In dit artikel zullen we het hebben over SQL Server Checkpoints.
Om de prestaties te verbeteren, past SQL Server wijzigingen toe op databasepagina's in het geheugen. Vaak wordt dit geheugen de buffercache of bufferpool genoemd. SQL Server spoelt deze pagina's niet na elke wijziging naar schijf. In plaats daarvan voert de database-engine van tijd tot tijd controlepuntbewerkingen uit op elke database. Het CHECKPOINT bewerking schrijft de vuile pagina's (huidige in-memory gewijzigde pagina's) en schrijft ook details over het transactielogboek.
SQL Server ondersteunt vier soorten controlepunten:
EXEC sp_configure 'recovery interval', 'seconds'
In het SIMPLE-herstelmodel wordt ook een automatisch controlepunt geactiveerd wanneer het transactielogboek voor 70% vol is.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Houd bij het instellen rekening met de mogelijkheden van het onderliggende I/O-subsysteem. Het kan zinvol zijn om dit lager in te stellen voor snellere I/O-subsystemen (bijv. SSD's). Wees voorzichtig, deze instelling blijft behouden via back-up en herstel, dus terugzetten naar langzamere hardware kan prestatieproblemen veroorzaken door te veel I/O-belasting te veroorzaken.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration is een geheel getal dat wordt gebruikt om de hoeveelheid tijd te definiëren waarin een controlepunt moet worden voltooid. Deze parameter bepaalt ook hoeveel resources worden toegewezen aan de controlepuntbewerking. Als de parameter niet is opgegeven, wordt het controlepunt voltooid in de tijd die de impact op de prestaties minimaliseert.
- Er is een gegevensbestand toegevoegd of verwijderd
- De database wordt afgesloten (om welke reden dan ook)
- Er wordt een back-up of database-snapshot gemaakt
- Er wordt een DBCC-opdracht uitgevoerd die een verborgen momentopname van de database maakt (of bijv. DBCC_CHECKDB, DBCC_CHECKTABLE).
Waarom zijn controlepunten nuttig?
Checkpoints verkorten de hersteltijd van een crash. Dit gebeurt omdat pagina's met gegevensbestanden niet tegelijk met de logboekrecords naar de schijf worden geschreven. Er zijn pagina's met gegevensbestanden in het geheugen die actueler zijn dan pagina's met gegevensbestanden op schijf.
Checkpoints verminderen I/O naar schijf en verbeteren de prestaties. De reden dat pagina's met gegevensbestanden niet naar schijf worden geschreven op het moment dat de transactie wordt vastgelegd, is om het aantal I/O-bewerkingen te verminderen. Stelt u zich de duizenden UPDATE-transacties voor op één enkele gegevenspagina. Het is efficiënter om een gegevenspagina slechts één keer naar de schijf te schrijven, tijdens een controlepunt, in plaats van na elke wijziging.
Schone en vuile pagina's
De bufferpool houdt een aantal gegevenspagina's in het geheugen bij. Er zijn twee soorten gegevenspagina's:schoon en vies . Een schone pagina is een pagina die niet is gewijzigd sinds deze voor het laatst van schijf is gelezen of naar schijf is geschreven. Een vuile pagina is een pagina die is gewijzigd en de wijzigingen zijn niet naar de schijf geschreven. Controlepunten verwijzen naar "vuile pagina's".
De informatie over de pagina kan worden bekeken met behulp van sys.dm_os_buffer_descriptors . Laten we eens kijken wat deze functie retourneert:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
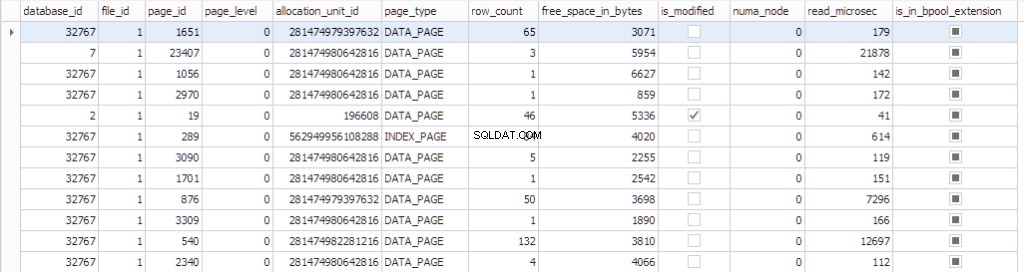
Elke pagina heeft een bijbehorende besturingsstructuur die de paginastatus bijhoudt:
- Een database met de datdabase_id 32767 is een alleen-lezen Resource Database die alle systeemobjecten bevat.
- file_id , page_id , allocation_unit_id die pagina behoort.
- Wat voor soort pagina het is:gegevenspagina of indexpagina.
- Het aantal rijen op de pagina.
