Voor alle belangrijke RDBMS-producten geldt Primaire sleutel in SQL-beperkingen heeft een cruciale rol. Ze identificeren de records die in een tabel aanwezig zijn op unieke wijze. Daarom moeten we de Primary Keys-server zorgvuldig kiezen tijdens het tafelontwerp om de prestaties te verbeteren.
In dit artikel zullen we leren wat een primaire sleutelbeperking is. We zullen ook zien hoe u beperkingen voor primaire sleutels kunt maken, wijzigen of verwijderen.
SQL Server-beperkingen
In SQL Server, Beperkingen zijn regels die het invoeren van de gegevens in de benodigde kolommen regelen. Beperkingen dwingen de nauwkeurigheid van gegevens af en hoe die gegevens overeenkomen met zakelijke vereisten. Ook maken ze de gegevens betrouwbaar voor eindgebruikers. Daarom is het van cruciaal belang om de juiste beperkingen te identificeren tijdens de ontwerpfase van het database- of tabelschema.
SQL Server ondersteunt de volgende Constraint-types om gegevensintegriteit af te dwingen:
Primaire sleutelbeperkingen worden gemaakt op een enkele kolom of een combinatie van kolommen om de uniciteit van records af te dwingen en de records sneller te identificeren. De betrokken kolommen mogen geen NULL-waarden bevatten. Daarom moet de eigenschap NOT NULL op de kolommen worden gedefinieerd.
Buitenlandse belangrijke beperkingen worden gemaakt op een enkele kolom of een combinatie van kolommen om een relatie tussen twee tabellen te creëren en de gegevens in de ene tabel naar de andere af te dwingen. Idealiter verwijzen tabelkolommen waar we de gegevens moeten afdwingen met beperkingen voor externe sleutels naar de brontabel met een primaire sleutel in SQL of een unieke sleutelbeperking. Met andere woorden, alleen de records die beschikbaar zijn in de primaire of unieke sleutelbeperkingen van de brontabel kunnen worden ingevoegd of bijgewerkt in de doeltabel.
Unieke belangrijke beperkingen worden gemaakt op een enkele kolom of een combinatie van kolommen om de uniciteit van de kolomgegevens af te dwingen. Ze zijn vergelijkbaar met de Primary Key-beperkingen met een enkele wijziging. Het verschil tussen primaire sleutel en unieke sleutelbeperkingen is dat de laatste kan worden gemaakt op Nullable kolommen en laat één NULL-waarderecord toe in zijn kolom.
Beperkingen controleren worden gemaakt op een enkele kolom of een combinatie van kolommen door de geaccepteerde gegevenswaarden voor de betrokken kolommen te beperken via een logische expressie. Er is een verschil tussen Foreign Key en Check Constraints. De externe sleutel dwingt de gegevensintegriteit af door gegevens uit de primaire of unieke sleutel van een andere tabel te controleren. De Check Constraint doet dit echter door een logische uitdrukking te gebruiken.
Laten we nu de primaire sleutelbeperkingen doornemen.
Primaire sleutelbeperking
Primaire sleutelbeperking dwingt uniciteit af op een enkele kolom of combinatie van kolommen zonder NULL-waarden binnen de betrokken kolommen.
Om uniciteit af te dwingen, maakt SQL Server een unieke geclusterde index op de kolommen waar de primaire sleutels zijn gemaakt. Als er bestaande geclusterde indexen zijn, maakt SQL Server een unieke niet-geclusterde index op de tabel voor de primaire sleutel.
Laten we eens kijken hoe we primaire sleutels op een tafel maken, wijzigen, neerzetten, uitschakelen of inschakelen met behulp van T-SQL-scripts.
Maak een primaire sleutel
We kunnen primaire sleutels op een tafel maken tijdens het maken van de tabel of daarna. De syntaxis varieert enigszins voor deze scenario's.
Aanmaken van de primaire sleutel tijdens het maken van de tabel
De syntaxis is hieronder:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Laten we een tabel maken met de naam Werknemers in de HumanResources schema voor testdoeleinden met het onderstaande script:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
We hebben met succes de HumanResources.Employees . gemaakt tafel op de AdventureWorks databank:
We kunnen zien dat de geclusterde index is gemaakt in de tabel die overeenkomt met de naam van de primaire sleutel, zoals hierboven gemarkeerd.
Laten we de tabel laten vallen met behulp van het onderstaande script en het opnieuw proberen met de nieuwe syntaxis.
DROP TABLE HumanResources.EmployeesDe primaire sleutel in SQL maken op een tabel met de door de gebruiker gedefinieerde naam van de primaire sleutel PK_Employees , gebruik de onderstaande syntaxis:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
We hebben de HumanResources.Employees . gemaakt tabel met de naam van de primaire sleutel PK_Employees :
Aanmaken van de primaire sleutel na het maken van de tabel
Soms vergeten ontwikkelaars of DBA's de primaire sleutels en maken ze tabellen zonder deze. Maar het is mogelijk om een primaire sleutel te maken op bestaande tabellen.
