Schermafbeelding #1 toont enkele punten om onderscheid te maken tussen Merge Join transformation en Lookup transformation .
Wat betreft opzoeken:
Als u rijen wilt vinden die overeenkomen in bron 2 op basis van invoer van bron 1 en als u weet dat er slechts één overeenkomst zal zijn voor elke invoerrij, dan raad ik u aan om de opzoekbewerking te gebruiken. Een voorbeeld zou u zijn OrderDetails tabel en u wilt de overeenkomende Order Id . vinden en Customer Number , dan is Opzoeken een betere optie.
Met betrekking tot samenvoeging:
Als u joins wilt uitvoeren, zoals het ophalen van alle adressen (thuis, werk, overig) van Address tabel voor een bepaalde Klant in de Customer tabel, dan moet je voor Merge Join gaan, omdat de klant 1 of meer adressen kan hebben.
Een voorbeeld om te vergelijken:
Hier is een scenario om de prestatieverschillen tussen Merge Join te demonstreren en Lookup . De gegevens die hier worden gebruikt, zijn een één-op-één-join, wat het enige scenario is dat tussen hen wordt vergeleken.
-
Ik heb drie tabellen met de naam
dbo.ItemPriceInfo,dbo.ItemDiscountInfoendbo.ItemAmount. Scripts voor deze tabellen maken vindt u in het gedeelte SQL-scripts. -
Tabellen
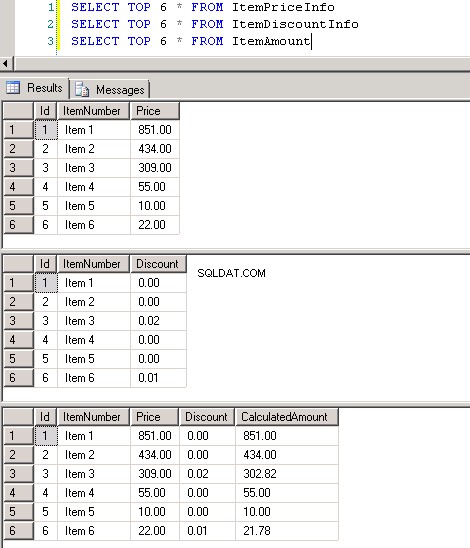
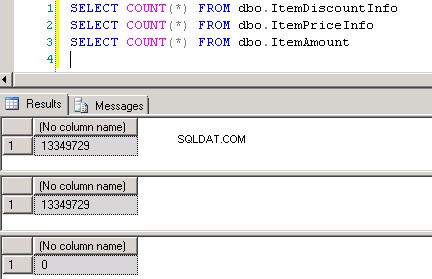
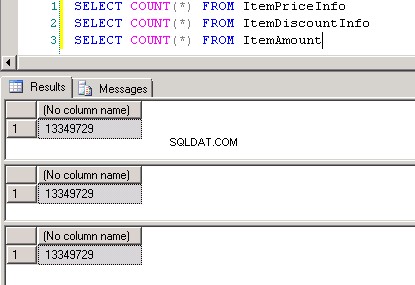
dbo.ItemPriceInfoendbo.ItemDiscountInfobeide hebben 13.349.729 rijen. Beide tabellen hebben het ItemNumber als de gemeenschappelijke kolom. ItemPriceInfo heeft prijsinformatie en ItemDiscountInfo heeft kortingsinformatie. Schermafbeelding #2 toont het aantal rijen in elk van deze tabellen. Schermafbeelding #3 toont de bovenste 6 rijen om een idee te geven van de gegevens in de tabellen. -
Ik heb twee SSIS-pakketten gemaakt om de prestaties van Merge Join en Lookup-transformaties te vergelijken. Beide pakketten moeten de informatie uit tabellen
dbo.ItemPriceInfo. halen endbo.ItemDiscountInfo, bereken het totale bedrag en sla het op in de tabeldbo.ItemAmount. -
Eerste pakket gebruikt
