Dit maakt deel uit van een serie SQL Server Internals Problematic Operators. Zorg ervoor dat je Kalen's eerste bericht en tweede bericht over dit onderwerp leest.
SQL Server bestaat al meer dan 30 jaar en ik werk al bijna net zo lang met SQL Server. Ik heb in de loop der jaren (en decennia!) en versies van dit ongelooflijke product veel veranderingen gezien. In deze berichten zal ik met u delen hoe ik kijk naar enkele van de functies of aspecten van SQL Server, soms samen met een beetje historisch perspectief.
De vorige keer had ik het over hashing in een SQL Server-queryplan als een potentieel problematische operator in SQL-serverdiagnostiek. Hashing wordt vaak gebruikt voor joins en aggregatie wanneer er geen bruikbare index is. En net als scans (waar ik het in de eerste post in deze serie over had), zijn er momenten waarop hashen eigenlijk een betere keuze is dan de alternatieven. Voor hash-joins is een van de alternatieven LOOP JOIN, waar ik je de vorige keer ook al over vertelde.
In dit bericht vertel ik je over een ander alternatief voor hashen. De meeste alternatieven voor hashing vereisen dat de gegevens worden gesorteerd, dus ofwel moet het plan een SORT-operator bevatten, of de vereiste gegevens moeten al zijn gesorteerd vanwege bestaande indexen.
Verschillende soorten joins voor SQL Server-diagnose
Voor JOIN-bewerkingen is het meest voorkomende en bruikbare type JOIN een LOOP JOIN. Ik beschreef het algoritme voor een LOOP JOIN in de vorige post. Hoewel de gegevens zelf niet hoeven te worden gesorteerd voor een LOOP JOIN, maakt de aanwezigheid van een index op de binnenste tabel de join veel efficiënter en zoals u zou moeten weten, impliceert de aanwezigheid van een index enige sortering. Terwijl een geclusterde index de gegevens zelf sorteert, sorteert een niet-geclusterde index de indexsleutelkolommen. In de meeste gevallen, zonder de index, zal de optimizer van SQL Server ervoor kiezen om het HASH JOIN-algoritme te gebruiken. We zagen dit de vorige keer in het voorbeeld, dat zonder indexen HASH JOIN werd gekozen, en met indexen kregen we een LOOP JOIN.
Het derde type join is een MERGE JOIN. Dit algoritme werkt op twee reeds gesorteerde datasets. Als we proberen twee sets gegevens te combineren (of samen te voegen) die al zijn gesorteerd, hoeft u slechts één keer door elke set te gaan om de overeenkomende rijen te vinden. Hier is de pseudocode voor het merge join-algoritme:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Hoewel MERGE JOIN een zeer efficiënt algoritme is, vereist het wel dat beide invoergegevenssets worden gesorteerd op de join-sleutel, wat meestal betekent dat er een geclusterde index op de join-sleutel is voor beide tabellen. Aangezien u slechts één geclusterde index per tabel krijgt, is het kiezen van de kolom met geclusterde sleutels om samenvoeging toe te staan mogelijk niet de beste keuze voor het clusteren van sleutels.
Dus meestal raad ik je niet aan om indexen te bouwen alleen voor het doel van MERGE JOINS, maar als je uiteindelijk een MERGE JOIN krijgt vanwege al bestaande indexen, is het meestal een goede zaak. Behalve dat beide invoergegevenssets moeten worden gesorteerd, vereist MERGE JOIN ook dat ten minste één van de gegevenssets unieke waarden heeft voor de samenvoegingssleutel.
Laten we een voorbeeld bekijken. Eerst maken we de Headers . opnieuw en Details tabellen:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Bekijk vervolgens het plan voor een join tussen deze tabellen:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Dit is het plan:

Merk op dat zelfs met een geclusterde index op beide tabellen, we een HASH JOIN krijgen. We kunnen een van de indexen opnieuw opbouwen om UNIEK te zijn. In dit geval moet het de index zijn op de Headers tabel, want dat is de enige die unieke waarden heeft voor SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Voer nu de query opnieuw uit en merk op dat het plan doet hoe een SAMENVOEGEN AANMELDEN.

Deze plannen profiteren van het feit dat de gegevens al in een index zijn gesorteerd, omdat het uitvoeringsplan kan profiteren van de sortering. Maar soms moet SQL Server sorteren als onderdeel van de uitvoering van de query. Het kan zijn dat u af en toe een SORT-operator in een plan ziet verschijnen, zelfs als u niet om gesorteerde uitvoer vraagt. Als SQL Server denkt dat een MERGE JOIN een goede optie is, maar een van de tabellen niet de juiste geclusterde index heeft en klein genoeg is om het sorteren erg goedkoop te maken, kan een SORTERING worden uitgevoerd om MERGE JOIN mogelijk te maken gebruikt.
Maar meestal verschijnt de SORT-operator in zoekopdrachten waarin we hebben gevraagd om gesorteerde gegevens met ORDER BY, zoals in het volgende voorbeeld.
SELECT * FROM Details
ORDER BY ProductID;
GO

