Uit mijn hoofd, ik heb een oplossing van 50% voor je.
Het probleem
SSIS echt geeft om metadata, dus variaties daarin leiden tot uitzonderingen. DTS was in die zin veel vergevingsgezinder. Die sterke behoefte aan consistente metadata maakt het gebruik van de Flat File Source lastig.
Op zoekvraag gebaseerde oplossing
Als het probleem het onderdeel is, laten we het dan niet gebruiken. Wat ik leuk vind aan deze benadering is dat het conceptueel hetzelfde is als het opvragen van een tabel:de volgorde van kolommen doet er niet toe en de aanwezigheid van extra kolommen doet er niet toe.
Variabelen
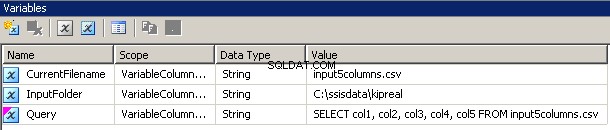
Ik heb 3 variabelen gemaakt, allemaal van het type string:CurrentFileName, InputFolder en Query.
- InputFolder is vast verbonden met de bronmap. In mijn voorbeeld is het
C:\ssisdata\Kipreal - CurrentFileName is de naam van een bestand. Tijdens de ontwerptijd was het
input5columns.csvmaar dat zal tijdens runtime veranderen. - Query is een uitdrukking
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Verbindingsmanager
Maak een verbinding met het invoerbestand met behulp van het JET OLEDB-stuurprogramma. Nadat ik het had gemaakt zoals beschreven in het gekoppelde artikel, hernoemde ik het naar FileOLEDB en stelde ik een expressie in op de ConnectionManager van "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Besturingsstroom
Mijn controlestroom ziet eruit als een gegevensstroomtaak die is genest in een Forreach-bestandsenumerator
Foreach-bestandsteller
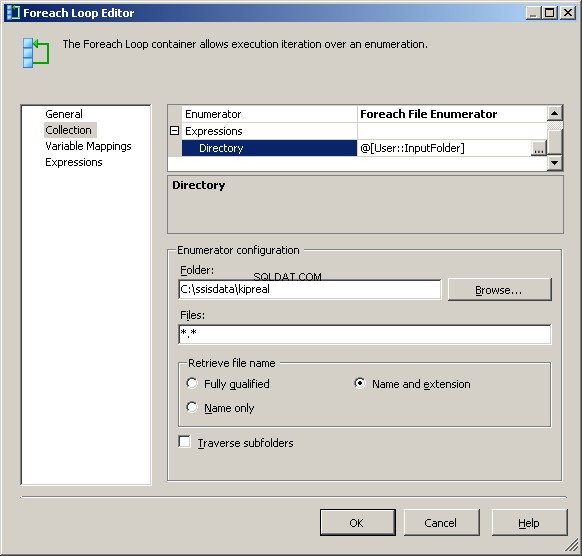
My Forreach File-enumerator is geconfigureerd om met bestanden te werken. Ik heb een uitdrukking in de directory geplaatst voor @[User::InputFolder] Merk op dat op dit punt, als de waarde van die map moet veranderen, deze correct zal worden bijgewerkt in zowel de Verbindingsmanager als de bestandsenumerator. Kies in "Bestandsnaam ophalen", in plaats van de standaard "Volledig gekwalificeerd", "Naam en extensie"
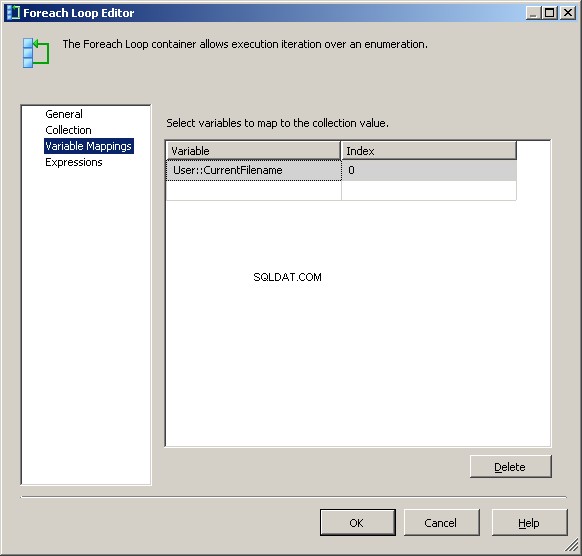
Wijs op het tabblad Variabele toewijzingen de waarde toe aan onze @[User::CurrentFileName] variabel
Op dit punt verandert elke iteratie van de lus de waarde van de @[User::Query om de huidige bestandsnaam weer te geven.