Merge Jointransformatie en daarbinnen gebruikte het INNER JOIN om de gegevens te combineren. Schermafbeeldingen #4 en #5 toon de uitvoering van het voorbeeldpakket en de uitvoeringsduur. Het duurde05minuten14seconden719milliseconden om het op transformatie gebaseerde Merge Join-pakket uit te voeren. -
Tweede pakket gebruikt
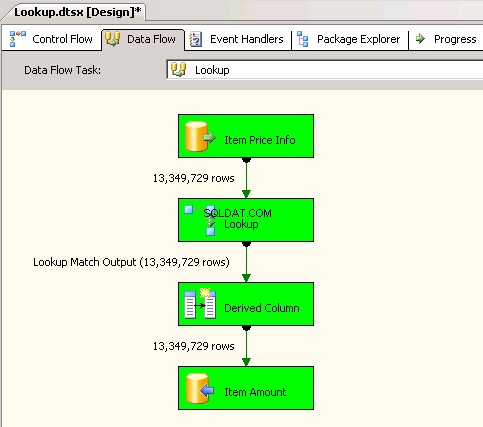
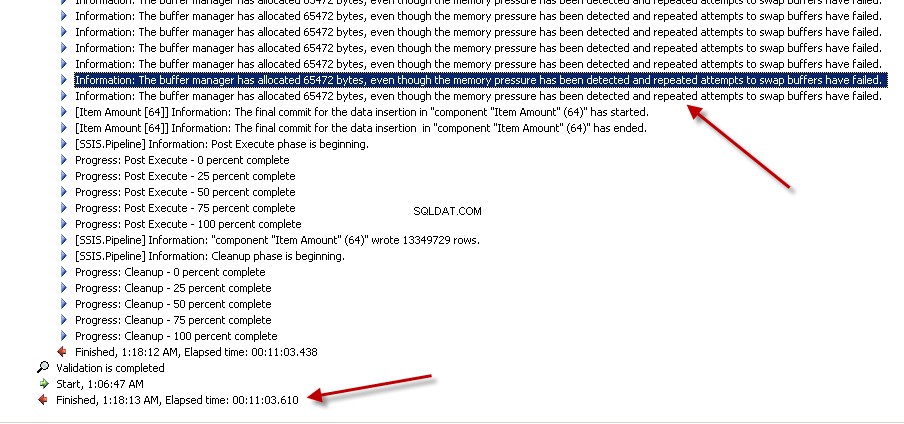
Lookuptransformatie met Volledige cache (wat de standaardinstelling is). creenshots #6 en #7 toon de uitvoering van het voorbeeldpakket en de uitvoeringsduur. Het duurde11minuten03seconden610milliseconden om het op de Lookup-transformatie gebaseerde pakket uit te voeren. U kunt het waarschuwingsbericht Informatie tegenkomen:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Hier is een link waarin wordt gesproken over het berekenen van de grootte van de opzoekcache. Tijdens deze pakketuitvoering nam het opschonen van de pijplijn veel tijd in beslag, ook al werd de gegevensstroomtaak sneller voltooid. -
Dit niet gemiddelde Lookup-transformatie is slecht. Het is alleen dat het verstandig moet worden gebruikt. Ik gebruik dat vrij vaak in mijn projecten, maar nogmaals, ik heb niet elke dag te maken met 10+ miljoen rijen om op te zoeken. Meestal verwerken mijn banen tussen de 2 en 3 miljoen rijen en daarvoor zijn de prestaties echt goed. Tot 10 miljoen rijen presteerden beide even goed. Meestal heb ik gemerkt dat de bottleneck de bestemmingscomponent blijkt te zijn in plaats van de transformaties. U kunt dat ondervangen door meerdere bestemmingen te hebben. Hier is een voorbeeld dat de implementatie van meerdere bestemmingen laat zien.
-
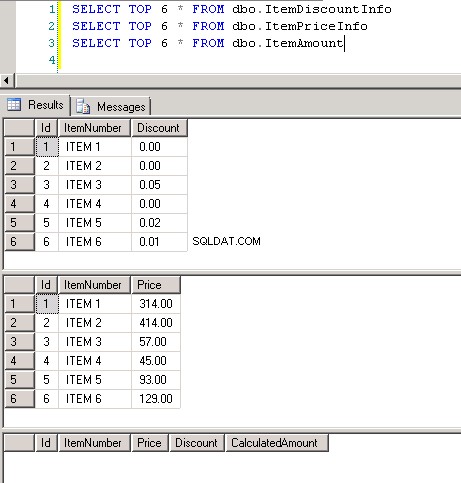
Schermafbeelding #8 toont het aantal records in alle drie de tabellen. Schermafbeelding #9 toont top 6 records in elk van de tabellen.
Ik hoop dat dat helpt.
SQL-scripts:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Screenshot #1:

Screenshot #2:
Screenshot #3:
Screenshot #4:
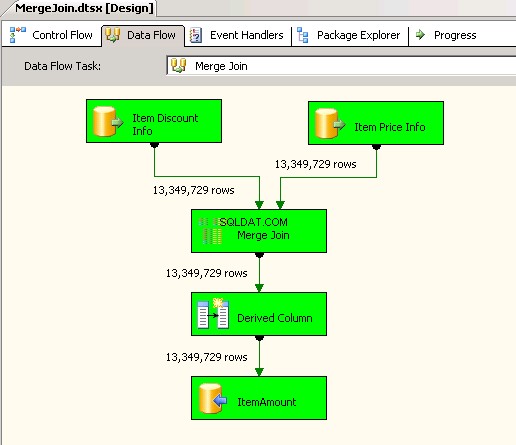
Screenshot #5:

Screenshot #6:
Screenshot #7:
Screenshot #8:
Screenshot #9: