SQL 2017 introduceerde de mogelijkheid om bewerkingen voor het opnieuw opbouwen van de index te pauzeren en te hervatten tijdens database-onderhoud. Deze functie biedt databasebeheerders meer flexibiliteit, omdat ze kunnen kiezen tussen offline en online opnieuw indexeren, samen met het pauzeren en hervatten van het opnieuw opbouwen van de index wanneer dat nodig is.
Vóór de release van de hervatbare index konden databasebeheerders de index opnieuw opbouwen offline en online .
Offline biedt snellere uitvoering, omdat de tabel is vergrendeld voor elke lees of schrijf bewerking, en de nieuwe index is opgebouwd uit de oude index. Tijdens dit proces is geen lees- of schrijfbewerking toegestaan. Wanneer de bewerking is voltooid, wordt de tafelvergrendeling vrijgegeven en zijn lees- en schrijfbewerkingen weer toegestaan. De Offline optie is natuurlijk sneller.
Online houdt de tafel open voor lezen en schrijf activiteiten. Er is nog een kopie van de index gemaakt en alle bewerkingen voor het opnieuw opbouwen van de index bevinden zich in die kopie. Alle nieuwe rijbewerkingen worden naar beide indexen geschreven. Wanneer het opnieuw opbouwen is voltooid, is de omschakeling voltooid en wordt de nieuwe indexkopie in gebruik genomen. De Online rebuild maakt het mogelijk om opnieuw te bouwen terwijl de database online is. De uitvaltijd is minimaal.
Houd er rekening mee dat de hervatbare indexfunctie alleen beschikbaar is in de SQL Server Enterprise-editie en de gratis Developer-editie. Als je deze optie op tafel hebt, kun je ermee spelen, een eenvoudige test doen en kijken of deze functie in jouw geval nuttig is.
De Microsoft-documentatie vermeldt de volgende aspecten voor uw overwegingen:
- U kunt onderhoudsperiodes voor indexen beheren, plannen en uitbreiden. U kunt de bewerkingen voor het maken of opnieuw opbouwen van een index pauzeren en opnieuw starten wanneer u uw onderhoudsvensters moet aanpassen.
- U kunt fouten bij het maken of opnieuw opbouwen van de index herstellen (zoals databasefailovers of onvoldoende schijfruimte).
- Let erop dat wanneer een indexbewerking wordt gepauzeerd, zowel de oorspronkelijke index als de nieuw aangemaakte schijfruimte nodig heeft. U moet ze bijwerken tijdens de DML-bewerkingen.
- U kunt het afkappen van transactielogboeken inschakelen tijdens het maken of opnieuw opbouwen van de index.
- Merk op dat de SORT_IN_TEMPDB=ON optie niet wordt ondersteund
Laten we de hervatting van de hervatbare index testen. Ik zal een containerafbeelding gebruiken met de SQL 2019 Server Developer-editie. Ik zal ook een kleine tabel maken met slechts een paar kolommen en ongeveer een miljoen rijen in die tabel invoegen. Je kunt de tafel groter maken met meer rijen.
Omdat ik een Linux-machine gebruik en SQL Server Management Studio niet kan installeren, gebruik ik de Azure Data Studio-client om verbinding te maken met mijn SQL Server. Bekijk de schermafbeelding van mijn SQL Server-eigenschappen:
We zullen een voorbeelddatabase, een tabel en een index maken met de onderstaande T-SQL-scripts. Je kunt ze feilloos uitvoeren met SSMS of dbForge Studio voor SQL Server:
-- Create a new database called 'DatabaseName'
-- Connect to the 'master' database to run this snippet
USE master
GO
-- Create the new database if it does not exist already
IF NOT EXISTS (
SELECT [name]
FROM sys.databases
WHERE [name] = N'dbatools'
)
CREATE DATABASE dbatools
GO
Use dbatools
-- Create a new table called '[TableName]' in schema '[dbo]'
-- Drop the table if it already exists
IF OBJECT_ID('[dbo].[TabletoIndex]', 'U') IS NOT NULL
DROP TABLE [dbo].[TabletoIndex]
GO
-- Create the table in the specified schema
CREATE TABLE [dbo].[TabletoIndex]
(
[Id] INT NOT NULL PRIMARY KEY, -- Primary Key column
[ColumnName1] NVARCHAR(50) NOT NULL
-- Specify more columns here
);
GO
Voer het onderstaande script uit om de tabel te vullen met willekeurige gegevens:
--populate the table
SET NOCOUNT ON
Declare @Id int
Set @Id = 1
While @Id <= 1000000
Begin
Insert Into TabletoIndex values (@Id, 'Name - ' + CAST(@Id as nvarchar(10))) Set @Id = @Id + 1
End
SELECT count(*) from TabletoIndex
Met een gevulde tabel klaar, kunnen we doorgaan naar de hervatbare index. Laten we beginnen met het maken van die index:
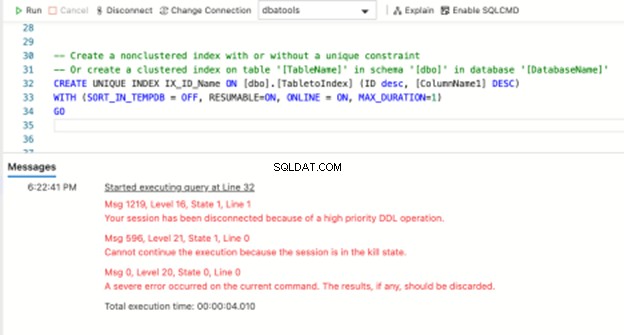
-- Create a nonclustered index with or without a unique constraint -- Or create a clustered index on table '[TableName]' in schema '[dbo]' in database '[DatabaseName]'
CREATE UNIQUE INDEX IX_ID_Name ON [dbo].[TabletoIndex] (ID desc, [ColumnName1] DESC) WITH (SORT_IN_TEMPDB = OFF, RESUMABLE=ON, ONLINE = ON, MAX_DURATION=1) GO
Let op nieuwe opties/parameters in de bovenstaande opdracht. RESUMABLE=AAN betekent dat we een hervatbare indexbewerking willen hebben. Max_Duur is de waarde in minuten die bepaalt hoe lang we willen dat indexeren wordt uitgevoerd.
