Gebruikt u SQL-subquery's of vermijdt u deze?
Stel dat de chief credit and collections officer u vraagt om de namen van mensen, hun onbetaalde saldo per maand en het huidige lopende saldo op te sommen en wil dat u deze gegevensarray in Excel importeert. Het doel is om de gegevens te analyseren en met een aanbod te komen dat betalingen lichter maakt om de effecten van de COVID19-pandemie te verzachten.
Kies je ervoor om een query en een geneste subquery of een join te gebruiken? Welke beslissing ga je nemen?
SQL-subquery's – wat zijn dat?
Waarom zou u niet eerst een subquery definiëren voordat we dieper ingaan op syntaxis, prestatie-impact en voorbehouden?
In de eenvoudigste bewoordingen is een subquery een query binnen een query. Terwijl een query die een subquery belichaamt de buitenste query is, verwijzen we naar een subquery als de inner query of inner select. En haakjes omsluiten een subquery die lijkt op de onderstaande structuur:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)We gaan in dit bericht naar de volgende punten kijken:
- SQL-subquerysyntaxis afhankelijk van verschillende subquerytypen en operators.
- Wanneer en in wat voor soort uitspraken kan men een subquery gebruiken.
- Prestatie-implicaties vs. JOINs .
- Veelvoorkomende waarschuwingen bij het gebruik van SQL-subquery's.
Zoals gebruikelijk geven we voorbeelden en illustraties om het begrip te vergroten. Maar houd er rekening mee dat de belangrijkste focus van dit bericht ligt op subquery's in SQL Server.
Laten we nu beginnen.
Maak SQL-subquery's die op zichzelf staan of gecorreleerd zijn
Om te beginnen worden subquery's gecategoriseerd op basis van hun afhankelijkheid van de buitenste query.
Laat me beschrijven wat een op zichzelf staande subquery is.
Op zichzelf staande subquery's (of soms niet-gecorreleerde of eenvoudige subquery's genoemd) zijn onafhankelijk van de tabellen in de buitenste query. Laat me dit illustreren:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Zoals aangetoond in de bovenstaande code, heeft de subquery (tussen haakjes hieronder) geen verwijzingen naar een kolom in de buitenste query. Bovendien kunt u de subquery in SQL Server Management Studio markeren en uitvoeren zonder runtime-fouten te krijgen.
Wat op zijn beurt leidt tot eenvoudiger debuggen van op zichzelf staande subquery's.
Het volgende dat u moet overwegen, zijn gecorreleerde subquery's. In vergelijking met zijn op zichzelf staande tegenhanger, heeft deze ten minste één kolom waarnaar wordt verwezen vanuit de buitenste query. Ter verduidelijking zal ik een voorbeeld geven:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Was u aandachtig genoeg om de verwijzing naar BusinessEntityID . op te merken? van de Persoon tafel? Goed gedaan!
Zodra er in de subquery naar een kolom uit de buitenste query wordt verwezen, wordt het een gecorreleerde subquery. Nog een punt om te overwegen:als u een subquery markeert en uitvoert, zal er een fout optreden.
En ja, je hebt helemaal gelijk:dit maakt gecorreleerde subquery's behoorlijk moeilijker te debuggen.
Volg deze stappen om foutopsporing mogelijk te maken:
- de subquery isoleren.
- vervang de verwijzing naar de buitenste query door een constante waarde.
Door de subquery te isoleren voor foutopsporing ziet het er als volgt uit:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Laten we nu wat dieper ingaan op de uitvoer van subquery's.
Maak SQL-subquery's met 3 mogelijke geretourneerde waarden
Laten we eerst eens kijken welke geretourneerde waarden we kunnen verwachten van SQL-subquery's.
In feite zijn er 3 mogelijke uitkomsten:
- Een enkele waarde
- Meerdere waarden
- Hele tabellen
Enkele waarde
Laten we beginnen met uitvoer met één waarde. Dit type subquery kan overal in de buitenste query verschijnen waar een expressie wordt verwacht, zoals de WHERE clausule.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Wanneer u een MAX . gebruikt () functie, haalt u een enkele waarde op. Dat is precies wat er gebeurde met onze subquery hierboven. De gelijke gebruiken (= ) operator vertelt SQL Server dat u een enkele waarde verwacht. Nog iets:als de subquery meerdere waarden retourneert met behulp van de gelijken (= ) operator, krijg je een fout, vergelijkbaar met die hieronder:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Meerdere waarden
Vervolgens onderzoeken we de meerwaardige output. Dit soort subquery's retourneert een lijst met waarden met een enkele kolom. Bovendien zijn operators zoals IN en NIET IN zal een of meer waarden verwachten.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Volledige tabelwaarden
En last but not least, waarom zou u zich niet verdiepen in de output van hele tabellen.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Is het je opgevallen dat de FROM clausule?
In plaats van een tabel te gebruiken, werd een subquery gebruikt. Dit wordt een afgeleide tabel of een tabelsubquery genoemd.
