebben we onderzocht waarom het verkleinen van de tempdb-database of gegevensbestanden geen aanbevolen aanpak is bij het omgaan met een tempdb-database.