SQL Server 2008 introduceerde schaarse kolommen als een methode om de opslag voor null-waarden te verminderen en meer uitbreidbare schema's te bieden. De wisselwerking is dat er extra overhead is wanneer u niet-NULL-waarden opslaat en ophaalt. Ik was geïnteresseerd in het begrijpen van de kosten voor het opslaan van niet-NULL-waarden, nadat ik met een klant had gesproken die dit gegevenstype in een staging-omgeving gebruikte. Ze willen de schrijfprestaties optimaliseren en ik vroeg me af of het gebruik van dunne kolommen enig effect had, omdat hun methode vereiste dat een rij in de tabel moest worden ingevoegd en deze vervolgens moest worden bijgewerkt. Ik heb een verzonnen voorbeeld voor deze demo gemaakt, hieronder uitgelegd, om te bepalen of dit een goede methode voor hen was om te gebruiken.
Review door interne medewerkers
Onthoud dat als u een kolom maakt voor een tabel die NULL-waarden toestaat, als het een kolom met een vaste lengte is (bijv. een INT), deze altijd de hele kolombreedte op de pagina in beslag zal nemen, zelfs als de kolom is NUL. Als het een kolom met variabele lengte is (bijv. VARCHAR), zal het ten minste twee bytes in de kolom-offset-array gebruiken wanneer NULL, tenzij de kolommen na de laatst gevulde kolom staan (zie Kimberly's blogpost Kolomvolgorde maakt niet uit ... in het algemeen , maar – HET HANGT AF). Een schaarse kolom vereist geen ruimte op de pagina voor NULL-waarden, of het nu een kolom met vaste lengte of variabele lengte is, en ongeacht welke andere kolommen in de tabel zijn ingevuld. De wisselwerking is dat wanneer een schaarse kolom is gevuld, er vier (4) meer bytes aan opslagruimte nodig zijn dan een niet-dunne kolom. Bijvoorbeeld:
| Kolomtype | Opslagvereiste |
|---|---|
| BIGINT-kolom, niet-sparse, met nee waarde | 8 bytes |
| BIGINT-kolom, niet-sparse, met een waarde | 8 bytes |
| BIGINT kolom, dun, met nee waarde | 0 bytes |
| GROTE kolom, dun, met een waarde | 12 bytes |
Daarom is het essentieel om te bevestigen dat het opslagvoordeel opweegt tegen de potentiële prestatiehit van het ophalen - wat verwaarloosbaar kan zijn op basis van de balans tussen lezen en schrijven ten opzichte van de gegevens. De geschatte ruimtebesparing voor verschillende gegevenstypen is gedocumenteerd in de Books Online-link hierboven.
Testscenario's
Ik heb vier verschillende testscenario's opgesteld, die hieronder worden beschreven, en elke tabel had een ID-kolom (INT), een kolom Naam (VARCHAR(100)) en een kolom Type (INT) en vervolgens 997 NULLABLE-kolommen.
| Test-ID | Tabelbeschrijving | DML-bewerkingen |
|---|---|---|
| 1 | 997 kolommen van INT-gegevenstype, NULLABLE, niet-sparse | Voeg één rij tegelijk in, met ID, Naam, Type en tien (10) willekeurige NULLABLE-kolommen |
| 2 | 997 kolommen van INT-gegevenstype, NULLABLE, sparse | Voeg één rij tegelijk in, met ID, Naam, Type en tien (10) willekeurige NULLABLE-kolommen |
| 3 | 997 kolommen van INT-gegevenstype, NULLABLE, niet-sparse | Voeg één rij tegelijk in, vul alleen ID, Naam, Type in, werk de rij bij en voeg waarden toe voor tien (10) willekeurige NULLABLE-kolommen |
| 4 | 997 kolommen van INT-gegevenstype, NULLABLE, sparse | Voeg één rij tegelijk in, vul alleen ID, Naam, Type in, werk de rij bij en voeg waarden toe voor tien (10) willekeurige NULLABLE-kolommen |
| 5 | 997 kolommen van het VARCHAR-gegevenstype, NULLABLE, niet-sparse | Voeg één rij tegelijk in, met ID, Naam, Type en tien (10) willekeurige NULLABLE-kolommen |
| 6 | 997 kolommen van het VARCHAR-gegevenstype, NULLABLE, sparse | Voeg één rij tegelijk in, met ID, Naam, Type en tien (10) willekeurige NULLABLE-kolommen |
| 7 | 997 kolommen van het VARCHAR-gegevenstype, NULLABLE, niet-sparse | Voeg één rij tegelijk in, vul alleen ID, Naam, Type in, werk de rij bij en voeg waarden toe voor tien (10) willekeurige NULLABLE-kolommen |
| 8 | 997 kolommen van het VARCHAR-gegevenstype, NULLABLE, sparse | Voeg één rij tegelijk in, vul alleen ID, Naam, Type in, werk de rij bij en voeg waarden toe voor tien (10) willekeurige NULLABLE-kolommen |
Elke test werd twee keer uitgevoerd met een dataset van 10 miljoen rijen. De bijgevoegde scripts kunnen worden gebruikt om testen te repliceren, en de stappen waren als volgt voor elke test:
- Maak een nieuwe database met vooraf ingestelde gegevens en logbestanden
- Maak de juiste tabel
- Snapshot wachtstatistieken en bestandsstatistieken
- Let op de starttijd
- Voer de DML uit (één invoeging, of één invoeging en één update) voor 10 miljoen rijen
- Let op de stoptijd
- Snapshot wachtstatistieken en bestandsstatistieken en schrijf naar een logtabel in een aparte database op aparte opslag
- Momentopname dm_db_index_physical_stats
- Laat de database vallen
De tests zijn uitgevoerd op een Dell PowerEdge R720 met 64 GB geheugen en 12 GB toegewezen aan de SQL Server 2014 SP1 CU4-instantie. Fusion-IO SSD's werden gebruikt voor gegevensopslag voor de databasebestanden.
Resultaten
Hieronder worden de testresultaten weergegeven voor elk testscenario.
Duur
In alle gevallen kostte het minder tijd (gemiddeld 11,6 minuten) om de tabel te vullen wanneer dunne kolommen werden gebruikt, zelfs toen de rij voor het eerst werd ingevoegd en vervolgens werd bijgewerkt. Toen de rij voor het eerst werd ingevoegd en vervolgens werd bijgewerkt, duurde het bijna twee keer zo lang om de test uit te voeren als toen de rij werd ingevoegd, omdat er twee keer zoveel gegevenswijzigingen werden uitgevoerd.
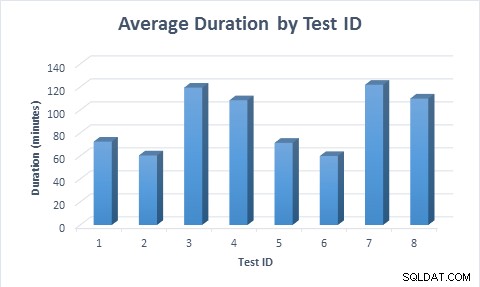 Gemiddelde duur voor elk testscenario
Gemiddelde duur voor elk testscenario
Wachtstatistieken
| Test-ID | Gemiddeld percentage | Gemiddelde wachttijd (seconden) |
|---|---|---|
| 1 | 16.47 | 0.0001 |
| 2 | 14.00 | 0.0001 |
| 3 | 16.65 | 0.0001 |
| 4 | 15.07 | 0.0001 |
| 5 | 12.80 | 0.0001 |
| 6 | 13,99 | 0.0001 |
| 7 | 14,85 | 0.0001 |
| 8 | 15.02 | 0.0001 |
De wachtstatistieken waren consistent voor alle tests en er kunnen geen conclusies worden getrokken op basis van deze gegevens. De hardware voldeed in alle testgevallen voldoende aan de resourcevereisten.
Bestandsstatistieken
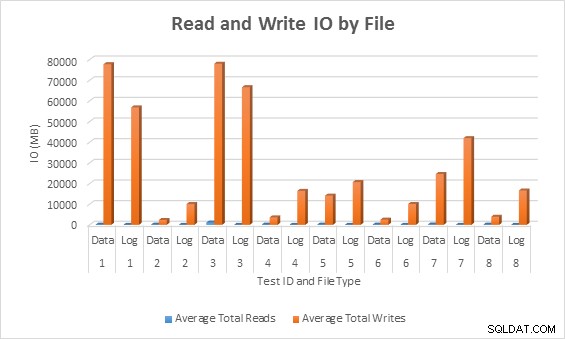 Gemiddelde IO (lezen en schrijven) per databasebestand
Gemiddelde IO (lezen en schrijven) per databasebestand
In alle gevallen genereerden de tests met dunne kolommen minder IO (met name schrijfbewerkingen) in vergelijking met niet-sparse kolommen.
Fysieke statistieken indexeren
| Testcase | Aantal rijen | Totaal aantal pagina's (geclusterde index) | Totale ruimte (GB) | Gemiddelde ruimte die wordt gebruikt voor bladpagina's in CI (%) | Gemiddelde recordgrootte (bytes) |
|---|---|---|---|---|---|
| 1 | 10.000.000 | 10.037.312 | 76 | 51.70 | 4.184,49 |
| 2 | 10.000.000 | 301.429 | 2 | 98.51 | 237,50 |
| 3 | 10.000.000 | 10.037.312 | 76 | 51.70 | 4.184,50 |
| 4 | 10.000.000 | 460.960 | 3 | 64.41 | 237,50 |
| 5 | 10.000.000 | 1.823.083 | 13 | 90.31 | 1.326.08 |
| 6 | 10.000.000 | 324.162 | 2 | 98,40 | 255,28 |
| 7 | 10.000.000 | 3.161.224 | 24 | 52.09 | 1.326.39 |
| 8 | 10.000.000 | 503.592 | 3 | 63.33 | 255,28 |
Er zijn significante verschillen in ruimtegebruik tussen de niet-sparse en sparse tabellen. Dit valt het meest op als we kijken naar testgevallen 1 en 3, waar een datatype met vaste lengte werd gebruikt (INT), vergeleken met testgevallen 5 en 7, waar een datatype met variabele lengte werd gebruikt (VARCHAR(255)). De integer-kolommen nemen schijfruimte in beslag, zelfs wanneer NULL. De kolommen met variabele lengte verbruiken minder schijfruimte, aangezien er slechts twee bytes worden gebruikt in de offset-array voor NULL-kolommen en geen bytes voor de NULL-kolommen die na de laatst gevulde kolom in de rij staan.
Verder veroorzaakt het proces van het invoegen van een rij en het bijwerken ervan fragmentatie voor de kolomtest met variabele lengte (geval 7), vergeleken met het eenvoudig invoegen van de rij (geval 5). De tabelgrootte verdubbelt bijna wanneer de invoeging wordt gevolgd door de update, vanwege paginasplitsingen die optreden bij het bijwerken van de rijen, waardoor de pagina's halfvol blijven (tegenover 90% vol).
Samenvatting
Concluderend zien we een significante vermindering van schijfruimte en IO wanneer dunne kolommen worden gebruikt, en ze presteren iets beter dan niet-sparse kolommen in onze eenvoudige gegevensmodificatietests (merk op dat de ophaalprestaties ook moeten worden overwogen; misschien het onderwerp van een andere bericht).
Dunne kolommen hebben een zeer specifiek gebruiksscenario en het is belangrijk om de hoeveelheid bespaarde schijfruimte te onderzoeken op basis van het gegevenstype voor de kolom en het aantal kolommen dat doorgaans in de tabel wordt ingevuld. In ons voorbeeld hadden we 997 dunne kolommen en we hebben er slechts 10 ingevuld. In het geval dat het gebruikte gegevenstype een geheel getal was, zou een rij op bladniveau van de geclusterde index maximaal 188 bytes verbruiken (4 bytes voor de ID, 100 bytes max voor de naam, 4 bytes voor het type en vervolgens 80 bytes voor 10 kolommen). Toen 997 kolommen niet-sparse waren, werden 4 bytes toegewezen voor elke kolom, zelfs als NULL, dus elke rij was minstens 4.000 bytes op het bladniveau. In ons scenario zijn dunne kolommen absoluut acceptabel. Maar als we 500 of meer schaarse kolommen vullen met waarden voor een INT-kolom, gaat de ruimtebesparing verloren en zijn de modificatieprestaties mogelijk niet langer beter.
Afhankelijk van het gegevenstype voor uw kolommen en het verwachte aantal kolommen dat van het totaal moet worden gevuld, kunt u soortgelijke tests uitvoeren om ervoor te zorgen dat, wanneer u dunne kolommen gebruikt, de prestaties en opslag van invoegingen vergelijkbaar of beter zijn dan wanneer u niet -dunne kolommen. Voor gevallen waarin niet alle kolommen zijn gevuld, zijn dunne kolommen zeker het overwegen waard.