Laten we de HumanResources.Employees . laten vallen tabel en maak deze opnieuw met het onderstaande script:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Wanneer u dit script met succes uitvoert, kunnen we de HumanResources.Employees zien tabel gemaakt zonder primaire sleutels of indexen:

Een primaire sleutel maken met de naam PK_Employees gebruik in deze tabel de onderstaande syntaxis:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Uitvoering van dit script creëert de primaire sleutel op onze tafel:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Aanmaken van primaire sleutels op meerdere kolommen
In onze voorbeelden hebben we primaire sleutels gemaakt op enkele kolommen. Als we primaire sleutels op meerdere kolommen willen maken, hebben we een andere syntaxis nodig.
Om meerdere kolommen toe te voegen als onderdeel van de primaire sleutel, hoeven we alleen door komma's gescheiden waarden toe te voegen van de kolomnamen die deel moeten uitmaken van de primaire sleutel.
Primaire sleutel tijdens het maken van de tabel
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Primaire sleutel na het maken van de tabel
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Laat de primaire sleutel vallen
Om de primaire sleutel te verwijderen, gebruiken we de onderstaande syntaxis. Het maakt niet uit of de primaire sleutel op één of meerdere kolommen stond.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
De beperking van de primaire sleutel op HumanResources.Employees laten vallen tabel, gebruik dan het onderstaande script:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Als u de primaire sleutel laat vallen, worden zowel de primaire sleutels als de geclusterde of niet-geclusterde indexen verwijderd die samen met het maken van de primaire sleutel zijn gemaakt:
Wijzig de primaire sleutel
In SQL Server zijn er geen directe opdrachten om primaire sleutels te wijzigen. We moeten een bestaande primaire sleutel verwijderen en deze opnieuw maken met de nodige wijzigingen. Daarom zijn de stappen om de primaire sleutel te wijzigen:
- Laat een bestaande primaire sleutel vallen.
- Maak nieuwe primaire sleutels met de nodige wijzigingen.
Primaire sleutel in-/uitschakelen
Terwijl u bulklading uitvoert op een tabel met veel records, schakelt u de primaire sleutel uit en weer in voor betere prestaties. De stappen zijn hieronder:
Schakel de bestaande primaire sleutel uit met de onderstaande syntaxis:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;De primaire sleutel uitschakelen op de HumanResources.Employees tabel, het script is:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Schakel bestaande primaire sleutels in die de status uitgeschakeld hebben. We moeten de index OPNIEUW BOUWEN met behulp van de onderstaande syntaxis:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;De primaire sleutel inschakelen op de HumanResources.Employees tabel, gebruik dan het volgende script:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
De mythen over de primaire sleutel
Veel mensen raken in de war over de onderstaande mythes met betrekking tot primaire sleutels in SQL Server.
- Tabel met primaire sleutel is geen heaptabel
- Primaire sleutels hebben de geclusterde index en gegevens gesorteerd in fysieke volgorde
Laten we ze verduidelijken.
Tabel met primaire sleutel is geen heaptabel
Laten we, voordat we dieper duiken, de definitie van de primaire sleutel en de heaptabel herzien.
De primaire sleutel maakt een geclusterde index op een tabel als daar geen andere geclusterde indexen beschikbaar zijn. Een tabel zonder een geclusterde index wordt een heaptabel.
Op basis van deze definities kunnen we begrijpen dat de primaire sleutel alleen een geclusterde index maakt als er geen andere geclusterde indexen in de tabel staan. Als er bestaande geclusterde indexen zijn, zal het maken van de primaire sleutel een niet-geclusterde index creëren in de tabel die overeenkomt met de primaire sleutel.
Laten we dit verifiëren door de HumanResources.Employees . weg te laten Tabel en opnieuw maken:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
We kunnen de NONCLUSTERED index-optie specificeren voor de primaire sleutel (zie hierboven). Er is een tabel gemaakt met een unieke, niet-geclusterde index voor de primaire Key PK_Employees .
Daarom is deze tabel een heaptabel, ook al heeft deze een primaire sleutel.
Laten we eens kijken of SQL Server een niet-geclusterde index voor de primaire sleutel kan maken als we het trefwoord Niet-geclusterd niet specificeren tijdens het maken van de primaire sleutel. Gebruik het onderstaande script:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Hier hebben we afzonderlijk een geclusterde index gemaakt vóór het maken van de primaire sleutel. En een tabel kan maar één geclusterde index hebben. Daarom heeft SQL Server de primaire sleutel gemaakt als een unieke, niet-geclusterde index. Op dit moment is de tabel geen Heap-tabel omdat deze een geclusterde index heeft.
