Benjamin Nevarez is een onafhankelijke consultant gevestigd in Los Angeles, Californië, die gespecialiseerd is in het afstemmen en optimaliseren van SQL Server-query's. Hij is de auteur van "SQL Server 2014 Query Tuning &Optimization" en "Inside the SQL Server Query Optimizer" en co-auteur van "SQL Server 2012 Internals". Met meer dan 20 jaar ervaring in relationele databases is Benjamin ook spreker op vele SQL Server-conferenties, waaronder de PASS Summit, SQL Server Connections en SQLBits. Benjamins blog is te vinden op https://www.benjaminnevarez.com en hij is ook bereikbaar via e-mail op admin op benjaminnevarez dot com en op twitter op @BenjaminNevarez.
Hoewel de meeste informatie, blogs en documentatie over SQL Server 2014 gericht waren op Hekaton en andere nieuwe functies, zijn er niet veel details verstrekt over de nieuwe kardinaliteitsschatter. Momenteel praat BOL er alleen indirect over in de sectie What's New (Database Engine), en zegt dat SQL Server 2014 "substantiële verbeteringen bevat aan de component die queryplannen maakt en optimaliseert", en de ALTER DATABASE verklaring laat zien hoe u het gedrag ervan kunt in- of uitschakelen. Gelukkig kunnen we wat aanvullende informatie krijgen door het onderzoekspaper Testing Cardinality Estimation Models in SQL Server door Campbell Fraser et al. te lezen. Hoewel de focus van het artikel ligt op het kwaliteitsborgingsproces van het nieuwe schattingsmodel, biedt het ook een basisinleiding tot de nieuwe kardinaliteitsschatter en de motivatie voor het herontwerp ervan.
Dus, wat is een kardinaliteitsschatter? Een kardinaliteitsschatter is het onderdeel van de queryprocessor wiens taak het is om het aantal rijen te schatten dat wordt geretourneerd door relationele bewerkingen in een query. Deze informatie wordt, samen met enkele andere gegevens, door de query-optimizer gebruikt om een efficiënt uitvoeringsplan te selecteren. Kardinaliteitsschatting is inherent onnauwkeurig, omdat het een wiskundig model is dat afhankelijk is van statistische informatie. Het is ook gebaseerd op verschillende aannames die, hoewel niet gedocumenteerd, in de loop der jaren bekend zijn geweest - sommige daarvan omvatten de aannames voor uniformiteit, onafhankelijkheid, inperking en inclusie. Een korte beschrijving van deze aannames volgt.
- Uniformiteit . Wordt gebruikt wanneer de distributie voor een attribuut onbekend is, bijvoorbeeld binnen bereikrijen in een histogramstap of wanneer er geen histogram beschikbaar is.
- Onafhankelijkheid . Gebruikt wanneer de attributen in een relatie onafhankelijk zijn, tenzij er een correlatie tussen hen bekend is.
- Insluiting . Gebruikt wanneer twee kenmerken hetzelfde kunnen zijn, wordt aangenomen dat ze hetzelfde zijn.
- Inclusie . Wordt gebruikt bij het vergelijken van een attribuut met een constante, er wordt aangenomen dat er altijd een overeenkomst is.
Het is interessant dat ik onlangs heb gesproken over enkele van de beperkingen van deze aannames tijdens mijn laatste lezing op de PASS-top, genaamd Defeating the Limitations of the Query Optimizer. Toch was ik verrast om in de krant te lezen dat de auteurs toegeven dat deze veronderstellingen, volgens hun praktijkervaring, "vaak onjuist" zijn.
De huidige kardinaliteitsschatter is geschreven samen met de volledige queryprocessor voor SQL Server 7.0, die in december 1998 werd uitgebracht. Het is duidelijk dat dit onderdeel gedurende meerdere jaren te maken heeft gehad met meerdere wijzigingen en meerdere releases van SQL Server, inclusief fixes, aanpassingen en uitbreidingen voor geschikt voor kardinaliteitsschatting voor nieuwe T-SQL-functies. Dus u denkt misschien, waarom een onderdeel vervangen dat al zo'n 15 jaar met succes wordt gebruikt?
Waarom een nieuwe kardinaliteitsschatter
De paper legt enkele van de redenen voor het herontwerp uit, waaronder:
- Om de kardinaliteitsschatter aan te passen aan nieuwe werkbelastingpatronen.
- Veranderingen die in de loop der jaren in de kardinaliteitsschatter zijn aangebracht, maakten het onderdeel moeilijk te "debuggen, voorspellen en begrijpen".
- Proberen het huidige model te verbeteren was moeilijk met de huidige architectuur, dus werd een nieuw ontwerp gemaakt, gericht op de scheiding van taken van (a) beslissen hoe een bepaalde schatting moet worden berekend, en (b) het daadwerkelijk uitvoeren van de berekening .