En nu wil ik u enkele basisregels presenteren bij het gebruik van dit soort zoekopdrachten:
- Alle kolommen in de subquery moeten unieke namen hebben. Net als een fysieke tabel, moet een afgeleide tabel unieke kolomnamen hebben.
- BESTEL DOOR is niet toegestaan tenzij TOP staat ook vermeld. Dat komt omdat de afgeleide tabel een relationele tabel vertegenwoordigt waarin rijen geen gedefinieerde volgorde hebben.
In dit geval heeft een afgeleide tabel de voordelen van een fysieke tabel. Daarom kunnen we in ons voorbeeld COUNT . gebruiken () in een van de kolommen van de afgeleide tabel.
Dat is ongeveer alles met betrekking tot subquery-uitvoer. Maar voordat we verder gaan, is het je misschien opgevallen dat de logica achter het voorbeeld voor meerdere waarden en andere ook kan worden gedaan met een JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'In feite zal de output hetzelfde zijn. Maar welke presteert beter?
Voordat we daarop ingaan, wil ik je vertellen dat ik een sectie heb gewijd aan dit populaire onderwerp. We bekijken het met volledige uitvoeringsplannen en bekijken illustraties.
Heb dus even geduld met mij. Laten we een andere manier bespreken om uw subquery's te plaatsen.
Andere uitspraken waar u SQL-subquery's kunt gebruiken
Tot nu toe hebben we SQL-subquery's gebruikt op SELECT verklaringen. En het punt is dat u kunt profiteren van de voordelen van subquery's op INSERT , UPDATE , en VERWIJDEREN -statements of in een T-SQL-statement dat een expressie vormt.
Laten we dus nog een aantal voorbeelden bekijken.
SQL-subquery's gebruiken in UPDATE-statements
Het is eenvoudig genoeg om subquery's op te nemen in UPDATE verklaringen. Waarom bekijkt u dit voorbeeld niet eens?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOHeb je gezien wat we daar deden?
Het punt is dat je subquery's kunt plaatsen in de WHERE clausule van een UPDATE verklaring.
Omdat we het in het voorbeeld niet hebben, kun je ook een subquery gebruiken voor de SET clausule zoals SET kolom =(subquery) . Maar wees gewaarschuwd:het zou een enkele waarde moeten weergeven omdat er anders een fout optreedt.
Wat doen we daarna?
SQL-subquery's gebruiken in INSERT-instructies
Zoals u al weet, kunt u records in een tabel invoegen met een SELECT uitspraak. Ik weet zeker dat je een idee hebt van wat de subquerystructuur zal zijn, maar laten we dit demonstreren met een voorbeeld:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Dus, waar kijken we hier naar?
- De eerste subquery haalt het laatste salaristarief van een werknemer op voordat de extra 10 wordt toegevoegd.
- De tweede subquery haalt het laatste salarisrecord van de werknemer op.
- Ten slotte het resultaat van de SELECT wordt ingevoegd in de EmployeePayHistory tafel.
In andere T-SQL-statements
Afgezien van SELECTEER , INSERT , UPDATE , en VERWIJDEREN , kunt u ook SQL-subquery's gebruiken in het volgende:
Variabele declaraties of SET-instructies in opgeslagen procedures en functies
Laat me dit verduidelijken aan de hand van dit voorbeeld:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)U kunt dit ook op de volgende manier doen:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)In voorwaardelijke expressies
Kijk eens naar dit voorbeeld:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDAfgezien daarvan kunnen we het als volgt doen:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDSQL-subquery's maken met vergelijking of logische operators
Tot nu toe hebben we de gelijken gezien (= )-operator en de IN-operator. Maar er valt nog veel meer te ontdekken.
Vergelijkingsoperatoren gebruiken
Wanneer een vergelijkingsoperator zoals =, <,>, <>,>=of <=wordt gebruikt met een subquery, moet de subquery één waarde retourneren. Bovendien treedt er een fout op als de subquery meerdere waarden retourneert.
Het onderstaande voorbeeld genereert een runtime-fout.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Weet jij wat er mis is in de bovenstaande code?
Allereerst gebruikt de code de operator equals (=) bij de subquery. Bovendien retourneert de subquery een lijst met startdatums.
Om het probleem op te lossen, laat de subquery een functie gebruiken zoals MAX () in de startdatumkolom om een enkele waarde te retourneren.
Logische operators gebruiken
EXISTS of NOT EXISTS gebruiken
BESTAAT retourneert TRUE als de subquery rijen retourneert. Anders retourneert het FALSE . Ondertussen, met behulp van NIET BESTAAT retourneert TRUE als er geen rijen zijn en FALSE , anders.
Beschouw het onderstaande voorbeeld:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDSta me toe het eerst toe te lichten. De bovenstaande code laat de tabeltoken vallen als deze wordt gevonden in sys.tables , wat betekent dat het in de database bestaat. Nog een punt:de verwijzing naar de kolomnaam is niet relevant.
