Tabelindexeringsstrategie is een van de belangrijkste sleutels voor het afstemmen en optimaliseren van prestaties. In SQL Server worden de indexen (zowel geclusterd als niet-geclusterd) gemaakt met behulp van een B-boomstructuur, waarin elke pagina fungeert als een dubbel gekoppelde lijstknooppunt, met informatie over de vorige en de volgende pagina's. Deze B-boomstructuur, Forward Scan genaamd, maakt het gemakkelijker om de rijen uit de index te lezen door de pagina's van het begin tot het einde te scannen of te zoeken. Hoewel de voorwaartse scan de standaard en algemeen bekende methode voor het scannen van indexen is, biedt SQL Server ons de mogelijkheid om de indexrijen binnen de B-boomstructuur van het einde tot het begin te scannen. Deze vaardigheid wordt de Backward Scan genoemd. In dit artikel zullen we zien hoe dit gebeurt en wat de voor- en nadelen zijn van de Achterwaartse scanmethode.
SQL Server biedt ons de mogelijkheid om gegevens uit de tabelindex te lezen door de index B-boomstructuurknooppunten van het begin tot het einde te scannen met behulp van de Forward Scan-methode, of de B-boomstructuurknooppunten van het einde naar het begin te lezen met behulp van de Achterwaartse scanmethode. Zoals de naam aangeeft, wordt de achterwaartse scan uitgevoerd terwijl de volgorde van de kolom in de index wordt gelezen, die wordt uitgevoerd met de optie DESC in de sorteerinstructie ORDER BY T-SQL, die de richting van de scanbewerking aangeeft.
In specifieke situaties constateert SQL Server Engine dat het lezen van de indexgegevens van het einde naar het begin met de Backward scan-methode sneller is dan het lezen in de normale volgorde met de Forward scan-methode, wat een duur sorteerproces door de SQL kan vereisen Motor. Dergelijke gevallen omvatten het gebruik van de MAX()-aggregatiefunctie en situaties waarin het sorteren van het queryresultaat tegengesteld is aan de indexvolgorde. Het belangrijkste nadeel van de Backward scan-methode is dat de SQL Server Query Optimizer er altijd voor zal kiezen om het uit te voeren met seriële planuitvoering, zonder voordeel te kunnen halen uit de parallelle uitvoeringsplannen.
Stel dat we de volgende tabel hebben met informatie over de werknemers van het bedrijf. De tabel kan worden gemaakt met behulp van de onderstaande CREATE TABLE T-SQL-instructie:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Nadat we de tabel hebben gemaakt, vullen we deze met 10.000 dummy-records, met behulp van de onderstaande INSERT-instructie:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Als we de onderstaande SELECT-instructie uitvoeren om gegevens op te halen uit de eerder gemaakte