Wat zijn unieke sleutelbeperkingen?
Een unieke beperking is een regel die kolominvoer beperkt tot uniek. Met andere woorden, dit soort beperkingen verhindert het invoegen van duplicaten in een kolom. Een unieke beperking is een van de instrumenten om de gegevensintegriteit in een SQL Server-database af te dwingen. Aangezien een tabel slechts één primaire sleutel kan hebben, kunt u een unieke beperking gebruiken om de uniciteit van een kolom of een combinatie van kolommen die geen primaire sleutel vormen, af te dwingen.
Door een unieke beperking voor een kolom te maken, wordt automatisch een unieke index gemaakt. Op deze manier implementeert SQL Server de integriteitseis van de unieke beperking. Daarom zal de database-engine, wanneer wordt geprobeerd een dubbele waarde in een kolom in te voegen waarop een unieke beperking is gedefinieerd, de schending van de unieke beperking detecteren en een overeenkomstige fout afgeven. Als gevolg hiervan wordt de rij met de dubbele waarden niet aan een tabel toegevoegd.
Een unieke beperking creëren
De volgende voorbeeldquery maakt de Studenten tabel en een unieke beperking op de Login kolom zodat er geen studenten zijn met dezelfde login.
CREATE TABLE Students ( Login CHAR NOT NULL ,CONSTRAINT AK_Student_Login UNIQUE (Login) ); GO
Als de leerlingen tabel al bestaat, kunt u de volgende voorbeeldquery gebruiken om de unieke beperking te maken.
ALTER TABLE Students ADD CONSTRAINT AK_Student_Login UNIQUE (Login); GO
Houd er rekening mee dat wanneer u een unieke beperking aan een bestaande tabel toevoegt, de database-engine controleert of de kolom waaraan de beperking wordt toegevoegd dubbele waarden bevat. Als er dergelijke waarden zijn, wordt de beperking niet toegevoegd en wordt er een fout gegenereerd.
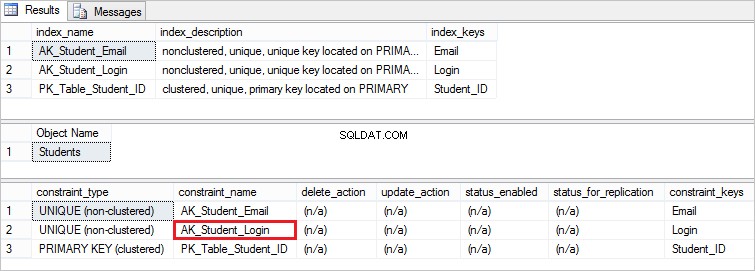
Voer nu de volgende instructies uit om te controleren of de unieke beperking daadwerkelijk is toegevoegd:
EXEC sp_helpindex Students EXEC sp_helpconstraint Students
Dit is de beperking die we hebben gemaakt:
Een unieke beperking creëren in SQL Server Management Studio
Laten we zeggen dat we een unieke beperking moeten definiëren voor de Login kolom het de Studenten tafel.