- De vrije ruimte op de pagina
- Of de pagina nu vuil is of niet
- De numa_node waartoe de specifieke pagina behoort
- Enige informatie over het laatst gebruikte algoritme
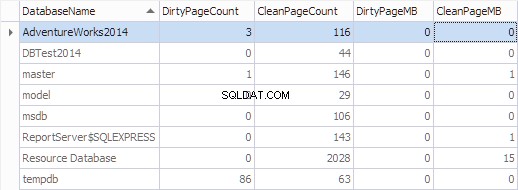
Laten we deze informatie per database samenvoegen met behulp van de volgende code:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Checkpoint-mechanisme
Wanneer het controlepunt plaatsvindt, worden alle vuile pagina's naar schijf geschreven. Pagina's die als vuil zijn gemarkeerd zodra ze wat zijn gewijzigd. Het maakt niet uit of de transactie die de wijziging heeft aangebracht, is vastgelegd of niet is vastgelegd op het moment van het controlepunt. Nadat de pagina's naar de schijf zijn geschreven, wordt het "vuile" bit gewist. Wanneer het controlepunt plaatsvindt, vinden de volgende acties plaats:
- Een nieuw logrecord geeft het begin van een checkpoint aan
- Aanvullende logboekrecords verschijnen met informatie over een controlepunt (zoals de status van het transactielogboek op het moment dat het controlepunt wordt gestart)
- Alle vuile pagina's worden naar schijf geschreven
- Markeer de LSN van het controlepunt op de opstartpagina van de database (in de dbi_checkptLSN), dit is essentieel voor herstel na crashes
- Als het EENVOUDIG herstelmodel wordt gebruikt, probeer dan het logboek te wissen
- Een laatste logrecord geeft aan dat het controlepunt klaar is
Het is mogelijk dat controlepunten van meerdere databases parallel plaatsvinden. De SQL Server 2000 was beperkt tot één controlepunt tegelijk. Wanneer de buffermanager een pagina schrijft, zoekt hij naar aangrenzende vuile pagina's die kunnen worden opgenomen in een enkele verzamel-schrijfbewerking. Ook gaat de bufferpool proberen ervoor te zorgen dat het I/O-subsysteem niet wordt overbelast. Het houdt bij hoe lang het duurt voordat I/O is voltooid. Als de schrijflatentie tijdens het controlepunt meer dan 20 ms bedraagt, wordt deze beperkt. Tijdens de uitschakeling wordt de smoordrempel verhoogd tot 100 ms. Een uitgebreidere uitleg vind je hier. U kunt de ongedocumenteerde opstartoptie "-kXX" gebruiken om de I/O-snelheid van het controlepunt in te stellen op XX MB/s.
Wanneer de gegevensbestandpagina door een controlepunt naar schijf wordt geschreven, garandeert write-ahead logging dat alle logrecords die van invloed zijn op die pagina eerst naar het transactielogboek op schijf moeten worden geschreven. Alle logrecords tot en met de laatste die de pagina beïnvloedden, worden weggeschreven, ongeacht van welke transactie ze deel uitmaken. Logrecords worden op drie manieren uitgeschreven:
- Als een transactie wordt vastgelegd of afgebroken
- Wanneer gegevensbestandspagina naar schijf wordt geschreven
- Wanneer een logblok de maximale grootte van 60 KB bereikt en geforceerd wordt beëindigd
Checkpoint-logrecord
Controlepunten schrijven meerdere logrecords in het transactielog:
- LOP_BEGIN_CKPT — geeft aan dat het controlepunt is begonnen
- LOP_XACT_CKPT met NULL-context (alleen als er niet-vastgelegde transacties zijn op het moment dat het controlepunt begon) — bevat een telling van het aantal niet-vastgelegde transacties. Het bevat ook de LSN's van de LOP_BEGIN_XACT-logboekrecords van de niet-vastgelegde transacties.
- LOP_BEGIN_CKPT met een context van LOP_BOOT_PAGE_CKPT (alleen SQL Server 2012) — geeft aan dat de opstartpagina is bijgewerkt.
- LOP_END_CKPT — betekent het einde van het controlepunt.
Checkpoint monitoring
Het kan handig zijn om controlepunten die optreden met pieken in I/O te correleren, zodat wijzigingen kunnen worden aangebracht in de specifieke database (voor het I/O-subsysteem) om de I/O-piek te verlichten als deze het I/O-subsysteem overbelast. Bijvoorbeeld meer frequente, handmatige checkpoints doen, of een lager herstelinterval configureren op SQL Server 2012 met indirecte checkpoints. Dit zorgt voor een meer constante I/O-belasting zonder hoge pieken die het I/O-subsysteem overbelasten. De hoofdoorzaak kan echter zijn dat er meer I/O wordt uitgevoerd vanwege een verandering ergens, dus accepteer niet zomaar een plotselinge toename van checkpoint-activiteit zonder te onderzoeken waarom het heeft plaatsgevonden.
De Buffer Manager/Checkpoint-pagina's/sec-teller is niet database-specifiek, dus om te bepalen welke database erbij betrokken is, zijn traceringsvlaggen of uitgebreide gebeurtenissen vereist.
Traceervlag 3502 schrijft berichten naar het foutenlogboek over welk databasecontrolepunt plaatsvindt.
Traceervlag 3504 schrijft meer gedetailleerde informatie over het aantal pagina's dat is weggeschreven en de gemiddelde latentie bij het schrijven.
Deze traceervlaggen zijn veilig te gebruiken in de productie voor een beperkte limoen. Het enige wat ze doen is berichten in het foutenlogboek afdrukken.
Als u uitgebreide gebeurtenissen wilt gebruiken, zijn er twee gebeurtenissen die u kunt gebruiken:checkpoint_begin en checkpoint_end.
Samenvatting
In dit artikel hebben we het gehad over controlepunten in SQL Server - het belangrijkste mechanisme voor het schrijven van pagina's met gegevensbestanden naar schijf nadat ze zijn gewijzigd.