Gegevensstroom
Dit is eigenlijk het gemakkelijkste stuk. Gebruik een OLE DB-bron en sluit deze aan zoals aangegeven.
Gebruik de FileOLEDB-verbindingsbeheerder en wijzig de modus voor gegevenstoegang in "SQL-opdracht van variabele". Gebruik de @[User::Query] variabele daar in, klik op OK en je bent klaar om te werken. 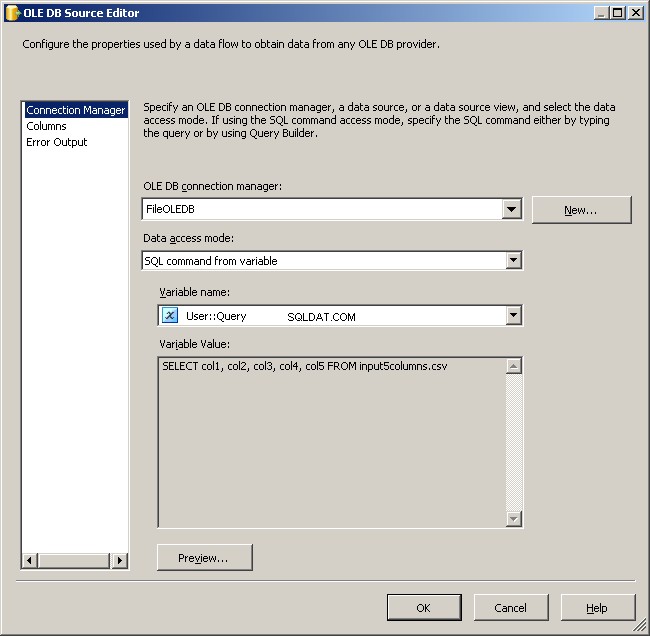
Voorbeeldgegevens
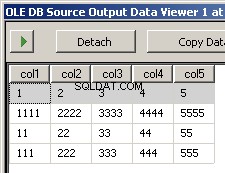
Ik heb twee voorbeeldbestanden gemaakt input5columns.csv en input7columns.csv Alle kolommen van 5 staan in 7, maar 7 heeft ze in een andere volgorde (col2 is ordinale positie 2 en 6). Ik heb alle waarden in 7 genegeerd om duidelijk te maken met welk bestand wordt gewerkt.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
en
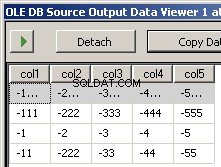
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Het uitvoeren van het pakket resulteert in deze twee screenshots
Wat ontbreekt
Ik ken geen manier om de op query's gebaseerde benadering te vertellen dat het OK is als een kolom niet bestaat. Als er een unieke sleutel is, neem ik aan dat u uw zoekopdracht zo kunt definiëren dat deze alleen de kolommen heeft die moeten wees erbij en voer vervolgens zoekopdrachten uit op het bestand om te proberen de kolommen te verkrijgen die zou moeten om daar te zijn en de zoekopdracht niet te mislukken als de kolom niet bestaat. Wel behoorlijk kludgey.