Een paar weken geleden heb ik een behoorlijk grote deal gesloten over SQL Server 2016 Service Pack 1. Veel functies die voorheen waren gereserveerd voor Enterprise Edition, zijn beschikbaar gemaakt voor lagere edities, en ik was opgetogen over deze wijzigingen.
Toch zie ik een paar mensen die, laten we zeggen, iets minder opgewonden zijn dan ik.
Het is belangrijk om in gedachten te houden dat de wijzigingen hier niet bedoeld waren om volledige functiepariteit in alle edities te bieden; ze waren specifiek bedoeld om een meer consistent programmeeroppervlak te creëren. Nu kunnen klanten functies zoals In-Memory OLTP, Columnstore en compressie gebruiken zonder zich zorgen te maken over de beoogde editie(s) - alleen over hoe goed ze zullen schalen. Verschillende beveiligingsfuncties die niet echt iets met editie te maken leken te hebben, worden ook geopend. Degene die ik het minst begreep was Always Encrypted; Ik begreep niet waarom alleen Enterprise-klanten zaken als creditcardgegevens moesten beschermen. Transparante gegevensversleuteling is nog steeds alleen voor ondernemingen, op eerdere versies dan SQL Server 2019, omdat dit niet echt een programmeerfunctie is (of het is ingeschakeld of niet).
Dus wat zit er echt in voor Standard Edition-klanten?
Ik denk dat het grootste probleem dat de meeste mensen hebben, is dat het maximale geheugen in de Standard Edition nog steeds beperkt is tot 128 GB. Ze kijken ernaar en zeggen:"Goh, bedankt voor alle functies, maar door de geheugenlimiet kan ik ze niet echt gebruiken."
De oppervlakteveranderingen brengen echter mogelijkheden voor prestatieverbetering met zich mee, zelfs als dat niet hun oorspronkelijke bedoeling was (of zelfs als dat zo was - ik was niet in een van die vergaderingen). Laten we een klein gedeelte van de kleine lettertjes (uit de officiële documenten) eens nader bekijken:
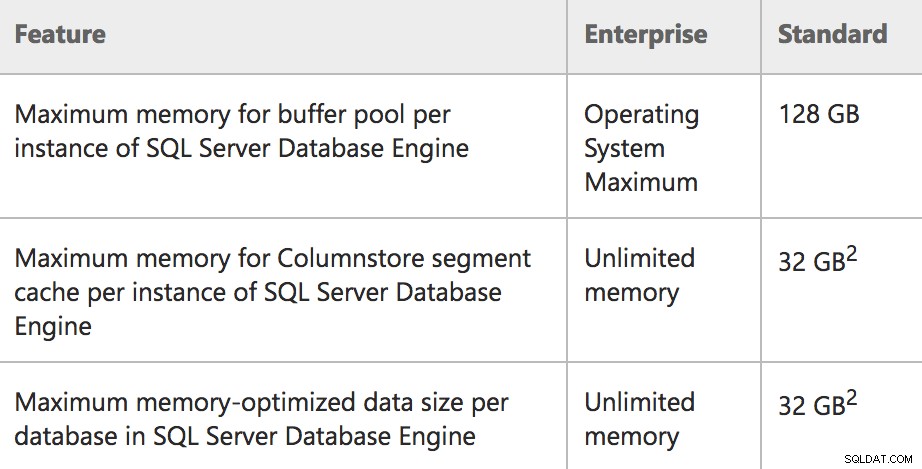 Geheugenlimieten voor Enterprise/Standard in SQL Server 2016 SP1
Geheugenlimieten voor Enterprise/Standard in SQL Server 2016 SP1
De oplettende lezer zal merken dat de formulering van de bufferpoollimiet is gewijzigd, van:
Geheugen:Maximaal gebruikt geheugen per instantieAan:
Geheugen:Maximale bufferpoolgrootte per instantieDit is een betere beschrijving van wat er werkelijk gebeurt in Standard Edition:een limiet van 128 GB voor alleen de bufferpool, en andere geheugenreserveringen kunnen daarbovenop komen (denk aan pools zoals de plancache). Dus in feite zou een Standard Edition-server 128 GB bufferpool kunnen gebruiken, dan kan het maximale servergeheugen hoger zijn en meer geheugen ondersteunen dat wordt gebruikt voor andere reserveringen. Evenzo is Express Edition nu correct gedocumenteerd om 1,4 GB voor de bufferpool te gebruiken.
Mogelijk ziet u ook een aantal zeer specifieke bewoordingen in die meest linkse kolom (bijv. "per instantie" en "per database") voor de functies die voor het eerst in de Standaardeditie worden weergegeven. Om specifieker te zijn:
- De instantie is beperkt tot 128 GB geheugen voor de bufferpool .
- De instantie kan een extra . hebben 32 GB toegewezen aan Columnstore-objecten, boven de bufferpoollimiet.
- Elke gebruikersdatabase op de instantie kan een extra . hebben 32 GB toegewezen aan voor geheugen geoptimaliseerde tabellen, boven de bufferpoollimiet.
En om glashelder te zijn:Deze geheugenlimieten voor ColumnStore en In-Memory OLTP worden NIET afgetrokken van de bufferpoollimiet , zolang de server meer dan 128 GB geheugen beschikbaar heeft. Als de server minder dan 128 GB heeft, zult u zien dat deze technologieën concurreren met bufferpoolgeheugen en in feite worden beperkt tot een % van het maximale servergeheugen. Meer details zijn beschikbaar in dit bericht van Microsoft's Parikshit Savjani.
Ik heb geen hardware bij de hand om de omvang hiervan te testen, maar als je een machine had met 256 GB of 512 GB geheugen, zou je in theorie alles kunnen gebruiken met een enkele Standard Edition-instantie, als je - bijvoorbeeld - je In -Geheugengegevens in databases in <=32GB chunks, voor een totaal van 128GB + (32GB * (# databases)). Als u ColumnStore wilt gebruiken in plaats van In-Memory, kunt u uw gegevens over meerdere instanties spreiden, waardoor u (128 GB + 32 GB) * (aantal instanties) krijgt. En je zou deze strategieën kunnen combineren voor ((128GB + 32GB ColumnStore) * (# instances)) + (32GB In-Memory * (# of databases * # instances)).
Of het op deze manier opsplitsen van uw gegevens praktisch is voor uw toepassing, weet ik niet zeker; Ik suggereer alleen dat het mogelijk is. Sommigen van jullie doen misschien al een aantal van deze dingen om de Standard Edition beter te gebruiken op servers met meer dan 128 GB geheugen.
Houd er met ColumnStore in het bijzonder rekening mee dat u niet alleen 32 GB mag gebruiken naast de bufferpool, maar ook dat de compressie die u hier kunt krijgen, betekent dat u vaak veel meer in die limiet van 32 GB kunt passen dan met dezelfde gegevens in traditionele rij-winkel. En als u ColumnStore om welke reden dan ook niet kunt gebruiken (of het past nog steeds niet in 32 GB), kunt u nu traditionele pagina- of rijcompressie implementeren - hierdoor kunt u misschien niet uw hele database in de bufferpool van 128 GB passen, maar hierdoor kunnen er op elk moment meer van uw gegevens in het geheugen staan.
Soortgelijke dingen zijn mogelijk in Express (op een lagere schaal), waar u 1,4 GB voor bufferpool kunt hebben, maar een extra ~352MB per instantie voor ColumnStore en ~352MB per database voor In-Memory OLTP.
Maar Enterprise Edition heeft nog steeds veel voordelen
Er zijn veel andere onderscheidende factoren om interesse in Enterprise Edition te behouden, afgezien van onbeperkte geheugenlimieten overal - van online rebuilds en draaimolenscans tot volledige beschikbaarheidsgroepen en alle virtualisatierechten waar u maar een stokje voor kunt steken. Zelfs ColumnStore-indexen hebben goed gedefinieerde prestatieverbeteringen die zijn gereserveerd voor Enterprise Edition.
Dus alleen omdat er enkele technieken zijn waarmee u meer uit de Standard Edition kunt halen, betekent dat niet dat het op magische wijze zal worden geschaald om aan uw prestatiebehoeften te voldoen. Net als mijn andere berichten over "het doen met een beperkt budget" (bijv. partitionering en leesbare secondaries), kun je zeker tijd en moeite steken in het bedenken van een oplossing, maar het zal je alleen tot nu toe brengen. Het doel van dit bericht was gewoon om aan te tonen dat je met Standard Edition in 2016 SP1 verder kunt komen dan ooit tevoren.