De geclusterde index wordt gescand (dit is hetzelfde als het scannen van de tabel) en vervolgens worden de rijen gesorteerd zoals gevraagd.
Omgaan met reeds gesorteerde geclusterde index
Maar wat als de gegevens al zijn gesorteerd in een geclusterde index en de query een ORDER BY bevat in de geclusterde sleutelkolom? In het bovenstaande voorbeeld hebben we een geclusterde index gebouwd op SalesOrderID in de tabel Details. Bekijk de volgende twee vragen:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Als we deze zoekopdrachten samen uitvoeren, geeft het Quest Spotlight Tuning Pack-analysevenster aan dat de twee plannen even duur zijn; elk is 50% van het totaal. Dus, wat is eigenlijk het verschil tussen hen?
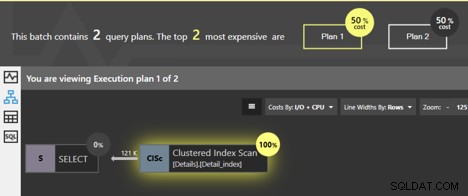
Beide query's scannen de geclusterde index en SQL Server weet dat als de pagina's van het bladniveau in volgorde worden gevolgd, de gegevens in geclusterde sleutelvolgorde terugkomen. Er hoeft niet extra gesorteerd te worden, dus er wordt geen SORT-operator aan het plan toegevoegd. Maar er IS een verschil. We kunnen op de operator Clustered Index Scan klikken en krijgen wat gedetailleerde informatie.
Bekijk eerst de gedetailleerde informatie voor het eerste plan, voor de vraag zonder ORDER BY.

De details vertellen ons dat de eigenschap "Geordend" False is. Er is hier geen vereiste dat de gegevens in gesorteerde volgorde worden geretourneerd. Het blijkt dat in de meeste gevallen de gemakkelijkste manier om de gegevens op te halen is door de pagina's van de geclusterde index te volgen, zodat de gegevens uiteindelijk in volgorde worden geretourneerd, maar er is geen garantie. Wat de eigenschap False betekent, is dat er geen vereiste is dat SQL Server de geordende pagina's volgt om het resultaat te retourneren. Er zijn eigenlijk andere manieren waarop SQL Server alle rijen voor de tabel kan ophalen, zonder de geclusterde index te volgen. Als SQL Server tijdens de uitvoering ervoor kiest om een andere methode te gebruiken om de rijen op te halen, zien we geen geordende resultaten.
Voor de tweede vraag zien de details er als volgt uit:
 Omdat de query een ORDER BY bevatte, IS het een vereiste dat de gegevens in gesorteerde volgorde en SQL Server worden geretourneerd volgt de pagina's van de geclusterde index, in volgorde.
Omdat de query een ORDER BY bevatte, IS het een vereiste dat de gegevens in gesorteerde volgorde en SQL Server worden geretourneerd volgt de pagina's van de geclusterde index, in volgorde.
Het belangrijkste om te onthouden is dat er GEEN garantie is voor gesorteerde gegevens als u ORDER BY niet opneemt in uw zoekopdracht. Alleen omdat u een geclusterde index heeft, is er nog steeds geen garantie! Zelfs als u het afgelopen jaar elke keer dat u de zoekopdracht hebt uitgevoerd de gegevens weer op orde hebt gekregen zonder ORDER BY, is er geen garantie dat u de gegevens weer op orde krijgt. Het gebruik van ORDER BY is de enige manier om de volgorde te garanderen waarin uw resultaten worden geretourneerd.
Tips voor het gebruik van sorteerbewerkingen
Dus, is een SORTEREN een bewerking die moet worden vermeden in de diagnostiek van SQL-servers? Net als bij scans en hashbewerkingen is het antwoord natuurlijk ‘het hangt ervan af’. Sorteren kan erg duur zijn, vooral bij grote datasets. Een juiste indexering helpt SQL Server voorkomen dat SORT-bewerkingen worden uitgevoerd, omdat een index in feite betekent dat uw gegevens zijn voorgesorteerd. Maar indexeren brengt kosten met zich mee. Er zijn opslagkosten, naast onderhoudskosten, voor elke index. Als uw gegevens sterk worden bijgewerkt, moet u het aantal indexen tot een minimum beperken.
Als u merkt dat sommige van uw traag lopende query's wel SORT-bewerkingen in hun plannen laten zien, en als die SORT's tot de duurste operators in het plan behoren, kunt u overwegen indexen te bouwen waarmee SQL Server het sorteren kan vermijden. Maar u moet grondig testen om er zeker van te zijn dat de aanvullende indexen andere query's die cruciaal zijn voor uw algehele toepassingsprestaties niet vertragen.