Terwijl de bovenstaande opdracht wordt uitgevoerd, opent u een andere sessie en voert u de onderstaande T-SQL-opdracht uit om PAUSE de lopende herbouwactiviteit:
--Rebuild WITH RESUMABLE functionality
ALTER INDEX IX_ID_Name ON [dbo].[TabletoIndex] PAUSE
GO
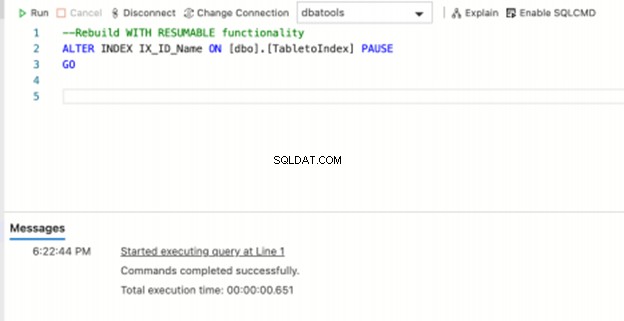
Als de PAUZE opdracht succesvol is, pauzeren we de huidige indexeringsbewerking die ongeveer een minuut geleden is gestart. Wanneer u echter teruggaat naar de vorige sessie voor het rebuild-commando met resumable=ON , het geeft een lelijke fout terug. Ugh. Maar ja, dat is het verwachte gedrag.
Met deze hervatting van de hervatbare index introduceerde SQL Server ook een nieuwe DMV sys.index_resumable_operations om gepauzeerde bewerkingen te controleren. Laten we eens kijken naar deze DMV:
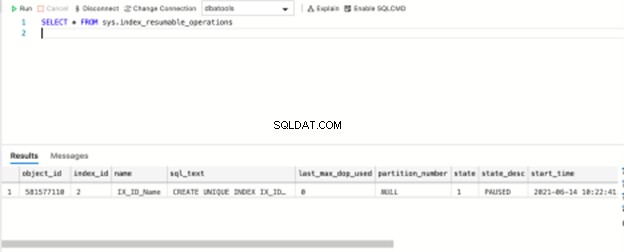
De DMV-resultaatquery retourneert mijn opdracht voor het opnieuw opbouwen van de index, het voltooide percentage is geweldig, en meer. Wanneer al uw index-reconstructiebewerkingen zijn voltooid, retourneert DMV leeg:
Best netjes, hè?
Maar wat als u van gedachten verandert over de tafel? Wat als er een wijziging in de vereisten is en u wijzigingen moet aanbrengen in het databaseontwerp? Laten we proberen de tafel te laten vallen:
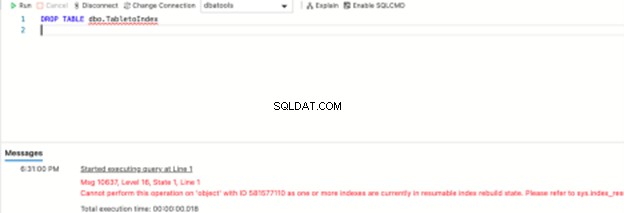
Het geeft weer een lelijke, lange foutmelding:
Bericht 10637, niveau 16, staat 1, regel 1
Kan deze bewerking niet uitvoeren op 'object' met ID 581577110 omdat een of meer indexen zich momenteel in de hervatbare status voor het opnieuw opbouwen van de index bevinden. Raadpleeg sys.index_resumable_operations voor meer informatie.
Totale uitvoeringstijd:00:00:00.018
Vanaf hier zul je je realiseren dat je geen andere keuze hebt dan de operatie volledig AF TE BREKEN of TE HERvatten en het opnieuw opbouwen te laten voltooien.
Zie het T-SQL-commando om de bewerking te hervatten of af te breken. Dan kun je de tafel succesvol laten vallen:
ALTER INDEX IX_ID_Name ON [dbo].[TabletoIndex] RESUME
ALTER INDEX IX_ID_Name ON [dbo].[TabletoIndex] ABORT
Dezelfde fout zal ook optreden als u andere bewerkingen moet uitvoeren, zoals het volledig laten vallen van de index of het beëindigen van de huidige sessie.
Maar je vraagt je af, is de hervatbare optie in de eerste plaats? Het antwoord is nee. Voor SQL 2019 is het maken van alle indexen standaard met RESUMABLE=ON. Het is vanwege deze 2 scope-statements:
ALTER DATABASE SCOPED CONFIGURATION SET ELEVATE_ONLINE=WHEN_SUPPORTED ALTER DATABASE SCOPED CONFIGURATION SET ELEVATE_RESUMABLE=WHEN_SUPPORTED Samenvatting
De impact van het gebruik van de hervatbare optie op de prestaties is niet anders dan het gebruik van de normale herindexbewerking. SQL Server geeft u gewoon meer controle over uw database-onderhoudsactiviteiten.
Wat betreft de vereisten voor het opnieuw opbouwen van de periodieke tabelindex, is het nog steeds het beste om indexbewerkingen offline uit te voeren, of in ieder geval tijdens de daluren om een minimale zakelijke impact te garanderen.