1. In de Objectverkenner , klik met de rechtermuisknop op de Studenten tabel en klik op Ontwerpen .
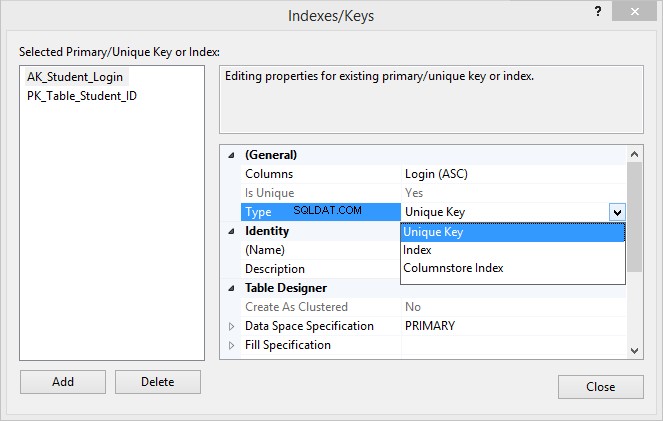
2. Klik met de rechtermuisknop op de Tabelontwerper en kies Indexen/Sleutels…
3. In de Indexen/Sleutels venster, klik op Toevoegen .
4. Onder de Algemeen sectie, klik op Kolommen en klik vervolgens op de knop met het weglatingsteken. In de Indexkolommen venster, selecteert u de kolom(men) die u in de unieke beperking wilt opnemen.
5. Onder de Algemeen sectie, klik op Type en selecteer Unieke sleutel uit de vervolgkeuzelijst.
6. Onder de Identiteit sectie, specificeer de naam van de beperking (in ons geval AK_Student_Login ) en klik op Sluiten om de nieuw gemaakte beperking op te slaan.
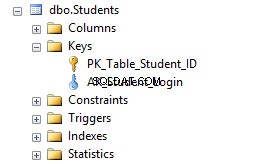
Als je nu naar de Studenten . gaat tabel in Objectverkenner en klik op de Indexen map, zult u zien dat de tabel een primaire sleutel en een unieke beperking bevat AK_Student_Login .
Hoe verschillen unieke beperkingen van primaire sleutels?
Net als bij een unieke beperking, wordt een primaire sleutel ook gebruikt om de gegevensintegriteit in een tabel af te dwingen. Maar het primaire doel van een primaire sleutel is om elk record in een tabel uniek te identificeren en de juiste relaties tussen tabellen in een database te implementeren. In 99% van de tabellen is een primaire sleutel vereist om correcte toegang tot tabelrijen mogelijk te maken. Er kan slechts één primaire sleutel per tabel gedefinieerd zijn op één of meer dan één kolom.
Unieke beperkingen worden specifiek gebruikt om te voorkomen dat dubbele waarden in een kolom worden ingevoegd. Er kunnen meerdere kolommen zijn met unieke beperkingen of er zijn helemaal geen unieke beperkingen gedefinieerd voor een tabel. Ze zijn niet verplicht voor een tabel in tegenstelling tot primaire sleutels.
Laten we zeggen dat we de Studenten . hebben tabel met persoonlijke informatie over elke student aan een universiteit. De tabel bevat de StudentID kolom die een primaire sleutel is en een unieke ID van elke specifieke student opslaat. Deze primaire sleutelkolom wordt gebruikt om elke student aan een universiteit op unieke wijze te identificeren.
Tegelijkertijd hebben de Studenten tabel heeft kolommen als E-mail , BSN , en Aanmelden en elk van deze kolommen moet unieke waarden bevatten. Aangezien er al één primaire sleutel in de tabel staat, zullen we in plaats daarvan unieke beperkingen gebruiken om deze kolommen uniek te maken. Een tabel kan dus veel unieke beperkingen hebben en slechts één primaire sleutel.
Een ander ding dat een unieke beperking van een primaire sleutel verschilt, is dat de primaire sleutel geen NULL toestaat waarden in een kolom, terwijl een kolom met een unieke beperking een NULL . kan bevatten waarde, maar slechts één omdat SQL Server twee NULL-waarden als dezelfde waarden interpreteert.
Stel dat er een unieke beperking wordt gemaakt op de E-mail kolom van de Studenten tafel. Laten we proberen om beide rijen in te voegen met NULL s in de E-mail velden:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17') GO
We krijgen de volgende foutmelding:

Welnu, dit is voorspelbaar gedrag, omdat dubbele waarden, zelfs als het NULL's zijn, niet zijn toegestaan door de unieke beperking.
Unieke beperking versus unieke index
Hoewel zowel de unieke beperking als de unieke index twee totaal verschillende niet-gerelateerde database-entiteiten zijn, hebben ze hetzelfde doel en dezelfde impact op de prestaties van SQL Server. Ze zorgen allebei voor uniekheid van gegevens in een kolom.
