Toevoeging: SQL Server 2012 vertoont enige verbeterde prestaties op dit gebied, maar lijkt de onderstaande specifieke problemen niet aan te pakken. Dit zou blijkbaar opgelost moeten worden in de volgende hoofdversie na SQL Server 2012!
Je plan laat zien dat de enkele inserts geparametriseerde procedures gebruiken (mogelijk automatisch geparametriseerd), dus de parseer-/compileertijd hiervoor zou minimaal moeten zijn.
Ik dacht dat ik hier wat meer naar zou kijken, dus stel een lus (script) in en probeerde het aantal VALUES aan te passen clausules en het vastleggen van de compileertijd.
Vervolgens heb ik de compileertijd gedeeld door het aantal rijen om de gemiddelde compileertijd per clausule te krijgen. De resultaten staan hieronder
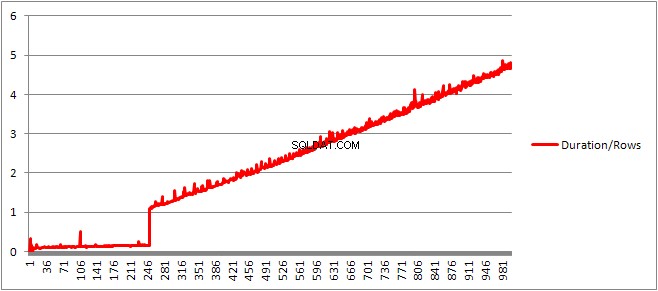
Tot 250 VALUES clausules presenteren de compileertijd / het aantal clausules heeft een lichte opwaartse trend, maar niets te dramatisch.
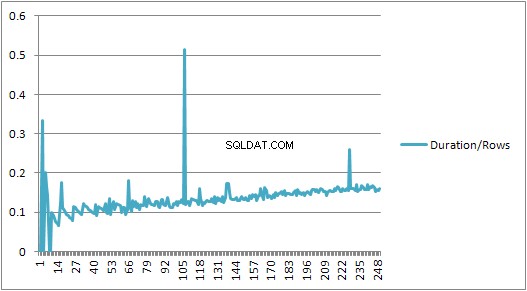
Maar dan is er een plotselinge verandering.
Dat gedeelte van de gegevens wordt hieronder weergegeven.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
De grootte van het gecachete plan dat lineair was gegroeid, neemt plotseling af, maar CompileTime wordt zevenvoudig vergroot en CompileMemory schiet omhoog. Dit is het afkappunt tussen een automatisch geparametriseerd plan (met 1.000 parameters) en een niet-geparametriseerd plan. Daarna lijkt het lineair minder efficiënt te worden (in termen van het aantal waardeclausules dat in een bepaalde tijd wordt verwerkt).
Ik weet niet zeker waarom dit zou moeten zijn. Vermoedelijk moet het bij het samenstellen van een plan voor specifieke letterlijke waarden een activiteit uitvoeren die niet lineair schaalt (zoals sorteren).
Het lijkt geen invloed te hebben op de grootte van het in de cache opgeslagen queryplan toen ik een query probeerde die volledig uit dubbele rijen bestond en geen van beide de volgorde van de uitvoer van de tabel met constanten beïnvloedt (en terwijl u invoegt in een hoop tijd besteed aan het sorteren zou sowieso zinloos zijn, zelfs als dat wel het geval was).
Bovendien, als een geclusterde index aan de tabel wordt toegevoegd, toont het plan nog steeds een expliciete sorteerstap, zodat het niet lijkt te sorteren tijdens het compileren om een sortering tijdens runtime te voorkomen.

Ik heb geprobeerd dit in een debugger te bekijken, maar de openbare symbolen voor mijn versie van SQL Server 2008 lijken niet beschikbaar te zijn, dus in plaats daarvan moest ik kijken naar de equivalente UNION ALL constructie in SQL Server 2005.
Een typische stacktracering staat hieronder
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Dus als je de namen in de stacktracering verlaat, lijkt het erop dat het veel tijd kost om strings te vergelijken.
Dit KB-artikel geeft aan dat DeriveNormalizedGroupProperties wordt geassocieerd met wat vroeger de normalisatiefase van queryverwerking werd genoemd
Deze fase wordt nu binding of algebrisering genoemd en het vereist de uitvoer van de expressie-ontledingsboom van de vorige ontledingsfase en voert een algebriseerde expressiestructuur uit (queryprocessor-boom) om door te gaan naar optimalisatie (in dit geval triviale planoptimalisatie) [ref].
Ik probeerde nog een experiment (script), dat was om de originele test opnieuw uit te voeren, maar ik keek naar drie verschillende gevallen.
- Voornaam en achternaam Strings met een lengte van 10 tekens zonder duplicaten.
- Voornaam en achternaam Strings met een lengte van 50 tekens zonder duplicaten.
- Voornaam en achternaam Strings met een lengte van 10 tekens met allemaal duplicaten.
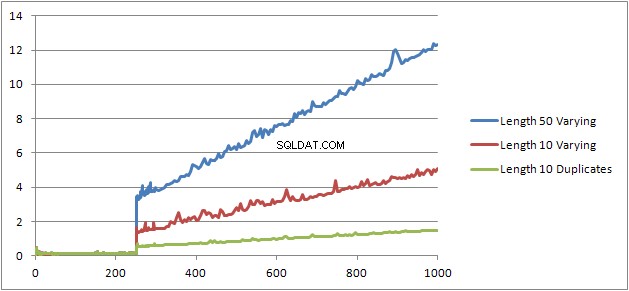
Het is duidelijk te zien dat hoe langer de snaren, hoe slechter dingen worden en omgekeerd, hoe meer duplicaten, hoe beter dingen worden. Zoals eerder vermeld, hebben duplicaten geen invloed op de grootte van het in de cache opgeslagen plan, dus ik neem aan dat er een proces van dubbele identificatie moet zijn bij het construeren van de algebriseerde expressiestructuur zelf.
Bewerken
Een plaats waar deze informatie wordt gebruikt, wordt hier getoond door @Lieven
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Omdat het tijdens het compileren kan bepalen dat de Name kolom heeft geen duplicaten en slaat de volgorde over op de secundaire 1/ (ID - ID) expressie tijdens runtime (de sortering in het plan heeft slechts één ORDER BY kolom) en er wordt geen fout door nul gedeeld. Als er duplicaten aan de tabel worden toegevoegd, geeft de sorteeroperator twee kolommen weer en wordt de verwachte fout verhoogd.