tabel, worden de rijen gesorteerd volgens de ID-kolomwaarden in oplopende volgorde, dat is hetzelfde als de geclusterde indexvolgorde:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Vervolgens wordt het uitvoeringsplan voor die query gecontroleerd en wordt een scan uitgevoerd op de geclusterde index om de gesorteerde gegevens uit de index te halen, zoals weergegeven in het onderstaande uitvoeringsplan:
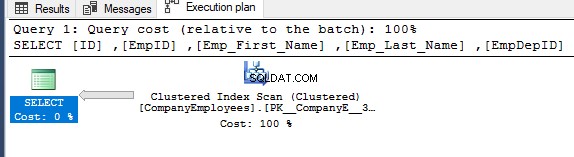
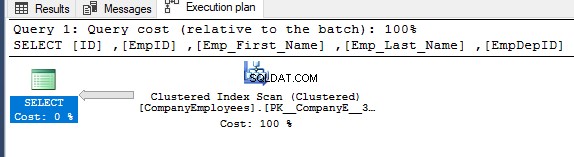
Om de richting van de scan te krijgen die wordt uitgevoerd op de geclusterde index, klikt u met de rechtermuisknop op het indexscanknooppunt om door de knooppunteigenschappen te bladeren. Van de eigenschappen van het knooppunt Clustered Index Scan, geeft de eigenschap Scan Direction de richting weer van de scan die wordt uitgevoerd op de index binnen die query, namelijk Forward Scan, zoals weergegeven in de onderstaande snapshot:
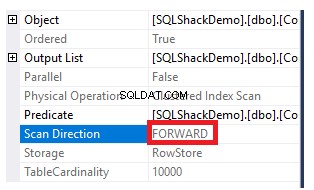
De scanrichting van de index kan ook worden opgehaald uit het XML-uitvoeringsplan van de eigenschap ScanDirection onder de IndexScan-node, zoals hieronder weergegeven:

Stel dat we de maximale ID-waarde moeten ophalen uit de CompanyEmployees-tabel die eerder is gemaakt, met behulp van de onderstaande T-SQL-query:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Bekijk vervolgens het uitvoeringsplan dat wordt gegenereerd door het uitvoeren van die query. U zult zien dat er een scan zal worden uitgevoerd op de geclusterde index zoals weergegeven in het onderstaande uitvoeringsplan:
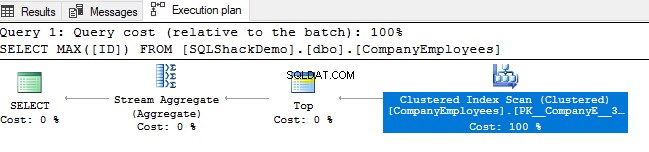
Om de richting van de indexscan te controleren, bladeren we door de eigenschappen van het knooppunt Clustered Index Scan. Het resultaat zal ons laten zien dat de SQL Server Engine de voorkeur geeft aan het scannen van de geclusterde index van het einde naar het begin, wat in dit geval sneller zal zijn, om de maximale waarde van de ID-kolom te krijgen, vanwege het feit dat de index is al gesorteerd volgens de ID-kolom, zoals hieronder weergegeven:
Als we ook proberen de eerder gemaakte tabelgegevens op te halen met de volgende SELECT-instructie, worden de records gesorteerd volgens de ID-kolomwaarden, maar deze keer, in tegenstelling tot de geclusterde indexvolgorde, door de DESC-sorteeroptie op te geven in de ORDER BY-clausule hieronder weergegeven:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
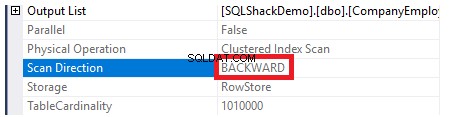
Als u het uitvoeringsplan controleert dat is gegenereerd na het uitvoeren van de vorige SELECT-query, ziet u dat er een scan wordt uitgevoerd op de geclusterde index om de gevraagde records van de tabel te krijgen, zoals hieronder weergegeven:
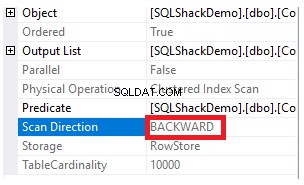
De eigenschappen van het knooppunt Clustered Index Scan laten zien dat de richting van de scan die de SQL Server Engine het liefst volgt, de richting Backward Scan is, die in dit geval sneller is, omdat de gegevens worden gesorteerd tegengesteld aan de echte sortering van de geclusterde index. rekening houdend met het feit dat de index al in oplopende volgorde is gesorteerd volgens de ID-kolom, zoals hieronder weergegeven:
Prestatievergelijking
Stel dat we de onderstaande SELECT-statements hebben die informatie ophalen over alle medewerkers die vanaf 2010 zijn aangenomen, twee keer; de eerste keer dat de geretourneerde resultatenset in oplopende volgorde wordt gesorteerd volgens de ID-kolomwaarden, en de tweede keer dat de geretourneerde resultaatset in aflopende volgorde wordt gesorteerd volgens de ID-kolomwaarden met behulp van de onderstaande T-SQL-instructies:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
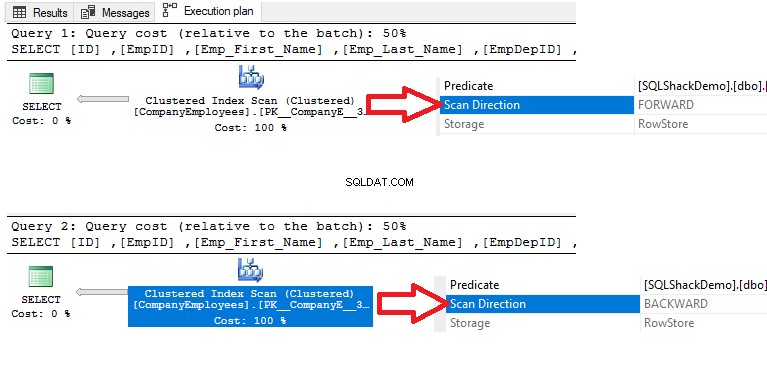
Door de uitvoeringsplannen te controleren die worden gegenereerd door het uitvoeren van de twee SELECT-query's, zal het resultaat laten zien dat er een scan wordt uitgevoerd op de geclusterde index in de twee query's om de gegevens op te halen, maar de richting van de scan in de eerste query is Forward Scan vanwege de ASC-gegevenssortering en Achterwaartse scan in de tweede query vanwege het gebruik van DESC-gegevenssortering, om de noodzaak om de gegevens opnieuw te ordenen te vervangen, zoals hieronder weergegeven:
Als we de IO- en TIME-uitvoeringsstatistieken van de twee query's controleren, zullen we ook zien dat beide query's dezelfde IO-bewerkingen uitvoeren en bijna waarden van de uitvoering en CPU-tijd verbruiken.
Deze waarden laten ons zien hoe slim de SQL Server Engine is bij het kiezen van de meest geschikte en snelste indexscanrichting om gegevens voor de gebruiker op te halen, namelijk Forward Scan in het eerste geval en Backward Scan in het tweede geval, zoals blijkt uit de onderstaande statistieken :

Laten we het vorige MAX-voorbeeld nog eens bekijken. Stel dat we het maximale ID moeten ophalen van de werknemers die in 2010 en later zijn aangenomen. Hiervoor zullen we de volgende SELECT-instructies gebruiken die de gelezen gegevens sorteren op basis van de ID-kolomwaarde met de ASC-sortering in de eerste query en met de DESC-sortering in de tweede query:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
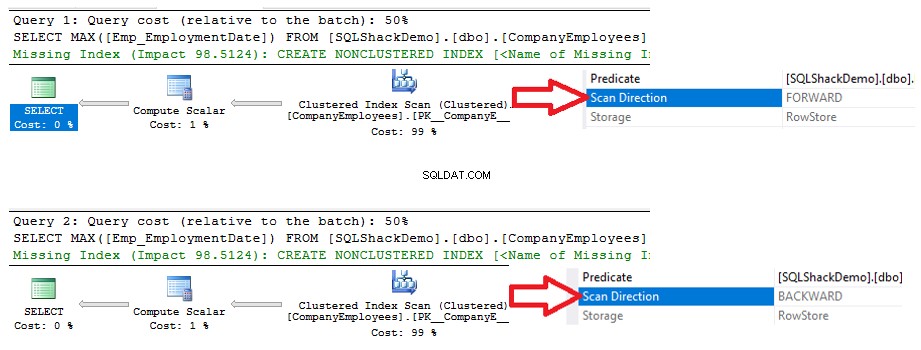