Waarom is dat?
Het blijkt dat de database-engine slechts ten minste 1 rij hoeft te krijgen met behulp van EXISTS . Als in ons voorbeeld de subquery een rij retourneert, wordt de tabel verwijderd. Aan de andere kant, als de subquery geen enkele rij heeft geretourneerd, worden de volgende instructies niet uitgevoerd.
Dus de zorg van BESTAAT zijn alleen rijen en geen kolommen.
Bovendien, BESTAAT gebruikt tweewaardige logica:TRUE of FALSE . Er zijn geen gevallen dat het NULL zal retourneren . Hetzelfde gebeurt wanneer je EXISTS negeert met behulp van NIET .
IN of NIET IN gebruiken
Een subquery geïntroduceerd met IN of NIET IN retourneert een lijst met nul of meer waarden. En in tegenstelling tot EXISTS , is een geldige kolom met het juiste gegevenstype vereist.
Laat me dit verduidelijken met een ander voorbeeld:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Zoals je aan de bovenstaande code kunt zien, zijn beide IN en NIET IN operators worden geïntroduceerd. En in beide gevallen worden rijen geretourneerd. Elke rij in de buitenste zoekopdracht wordt vergeleken met het resultaat van elke subquery om een product te krijgen dat voorhanden is en een product dat niet van leverancier 1676 is.
Nesten van SQL-subquery's
U kunt subquery's zelfs tot 32 niveaus nesten. Desalniettemin hangt deze mogelijkheid af van het beschikbare geheugen van de server en de complexiteit van andere expressies in de query.
Wat is uw mening hierover?
In mijn ervaring kan ik me niet herinneren dat ik tot 4 heb genest. Ik gebruik zelden 2 of 3 niveaus. Maar dat zijn alleen ik en mijn vereisten.
Wat dacht je van een goed voorbeeld om dit uit te zoeken:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Zoals we in dit voorbeeld kunnen zien, bereikte het nesten 2 niveaus.
Zijn SQL-subquery's slecht voor de prestaties?
Kortom:ja en nee. Met andere woorden, het hangt ervan af.
En vergeet niet, dit is in de context van SQL Server.
Om te beginnen kunnen veel T-SQL-instructies die subquery's gebruiken, ook worden herschreven met JOIN s. En de prestaties voor beide zijn meestal hetzelfde. Desondanks zijn er bepaalde gevallen waarin een join sneller is. En er zijn gevallen waarin de subquery sneller werkt.
Voorbeeld 1