In tegenstelling tot de unieke index kunt u de opties IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX en STATISTICS_NORECOMPUTE echter niet specificeren voor de unieke beperking in de ALTER TABLE-instructies.
Wanneer u een unieke beperking voor een kolom maakt, maakt SQL Server automatisch een unieke index voor de kolom, dit is precies hoe deze functie is geïmplementeerd in SQL Server.
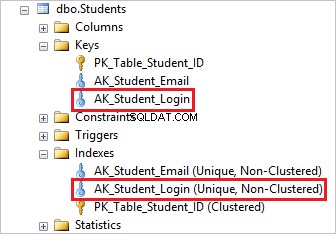
Om de unieke index te verwijderen, moet u eerst de bijbehorende unieke beperking laten vallen en dit zal automatisch de onderliggende unieke index verwijderen.
De volgende instructie zal de AK_Student_Login . laten vallen beperking:
ALTER TABLE Students DROP CONSTRAINT AK_Student_Login; GO
Je kunt zien dat het verwijderen van de AK_Student_Login unieke beperking verwijdert de bijbehorende index.
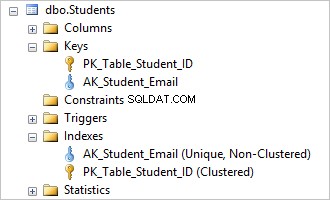
Dat was gemakkelijk, nu kunt u identieke waarden invoegen in de Login kolom.
Unieke beperking uitschakelen
Er is een optie die een unieke beperking uitschakelt. De volgende query zou alle tabelbeperkingen moeten uitschakelen:
ALTER TABLE Students NOCHECK CONSTRAINT ALL GO
Laten we, nadat we de query hebben uitgevoerd, proberen een duplicerend record in te voegen:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555') GO
Wat we krijgen is het unieke bericht over schending van beperkingen:

Het lijkt er dus op dat de ALTER TABLE
Onthoud echter dat er een unieke index is onder de motorkap van elke unieke beperking, en dat we een unieke index zouden moeten kunnen uitschakelen. In ons geval is de AK_Student_Email unieke beperking heeft de corresponderende AK_Student_Email . gemaakt unieke index op de E-mail kolom. Laten we de volgende query gebruiken om de AK_Student_Email . uit te schakelen unieke index eerst.
ALTER INDEX AK_Student_Email ON Students DISABLE;
De zoekopdracht is succesvol voltooid, dus laten we nu twee records invoegen met dubbele E-mail velden in de Studenten tafel.
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, 'example@sqldat.com', 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (4, 'James Marvin', 21, 'example@sqldat.com', 987-65-4321, 'Marvin_J17') GO
Het werkt! De records zijn in de tabel ingevoegd! Nu weten we hoe we dit probleem met "uitschakeling" kunnen omzeilen met een unieke beperking.
Gebruik de volgende query om de index in te schakelen:
ALTER INDEX AK_Student_Email ON Students REBUILD;
Conclusie
Dankzij unieke sleutelbeperkingen kunnen DBA's en SQL-ontwikkelaars de uniciteit van gegevens in tabelkolommen afdwingen en behouden, evenals bepaalde zakelijke vereisten voor gegevensintegriteit toepassen. In principe is er geen wezenlijk verschil in gedrag tussen een unieke beperking en een unieke index, behalve dat de unieke beperking niet direct kan worden uitgeschakeld en dat bepaalde opties voor het maken van indexen niet beschikbaar zijn voor unieke beperkingen in de ALTER TABLE-instructie.
Ik hoop dat dit artikel interessant was. U kunt vragen stellen, opmerkingen en suggesties over dit artikel achterlaten.
Zie ook: CONTROLEER beperkingen in SQL Server