U zult aan de uitvoeringsplannen zien die zijn gegenereerd door de uitvoering van de twee SELECT-instructies, dat beide query's een scanbewerking zullen uitvoeren op de geclusterde index om de maximale ID-waarde op te halen, maar in verschillende scanrichtingen; Voorwaartse scan in de eerste vraag en Achterwaartse scan in de tweede vraag, vanwege de ASC- en DESC-sorteeropties, zoals hieronder weergegeven:
De IO-statistieken die door de twee query's worden gegenereerd, laten geen verschil zien tussen de twee scanrichtingen. Maar de TIME-statistieken laten een groot verschil zien tussen het berekenen van de maximale ID van de rijen wanneer deze rijen van het begin tot het einde worden gescand met de Forward Scan-methode en het scannen van het einde naar het begin met de Backward Scan-methode. Uit het onderstaande resultaat blijkt duidelijk dat de Backward Scan-methode de optimale scanmethode is om de maximale ID-waarde te krijgen:
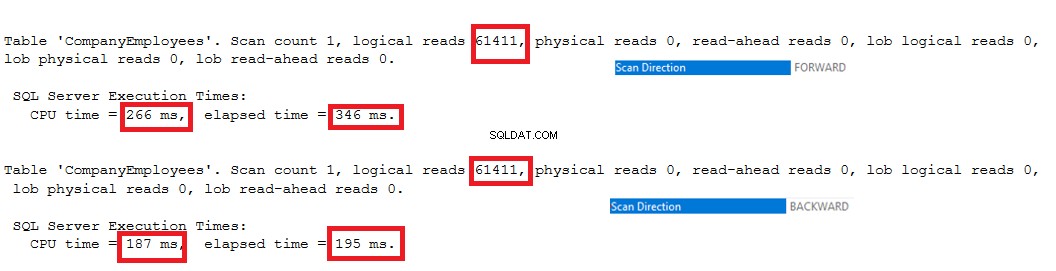
Prestatieoptimalisatie
Zoals ik aan het begin van dit artikel al zei, is het indexeren van query's de belangrijkste sleutel in het prestatieafstemmings- en optimalisatieproces. Als we in de vorige vraag een niet-geclusterde index willen toevoegen aan de EmploymentDate-kolom van de CompanyEmployees-tabel, met behulp van de onderstaande CREATE INDEX T-SQL-instructie:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Als u de uitvoeringsplannen controleert die zijn gegenereerd na het uitvoeren van de twee zoekopdrachten, zult u zien dat er een zoekopdracht wordt uitgevoerd op de nieuw gemaakte niet-geclusterde index, en beide zoekopdrachten zullen de index van het begin tot het einde scannen met behulp van de Forward Scan-methode, zonder dat dit nodig is. om een Backward Scan uit te voeren om het ophalen van gegevens te versnellen, hoewel we de DESC-sorteeroptie in de tweede query hebben gebruikt. Dit gebeurde doordat de index rechtstreeks werd gezocht zonder de noodzaak om een volledige indexscan uit te voeren, zoals te zien is in de onderstaande vergelijking van uitvoeringsplannen:
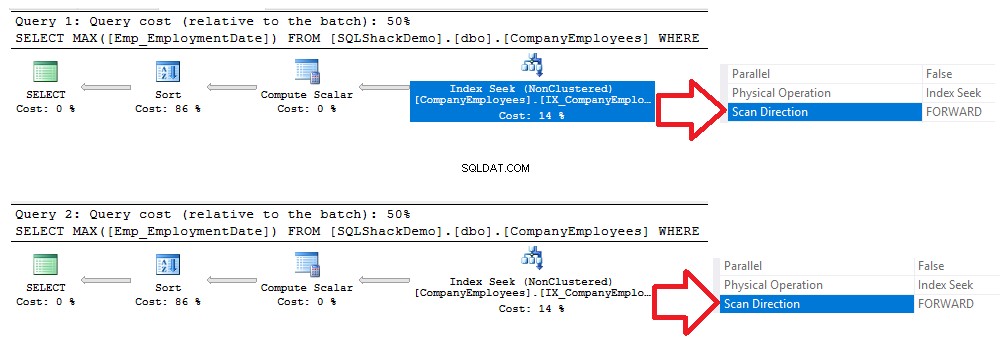
Hetzelfde resultaat kan worden afgeleid uit de IO- en TIME-statistieken die zijn gegenereerd op basis van de vorige twee query's, waarbij de twee query's dezelfde hoeveelheid uitvoeringstijd, CPU- en IO-bewerkingen zullen verbruiken, met een zeer klein verschil, zoals weergegeven in de statistische momentopname hieronder :

Nuttige links:
- Geclusterde en niet-geclusterde indexen beschreven
- Niet-geclusterde indexen maken
- SQL Server Performance Tuning:achterwaarts scannen van een index
Handig hulpmiddel:
dbForge Index Manager – handige SSMS-invoegtoepassing voor het analyseren van de status van SQL-indexen en het oplossen van problemen met indexfragmentatie.