Laten we een voorbeeld van een subquery bekijken. Druk voordat je ze uitvoert op Control-M of schakel Include Actual Execution Plan in van de werkbalk van SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Als alternatief kan de bovenstaande query worden herschreven met een join die hetzelfde resultaat oplevert.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Uiteindelijk is het resultaat voor beide zoekopdrachten 200 rijen.
Daarnaast kunt u het uitvoeringsplan voor beide verklaringen bekijken.
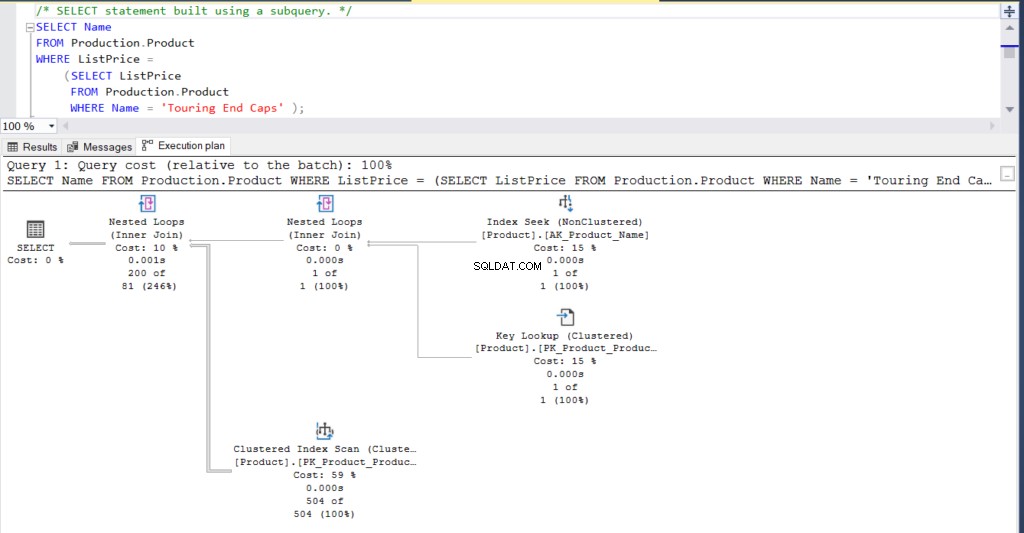
Figuur 1:Uitvoeringsplan met behulp van een subquery
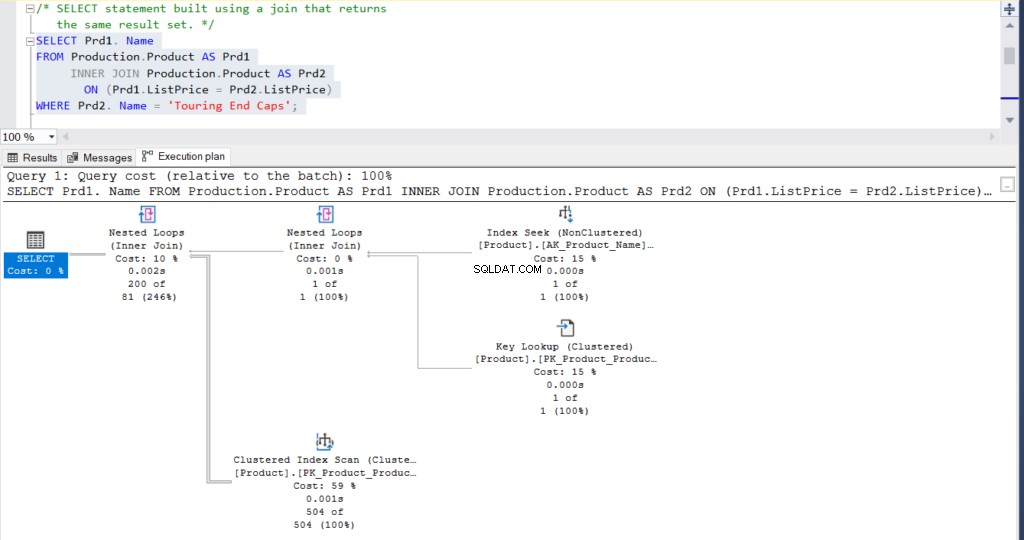
Figuur 2:Uitvoeringsplan met behulp van een Join
Wat denk je? Zijn ze praktisch hetzelfde? Behalve de werkelijk verstreken tijd van elk knooppunt, is al het andere in principe hetzelfde.
Maar hier is nog een andere manier om het te vergelijken, afgezien van visuele verschillen. Ik raad aan om het Vergelijk Showplan . te gebruiken .
Volg deze stappen om het uit te voeren:
- Klik met de rechtermuisknop op het uitvoeringsplan van de instructie met behulp van de subquery.
- Selecteer Uitvoeringsplan opslaan als .
- Noem het bestand subquery-execution-plan.sqlplan .
- Ga naar het uitvoeringsplan van het statement met een join en klik er met de rechtermuisknop op.
- Selecteer Vergelijk Showplan .
- Selecteer de bestandsnaam die je in #3 hebt opgeslagen.
Bekijk dit nu voor meer informatie over Vergelijk Showplan .
Je zou zoiets als dit moeten kunnen zien:
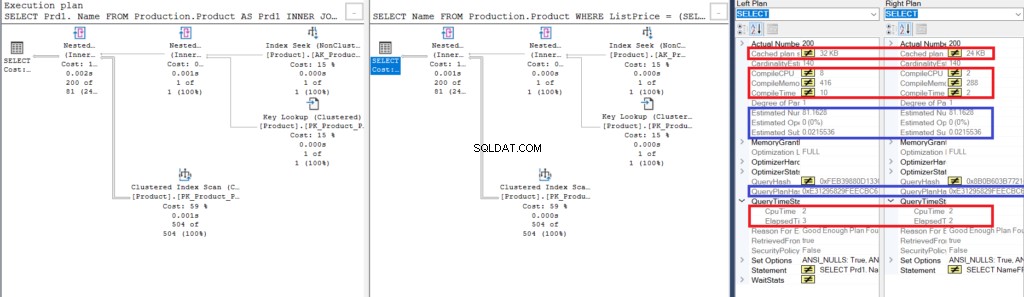
Figuur 3:Vergelijk Showplan voor het gebruik van een join versus het gebruik van een subquery
Let op de overeenkomsten:
- Geschatte rijen en kosten zijn hetzelfde.
- QueryPlanHash is ook hetzelfde, wat betekent dat ze vergelijkbare uitvoeringsplannen hebben.
Let desalniettemin op de verschillen:
- De grootte van het cacheplan is groter bij gebruik van de join dan bij gebruik van de subquery
- Compile CPU en tijd (in ms), inclusief het geheugen in KB, gebruikt om het uitvoeringsplan te ontleden, binden en optimaliseren is hoger bij gebruik van de join dan bij gebruik van de subquery
- CPU-tijd en verstreken tijd (in ms) om het plan uit te voeren is iets hoger bij gebruik van de join versus de subquery
In dit voorbeeld is de subquery een tic sneller dan de join, ook al zijn de resulterende rijen hetzelfde.
Voorbeeld 2
In het vorige voorbeeld gebruikten we slechts één tabel. In het volgende voorbeeld gaan we 3 verschillende tabellen gebruiken.
Laten we dit laten gebeuren:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Beide zoekopdrachten leveren dezelfde 3806 rijen op.
Laten we vervolgens eens kijken naar hun uitvoeringsplannen:
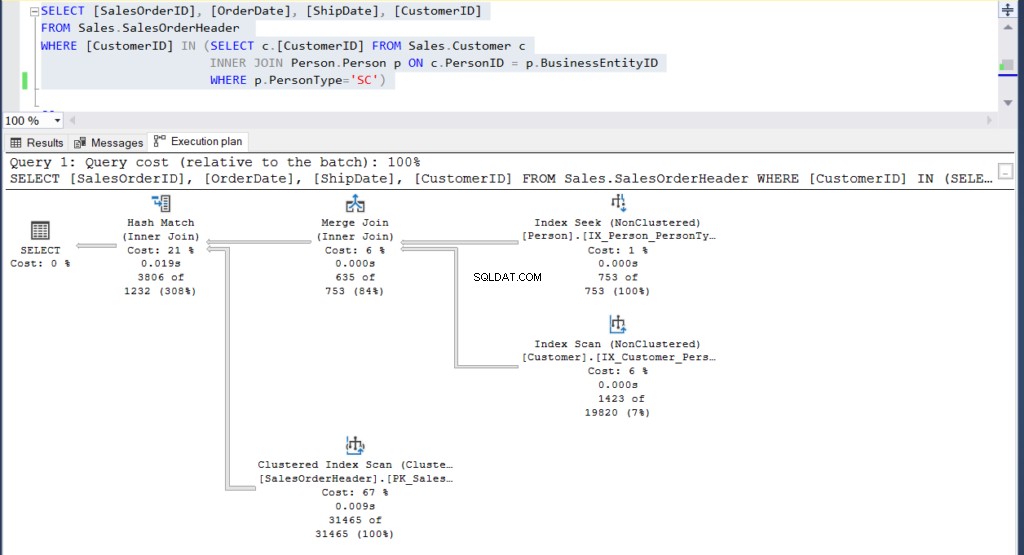
Figuur 4:Uitvoeringsplan voor ons tweede voorbeeld met een subquery
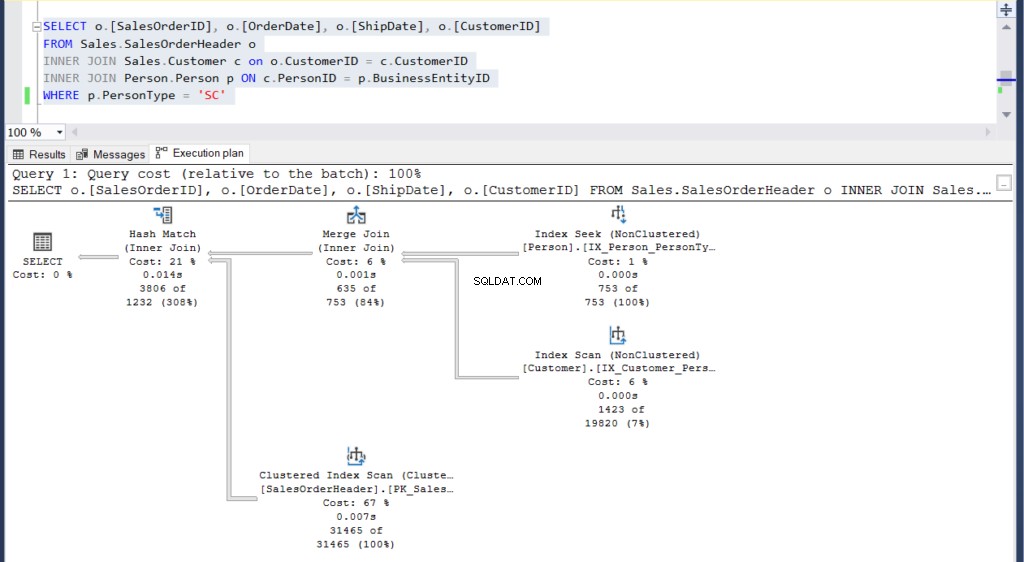
Figuur 5:Uitvoeringsplan voor ons tweede voorbeeld met een join
Kun je de 2 uitvoeringsplannen zien en enig verschil ertussen vinden? In één oogopslag zien ze er hetzelfde uit.
Maar een zorgvuldiger onderzoek met het Vergelijk Showplan onthult wat er echt in zit.