Als ik van gedachten zou veranderen en de geclusterde index op de First_Name en Achternaam kolommen met behulp van het onderstaande script:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
We hebben de geclusterde index met succes verwijderd. De HumanResources.Employees table is een Heap-tabel, ook al hebben we een primaire sleutel in de tabel:
Dit verhelpt de mythe dat een tabel met een primaire sleutel een heap-tabel kan zijn als er geen geclusterde indexen beschikbaar zijn op de tafel.
Primaire sleutel heeft een geclusterde index en gegevens worden in fysieke volgorde gesorteerd
Zoals we uit het vorige voorbeeld hebben geleerd, kan een primaire sleutel in SQL een niet-geclusterde index hebben. In dat geval zouden de records niet in fysieke volgorde worden gesorteerd.
Laten we de tabel verifiëren met de geclusterde index op een primaire sleutel. We gaan controleren of het de records in fysieke volgorde sorteert.
Maak de HumanResources.Employees . opnieuw tabel met minimale kolommen en de IDENTITY-eigenschap verwijderd voor de Employee_ID kolom:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Nu we de tabel hebben gemaakt zonder de primaire sleutel of een geclusterde index, kunnen we 3 records INVOEREN in een niet-gesorteerde volgorde voor de Employee_Id kolom:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Laten we een keuze maken uit de HumanResources.Employees tafel:
SELECT *
FROM HumanResources.Employees
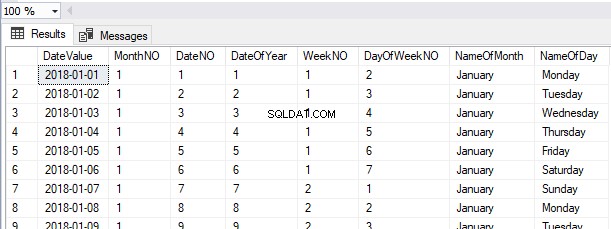
We kunnen de records zien die zijn opgehaald in dezelfde volgorde als de records die op dit moment uit de Heap-tabel zijn ingevoegd.
Laten we een primaire sleutel maken op deze heap-tabel en kijken of deze invloed heeft op de SELECT-instructie:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Na het maken van de primaire sleutel kunnen we zien dat de SELECT-instructie records heeft opgehaald in oplopende volgorde van de Employee_Id (Kolom Primaire sleutel). Dit komt door de geclusterde index op Employee_Id .
Als een primaire sleutel wordt gemaakt met de niet-geclusterde optie, worden de tabelgegevens niet gesorteerd op basis van de kolom Primaire sleutel.
Als de lengte van een enkel record in een tabel groter is dan 4030 bytes, past er slechts één record op een pagina. De geclusterde index zorgt ervoor dat de pagina's in fysieke volgorde staan.
Een pagina is een fundamentele opslageenheid in SQL Server-gegevensbestanden met een grootte van 8 KB (8192 bytes). Slechts 8060 bytes van die eenheid zijn bruikbaar voor gegevensopslag. Het resterende bedrag is voor paginakoppen en andere interne onderdelen.
Tips voor het kiezen van primaire sleutelkolommen
- Kolommen van het gegevenstype integer zijn het meest geschikt voor kolommen met primaire sleutels, omdat ze kleinere opslagruimten in beslag nemen en de gegevens sneller kunnen ophalen.
- Omdat primaire-sleutelkolommen standaard een geclusterde index hebben, gebruikt u de IDENTITY-optie voor kolommen van het gegevenstype integer om nieuwe waarden in incrementele volgorde te genereren.
- In plaats van een primaire sleutel voor meerdere kolommen te maken, maakt u een nieuwe integerkolom met de IDENTITY-eigenschap gedefinieerd. Maak ook een unieke index op meerdere kolommen die oorspronkelijk zijn geïdentificeerd voor betere prestaties.
- Probeer kolommen met string datatypes zoals varchar, nvarchar, etc. te vermijden. We kunnen de sequentiële toename van data op deze datatypes niet garanderen. Het kan de INSERT-prestaties op deze kolommen beïnvloeden.
- Kies kolommen waarin waarden niet worden bijgewerkt als primaire sleutels. Als de waarde van de primaire sleutel bijvoorbeeld kan veranderen van 5 in 1000, moet de B-tree die is gekoppeld aan de geclusterde index worden bijgewerkt, wat resulteert in een lichte prestatievermindering.
- Als kolommen met stringgegevenstypes moeten worden gekozen als kolommen met primaire sleutel, zorg er dan voor dat de lengte van de kolommen van het varchar- of nvarchar-gegevenstype klein blijft voor betere prestaties.
Conclusie
We hebben de basisprincipes van beperkingen die beschikbaar zijn in SQL Server doorgenomen. We hebben de beperkingen van de primaire sleutel in detail onderzocht en geleerd hoe u primaire sleutels kunt maken, verwijderen, wijzigen, uitschakelen en opnieuw opbouwen. Daarnaast hebben we enkele populaire mythes rond primaire sleutels verduidelijkt met voorbeelden.
Houd ons in de gaten voor het volgende artikel!