Waarom presteert de cross-apply-query zo slecht op dit eenvoudige XML-document, en exponentieel langzamer naarmate de dataset groeit?
Het is het gebruik van de bovenliggende as om de attribuut-ID van het itemknooppunt te krijgen.
Het is dit deel van het zoekplan dat problematisch is.

Let op de 423 rijen die uit de lagere tabelwaardefunctie komen.
Door nog één itemknooppunt met drie veldknooppunten toe te voegen, krijgt u dit.
732 rijen geretourneerd.
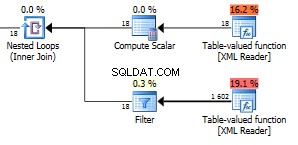
Wat als we de knooppunten van de eerste zoekopdracht verdubbelen tot een totaal van 6 itemknooppunten?
We zijn tot maar liefst 1602 rij teruggekeerd.
Het cijfer 18 in de bovenste functie zijn alle veldknooppunten in uw XML. We hebben hier 6 items met drie velden in elk item. Die 18 knooppunten worden gebruikt in een geneste lus die aansluit bij de andere functie, dus 18 uitvoeringen die 1602 rijen retourneren, geven dat het 89 rijen per iteratie retourneert. Dat is toevallig het exacte aantal knooppunten in de hele XML. Nou, het is eigenlijk één meer dan alle zichtbare knooppunten. Ik weet niet waarom. U kunt deze query gebruiken om het totale aantal knooppunten in uw XML te controleren.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Dus het algoritme dat door SQL Server wordt gebruikt om de waarde te krijgen wanneer u de bovenliggende as gebruikt .. in een waardenfunctie is dat het eerst alle knooppunten vindt waarop u versnippert, 18 in het laatste geval. Voor elk van die knooppunten versnippert en retourneert het het volledige XML-document en controleert het in de filteroperator voor het knooppunt dat u echt wilt. Daar heb je je exponentiële groei. In plaats van de bovenliggende as te gebruiken, moet je een extra kruis toepassen. Eerst versnipperen op het stuk en dan op het veld.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Ik heb ook gewijzigd hoe u toegang krijgt tot de tekstwaarde van het veld. Met behulp van . laat SQL Server op zoek gaan naar onderliggende knooppunten naar field en voeg die waarden samen in het resultaat. Je hebt geen onderliggende waarden, dus het resultaat is hetzelfde, maar het is een goede zaak om dat deel in het queryplan (de UDX-operator) te vermijden.
Het queryplan heeft geen probleem met de bovenliggende as als u een XML-index gebruikt, maar u zult nog steeds profiteren van het wijzigen van de manier waarop u de veldwaarde ophaalt.