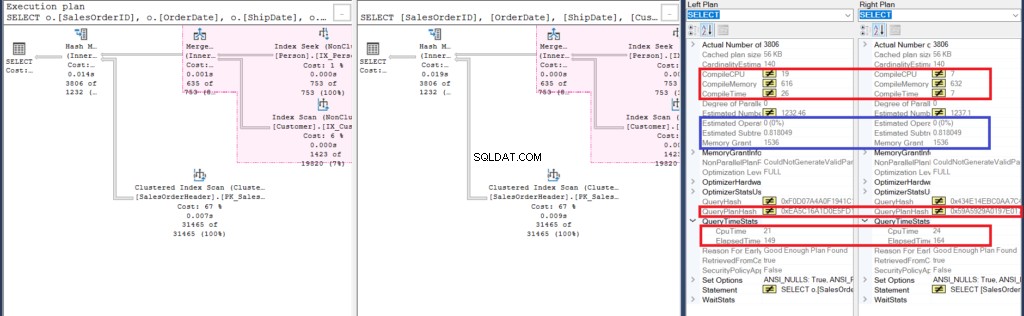
Figuur 6:Details van Compare Showplan voor het tweede voorbeeld
Laten we beginnen met het analyseren van een paar overeenkomsten:
- De roze markering in het uitvoeringsplan onthult vergelijkbare bewerkingen voor beide zoekopdrachten. Aangezien de inner query een join gebruikt in plaats van subquery's te nesten, is dit heel begrijpelijk.
- De geschatte kosten voor operator en substructuur zijn hetzelfde.
Laten we vervolgens eens kijken naar de verschillen:
- Ten eerste duurde de compilatie langer toen we joins gebruikten. U kunt dat controleren in de Compile CPU en Compile Time. De query met een subquery vergde echter een hoger compileergeheugen in KB.
- De QueryPlanHash van beide query's is dan anders, wat betekent dat ze een ander uitvoeringsplan hebben.
- Ten slotte zijn de verstreken tijd en CPU-tijd om het plan uit te voeren sneller met de join dan het gebruik van een subquery.
Subquery versus deelnemen aan prestatieafhaal
U zult waarschijnlijk te veel andere query-gerelateerde problemen tegenkomen die kunnen worden opgelost door een join of een subquery te gebruiken.
Maar het komt erop neer dat een subquery niet inherent slecht is in vergelijking met joins. En er is geen vuistregel dat in een bepaalde situatie een join beter is dan een subquery of andersom.
Controleer dus de uitvoeringsplannen om er zeker van te zijn dat u de beste keuze heeft. Het doel daarvan is om inzicht te krijgen in hoe SQL Server een bepaalde query zal verwerken.
Als u er echter voor kiest om een subquery te gebruiken, houd er dan rekening mee dat er problemen kunnen ontstaan die uw vaardigheden op de proef stellen.
Algemene kanttekeningen bij het gebruik van SQL-subquery's
Er zijn 2 veelvoorkomende problemen die ervoor kunnen zorgen dat uw zoekopdrachten zich wild gedragen bij het gebruik van SQL-subquery's.
De pijn van kolomnaamresolutie
Dit probleem introduceert logische fouten in uw zoekopdrachten en ze kunnen erg lastig te vinden zijn. Een voorbeeld kan dit probleem verder verduidelijken.
Laten we beginnen met het maken van een tabel voor demo-doeleinden en deze te vullen met gegevens.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GONu de tabel is ingesteld, laten we er enkele subquery's mee starten. Maar onthoud voordat u de onderstaande query uitvoert dat de leveranciers-ID's die we uit de vorige code hebben gebruikt, beginnen met '14'.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)De bovenstaande code wordt zonder fouten uitgevoerd, zoals u hieronder kunt zien. Let in ieder geval op de lijst met BusinessEntityID's .
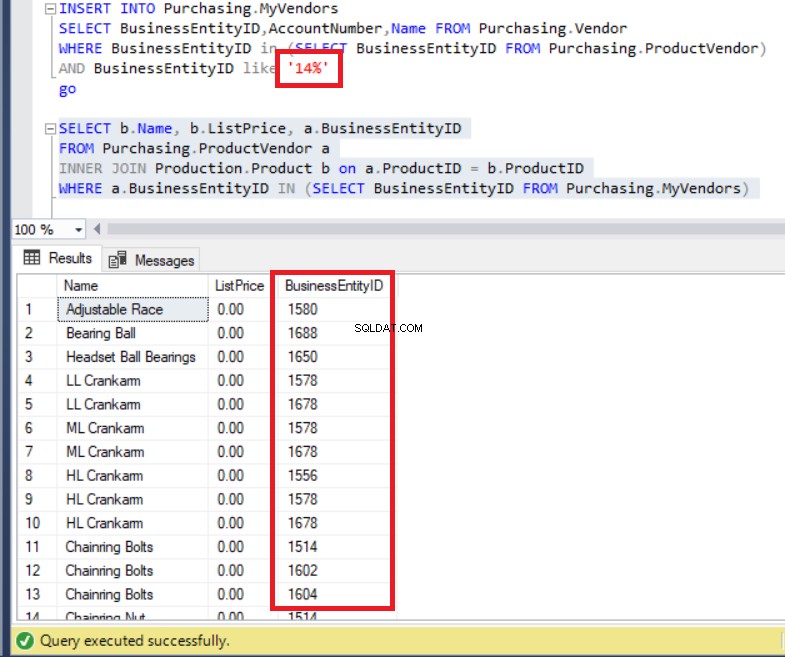
Figuur 7:BusinessEntityID's van de resultatenset komen niet overeen met de records van de tabel MyVendors
Hebben we geen gegevens ingevoerd met BusinessEntityID beginnend met ’14’? Wat is er dan aan de hand? We kunnen zelfs BusinessEntityIDs . zien die beginnen met ’15’ en ’16’. Waar komen deze vandaan?