Ik weet niet zeker of Microsoft meer details over de nieuwe kardinaliteitsschatter zal publiceren. Er zijn immers in 15 jaar niet zo veel details gepubliceerd over de oude kardinaliteitsschatter; bijvoorbeeld hoe een bepaalde kardinaliteitsschatting wordt berekend. Aan de andere kant zijn er nieuwe uitgebreide gebeurtenissen die we kunnen gebruiken om problemen met kardinaliteitsschatting op te lossen, of gewoon om te ontdekken hoe het werkt. Deze gebeurtenissen omvatten query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors en query_rpc_set_cardinality .
Regressies plannen
Een belangrijk punt van zorg dat in je opkomt bij zo'n enorme verandering in de query-optimizer, zijn planregressies. De angst voor planregressies wordt beschouwd als het grootste obstakel voor verbeteringen aan de queryoptimalisatie. Regressies zijn problemen die worden geïntroduceerd nadat een oplossing is toegepast op de query-optimizer en die soms wordt aangeduid als de klassieke 'twee fouten maken een recht'. Dit kan gebeuren wanneer twee slechte schattingen, bijvoorbeeld een overschatting van een waarde en de tweede onderschatting, elkaar opheffen en gelukkig een goede schatting geven. Het corrigeren van slechts één van deze waarden kan nu leiden tot een slechte schatting die een negatieve invloed kan hebben op de keuze van de planselectie, waardoor een regressie ontstaat.
Om regressies met betrekking tot de nieuwe kardinaliteitsschatter te voorkomen, biedt SQL Server een manier om deze in of uit te schakelen, aangezien dit afhankelijk is van het compatibiliteitsniveau van de database. Dit kan worden gewijzigd met behulp van de ALTER DATABASE verklaring, zoals eerder aangegeven. Het instellen van een database op het compatibiliteitsniveau 120 zal de nieuwe kardinaliteitsschatter gebruiken, terwijl een compatibiliteitsniveau van minder dan 120 de oude kardinaliteitsschatter zal gebruiken. Als u eenmaal een specifieke kardinaliteitsschatter gebruikt, zijn er bovendien twee traceervlaggen die u kunt gebruiken om naar de andere over te schakelen. Hoewel ik de traceervlaggen op dit moment nergens gedocumenteerd zie, worden ze genoemd als onderdeel van de beschrijving van de query_optimizer_force_both_cardinality_estimation_behaviors uitgebreid evenement. Traceringsvlag 2312 kan worden gebruikt om de nieuwe kardinaliteitsschatter in te schakelen, terwijl traceringsvlag 9481 kan worden gebruikt om deze uit te schakelen. U kunt zelfs de traceervlaggen voor een specifieke zoekopdracht gebruiken met de QUERYTRACEON hint (hoewel het nog niet is gedocumenteerd of dit ook wordt ondersteund).
Voorbeelden
Ten slotte vermeldt het artikel ook enkele geteste scenario's, zoals de overbevolkte primaire sleutel, eenvoudige samenvoeging of het probleem met oplopende sleutels. Het laat ook zien hoe de auteurs hebben geëxperimenteerd met meerdere scenario's (of modelvariaties) en in sommige gevallen enkele van de veronderstellingen van de kardinaliteitsschatter hebben "ontspannen", bijvoorbeeld in het geval van de onafhankelijkheidsveronderstelling, gaande van volledige onafhankelijkheid naar volledige correlatie en iets daartussenin totdat goede resultaten werden gevonden.
Hoewel er geen details op het papier staan, besluit ik enkele van deze scenario's te gaan testen om te proberen te begrijpen hoe de nieuwe kardinaliteitsschatter werkt. Voor nu zal ik je een voorbeeld laten zien met behulp van de onafhankelijkheidsaanname en oplopende sleutels. Ik heb ook de aanname van uniformiteit getest, maar tot nu toe heb ik geen verschil kunnen vinden bij de schatting.
Laten we beginnen met het voorbeeld van de onafhankelijkheidsaanname. Laten we eerst het huidige gedrag bekijken. Zorg ervoor dat u de oude kardinaliteitsschatter gebruikt door de volgende instructie in de AdventureWorks2012-database uit te voeren:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Voer dan uit:
SELECT * FROM Person.Address WHERE City = 'Burbank';
We krijgen naar schatting 196 records zoals hieronder weergegeven:

Op een vergelijkbare manier krijgt de volgende verklaring een geschatte 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Als we beide predikaten gebruiken, hebben we de volgende query, die een geschat aantal rijen van 1.93862 zal hebben (afgerond naar 2 rijen bij gebruik van SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Deze waarde wordt berekend uitgaande van totale onafhankelijkheid van beide predikaten, waarbij de formule (196 * 194) / 19614.0 wordt gebruikt (waarbij 19614 het totale aantal rijen in de tabel is). Het gebruik van een totale correlatie zou ons een schatting van 194 moeten opleveren, aangezien alle records met postcode 91502 van Burbank zijn. De nieuwe kardinaliteitsschatter schat een waarde die geen volledige onafhankelijkheid of totale correlatie veronderstelt. Verander naar de nieuwe kardinaliteitsschatter met behulp van de volgende instructie:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Als u dezelfde instructie nogmaals uitvoert, krijgt u een schatting van 19.3931 rijen, wat u kunt zien als een waarde tussen het aannemen van totale onafhankelijkheid en totale correlatie (afgerond naar 19 rijen in Plan Explorer). De gebruikte formule is selectiviteit van meest selectieve filter * SQRT (selectiviteit van volgende meest selectieve filter) of (194/19614.0) * SQRT (196/19614.0) * 19614 wat 19,393 geeft:

Als u de nieuwe kardinaliteitschatter op databaseniveau hebt ingeschakeld, wilt u deze uitschakelen voor een specifieke query om een planregressie te voorkomen, kunt u traceringsvlag 9481 gebruiken zoals eerder uitgelegd:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Opmerking:de QUERYTRACEON-queryhint wordt gebruikt om een traceringsvlag op queryniveau toe te passen en wordt momenteel alleen in een beperkt aantal scenario's ondersteund. Voor meer informatie over de QUERYTRACEON-queryhint kunt u kijken op https://support.microsoft.com/kb/2801413.
Laten we nu eens kijken naar het oplopende sleutelprobleem, een onderwerp dat ik in dit bericht in meer detail heb uitgelegd. De traditionele aanbeveling van Microsoft om dit probleem op te lossen is om de statistieken handmatig bij te werken na het laden van gegevens, zoals hier wordt uitgelegd - wat het probleem op de volgende manier beschrijft:
Statistieken over oplopende of aflopende sleutelkolommen, zoals IDENTITEIT of realtime tijdstempelkolommen, vereisen mogelijk vaker statistische updates dan de query-optimizer uitvoert. Invoegbewerkingen voegen nieuwe waarden toe aan oplopende of aflopende kolommen. Het aantal toegevoegde rijen is mogelijk te klein om een statistische update te activeren. Als de statistieken niet up-to-date zijn en zoekopdrachten selecteren uit de meest recent toegevoegde rijen, hebben de huidige statistieken geen kardinaliteitsschattingen voor deze nieuwe waarden. Dit kan leiden tot onnauwkeurige kardinaliteitsschattingen en trage queryprestaties. Een zoekopdracht die bijvoorbeeld uit de meest recente verkooporderdatums selecteert, heeft onnauwkeurige kardinaliteitsschattingen als de statistieken niet worden bijgewerkt om kardinaliteitsschattingen voor de meest recente verkooporderdatums op te nemen.
De aanbeveling in mijn artikel was om traceervlaggen 2389 en 2390 te gebruiken, die voor het eerst werden gepubliceerd door Ian Jose in zijn artikel Ascending Keys and Auto Quick Corrected Statistics. U kunt mijn artikel lezen voor een uitleg en een voorbeeld over het gebruik van deze traceervlaggen om dit probleem te voorkomen. Deze traceringsvlaggen werken nog steeds op SQL Server 2014 CTP2. Maar nog beter, ze zijn niet langer nodig als u de nieuwe kardinaliteitsschatter gebruikt.
Hetzelfde voorbeeld gebruikend in mijn bericht:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Voeg wat gegevens in:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Sinds we een index hebben gemaakt, hebben we alleen nieuwe statistieken. Als u de volgende query uitvoert, krijgt u een goede schatting van 35 rijen:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Als we nieuwe gegevens invoeren:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
U kunt de schatting zien met de oude kardinaliteitsschatter zoals hieronder weergegeven:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Aangezien het kleine aantal ingevoegde records niet voldoende was om een automatische update van het statistiekobject te activeren, is het huidige histogram niet op de hoogte van de nieuwe records die zijn toegevoegd en gebruikt de query-optimizer naar schatting 1 rij. Optioneel kunt u traceringsvlaggen 2389 en 2390 gebruiken om een betere schatting te krijgen. Maar als u dezelfde query probeert met de nieuwe kardinaliteitsschatter, krijgt u de volgende schatting:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
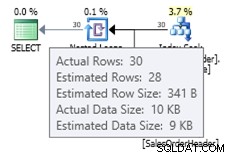
In dit geval krijgen we een betere schatting dan de oude kardinaliteitsschatter (of we krijgen dezelfde schatting als bij het gebruik van traceringsvlaggen 2389 of 2390). De geschatte waarde van 27,9631 (opnieuw afgerond op 28 door Plan Explorer) wordt berekend met behulp van de dichtheidsinformatie van het statistische object vermenigvuldigd met het aantal rijen van de tabel; dat wil zeggen, 0.0008992806 * 31095. De dichtheidswaarde kan worden verkregen met:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Houd er ten slotte rekening mee dat niets dat in dit artikel wordt genoemd, is gedocumenteerd, en dit is het gedrag dat ik tot nu toe heb waargenomen in SQL Server 2014 CTP2. Dit kan allemaal veranderen in een latere CTP of de RTM-versie van het product.