In feite vermeldde de zoekopdracht alle gegevens van ProductVendor tafel.
In dat geval zou je kunnen denken dat een alias dit probleem zal oplossen, zodat het zal verwijzen naar Mijn leveranciers tabel zoals hieronder:
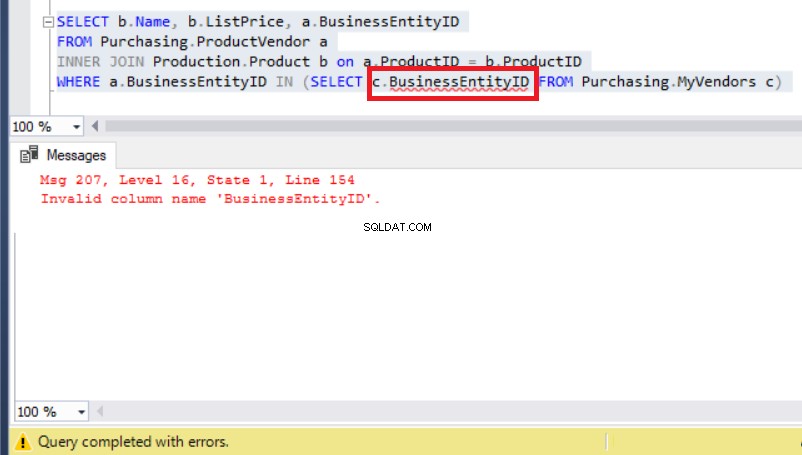
Figuur 8:Een alias toevoegen aan de BusinessEntityID resulteert in een fout
Behalve dat nu het echte probleem opdook vanwege een runtime-fout.
Controleer de Mijn leveranciers tabel opnieuw en u zult dat zien in plaats van BusinessEntityID , moet de kolomnaam BusinessEntity_id . zijn (met een onderstrepingsteken).
Als u dus de juiste kolomnaam gebruikt, wordt dit probleem uiteindelijk opgelost, zoals u hieronder kunt zien:
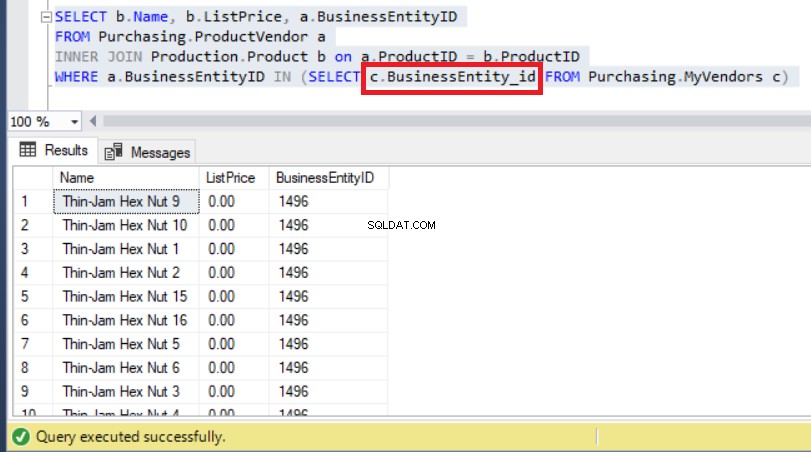
Figuur 9:Het wijzigen van de subquery met de juiste kolomnaam loste het probleem op
Zoals u hierboven kunt zien, kunnen we nu BusinessEntityID's . waarnemen beginnend met '14' zoals we eerder hadden verwacht.
Maar je vraagt je misschien af: waarom heeft SQL Server het überhaupt toegestaan om de query met succes uit te voeren?
Hier is de kicker:de resolutie van kolomnamen zonder alias werkt in de context van de subquery van op zichzelf naar de buitenste query. Daarom is de verwijzing naar BusinessEntityID binnen de subquery heeft geen fout veroorzaakt omdat deze buiten de subquery wordt gevonden - in de ProductVendor tafel.
Met andere woorden, SQL Server zoekt naar de niet-gealiaste kolom BusinessEntityID in Mijn leveranciers tafel. Omdat het er niet is, keek het naar buiten en vond het in de ProductVendor tafel. Gek, nietwaar?
Je zou kunnen zeggen dat dit een bug is in SQL Server, maar eigenlijk is het zo ontworpen in de SQL-standaard en Microsoft volgde het.
Ok, dat is duidelijk, we kunnen niets aan de standaard doen, maar hoe kunnen we voorkomen dat we een fout tegenkomen?
- Voeg eerst de kolomnamen toe aan de tabelnaam of gebruik een alias. Met andere woorden, vermijd tabelnamen zonder prefix of zonder aliassen.
- Ten tweede, zorg voor een consistente naamgeving van kolommen. Vermijd beide BusinessEntityID en BusinessEntity_id , bijvoorbeeld.
Klinkt goed? Ja, dit brengt wat gezond verstand in de situatie.
Maar dit is niet het einde ervan.
Gekke NULL's
Zoals ik al zei, er is meer te dekken. T-SQL gebruikt driewaardige logica vanwege de ondersteuning voor NULL . En NULL kan ons bijna gek maken als we SQL-subquery's gebruiken met NOT IN .
Laat ik beginnen met dit voorbeeld te introduceren:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)De uitvoer van de zoekopdracht leidt ons naar een lijst met producten die niet in Mijn leveranciers staan tabel., zoals hieronder te zien:
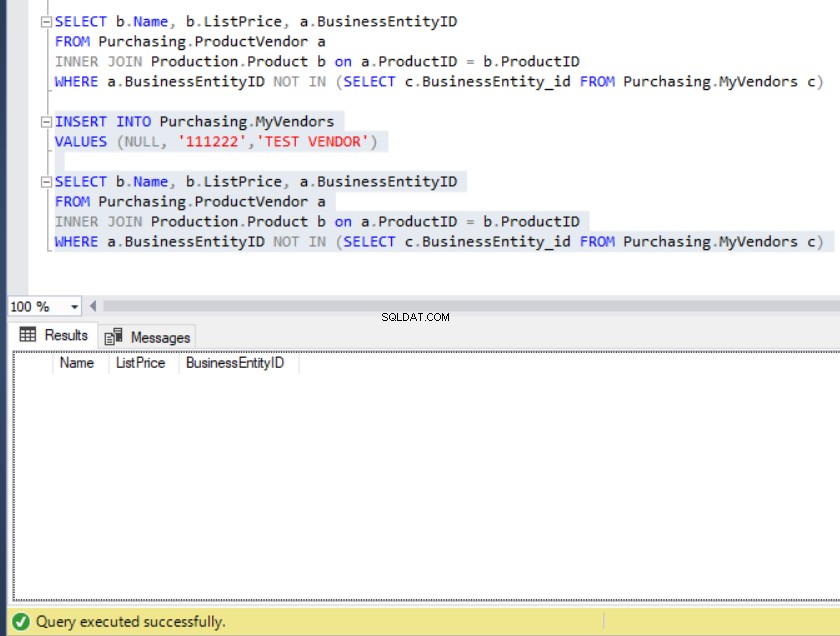
Figuur 10:De uitvoer van de voorbeeldquery met NOT IN
Stel nu dat iemand onbedoeld een record heeft ingevoegd in de Mijn leveranciers tabel met een NULL BusinessEntity_id . Wat gaan we daaraan doen?
Figuur 11:De resultatenset wordt leeg wanneer een NULL BusinessEntity_id wordt ingevoegd in MyVendors
Waar zijn alle gegevens gebleven?
Zie je, de NIET operator negeerde de IN predikaat. Dus NIET WAAR wordt nu FALSE . Maar NIET NULL is onbekend. Dat zorgde ervoor dat het filter de rijen weggooide die ONBEKEND zijn, en dit is de boosdoener.
Om ervoor te zorgen dat dit jou niet overkomt:
- Zorg ervoor dat de tabelkolom NULL's niet toestaat als gegevens niet zo zouden moeten zijn.
- Of voeg de column_name toe IS NOT NULL naar je WAAR clausule. In ons geval is de subquery als volgt:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Afhaalmaaltijden
We hebben vrij veel gesproken over subquery's en het is tijd om de belangrijkste punten van dit bericht te geven in de vorm van een samengevatte lijst:
Een subquery:
- is een zoekopdracht binnen een zoekopdracht.
- staat tussen haakjes.
- kan een uitdrukking overal vervangen.
- kan worden gebruikt in SELECT , INSERT , UPDATE , VERWIJDEREN, of andere T-SQL-statements.
- kan op zichzelf staan of gecorreleerd zijn.
- voert enkele, meerdere of tabelwaarden uit.
- werkt op vergelijkingsoperatoren zoals =, <>,>, <,>=, <=en logische operatoren zoals IN /NIET IN en BESTAAT /BESCHIKT NIET .
- is niet slecht of slecht. Het kan beter of slechter presteren dan DOEN s afhankelijk van een situatie. Dus volg mijn advies en controleer altijd de uitvoeringsplannen.
- kan vervelend gedrag vertonen op NULL s bij gebruik met NIET IN , en wanneer een kolom niet expliciet wordt geïdentificeerd met een tabel of tabelalias.
Get familiarized with several additional references for your reading pleasure:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators