Scalaire UDF's zijn altijd een tweesnijdend zwaard geweest - ze zijn geweldig voor ontwikkelaars, die vervelende logica kunnen abstraheren in plaats van deze overal in hun query's te herhalen, maar ze zijn verschrikkelijk voor runtime-prestaties in productie, omdat de optimizer dat niet doet. t behandelen ze mooi. Wat er in wezen gebeurt, is dat de UDF-uitvoeringen gescheiden worden gehouden van de rest van het uitvoeringsplan, en dus worden ze één keer aangeroepen voor elke rij en kunnen ze niet worden geoptimaliseerd op basis van het geschatte of werkelijke aantal rijen of in de rest van het plan worden gevouwen.
Aangezien we, ondanks onze inspanningen sinds SQL Server 2000, het gebruik van scalaire UDF's niet effectief kunnen stoppen, zou het niet geweldig zijn om SQL Server er gewoon beter mee om te laten gaan?
SQL Server 2019 introduceert een nieuwe functie genaamd Scalar UDF Inlining. In plaats van de functie gescheiden te houden, wordt deze opgenomen in het totaalplan. Dit leidt tot een veel beter uitvoeringsplan en, op zijn beurt, betere runtime-prestaties.
Maar laten we eerst, om de oorzaak van het probleem beter te illustreren, beginnen met een paar eenvoudige tabellen met slechts een paar rijen, in een database die draait op SQL Server 2017 (of op 2019 maar met een lager compatibiliteitsniveau):
CREATE DATABASE Whatever; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 140; GO USE Whatever; GO CREATE TABLE dbo.Languages ( LanguageID int PRIMARY KEY, Name sysname ); CREATE TABLE dbo.Employees ( EmployeeID int PRIMARY KEY, LanguageID int NOT NULL FOREIGN KEY REFERENCES dbo.Languages(LanguageID) ); INSERT dbo.Languages(LanguageID, Name) VALUES(1033, N'English'), (45555, N'Klingon'); INSERT dbo.Employees(EmployeeID, LanguageID) SELECT [object_id], CASE ABS([object_id]%2) WHEN 1 THEN 1033 ELSE 45555 END FROM sys.all_objects;
Nu hebben we een eenvoudige zoekopdracht waarbij we elke werknemer en de naam van hun primaire taal willen tonen. Laten we zeggen dat deze query op veel plaatsen en/of op verschillende manieren wordt gebruikt, dus in plaats van een join in de query in te bouwen, schrijven we een scalaire UDF om die join te abstraheren:
CREATE FUNCTION dbo.GetLanguage(@id int) RETURNS sysname AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END
Dan ziet onze eigenlijke vraag er ongeveer zo uit:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
Als we kijken naar het uitvoeringsplan voor de query, ontbreekt er iets vreemds:
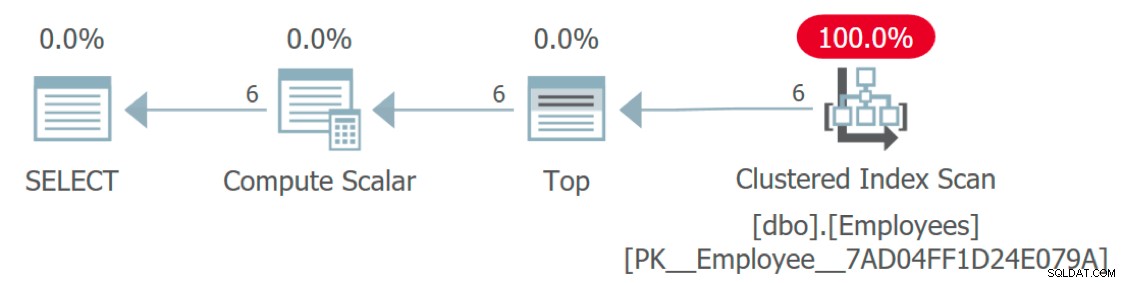 Uitvoeringsplan met toegang tot werknemers maar niet tot talen
Uitvoeringsplan met toegang tot werknemers maar niet tot talen
Hoe wordt de tabel Talen geopend? Dit plan ziet er zeer efficiënt uit omdat het - net als de functie zelf - een deel van de complexiteit wegneemt. In feite is dit grafische plan identiek aan een zoekopdracht die alleen een constante of variabele toewijst aan de Language kolom:
SELECT TOP (6) EmployeeID, Language = N'Sanskrit' FROM dbo.Employees;
Maar als u een tracering uitvoert tegen de oorspronkelijke query, ziet u dat er naast de hoofdquery in feite zes aanroepen naar de functie zijn (één voor elke rij), maar deze plannen worden niet geretourneerd door SQL Server.
U kunt dit ook controleren door sys.dm_exec_function_stats . aan te vinken , maar dit is geen garantie :
SELECT [function] = OBJECT_NAME([object_id]), execution_count FROM sys.dm_exec_function_stats WHERE object_name(object_id) IS NOT NULL;
function execution_count ----------- --------------- GetLanguage 6
SentryOne Plan Explorer zal de verklaringen tonen als u een echt plan vanuit het product genereert, maar we kunnen die alleen verkrijgen van trace, en er zijn nog steeds geen plannen verzameld of getoond voor de individuele functie-aanroepen:
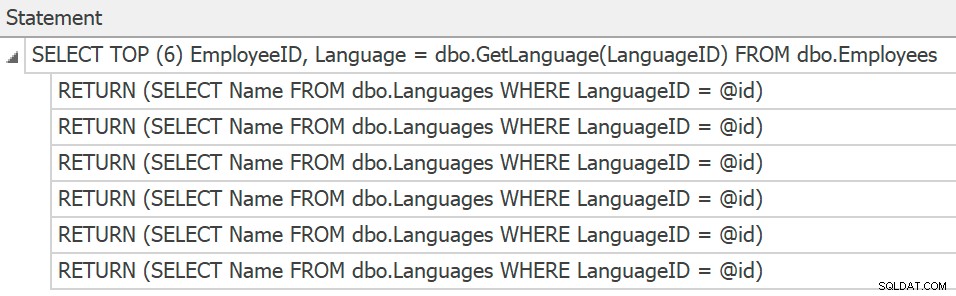 Trace-instructies voor individuele scalaire UDF-aanroepen
Trace-instructies voor individuele scalaire UDF-aanroepen
Dit maakt het allemaal erg moeilijk om problemen op te lossen, omdat je ze moet gaan opsporen, zelfs als je al weet dat ze er zijn. Het kan ook een hele boel prestatie-analyse opleveren als je twee plannen vergelijkt op basis van zaken als geschatte kosten, omdat niet alleen de relevante operators zich verbergen voor het fysieke diagram, maar de kosten ook nergens in het plan zijn opgenomen.
Snel vooruitspoelen naar SQL Server 2019
Na al die jaren van problematisch gedrag en obscure onderliggende oorzaken, hebben ze het zo gemaakt dat sommige functies kunnen worden geoptimaliseerd in het algehele uitvoeringsplan. Scalaire UDF Inlining maakt de objecten waartoe ze toegang hebben zichtbaar voor het oplossen van problemen *en* stelt ze in staat om ze op te vouwen in de uitvoeringsplanstrategie. Kardinaliteitsschattingen (gebaseerd op statistieken) maken nu samenvoegstrategieën mogelijk die gewoon niet mogelijk waren toen de functie eenmaal voor elke rij werd aangeroepen.
We kunnen hetzelfde voorbeeld gebruiken als hierboven, of dezelfde set objecten maken op een SQL Server 2019-database, of de plancache opschonen en het compatibiliteitsniveau verhogen naar 150:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO ALTER DATABASE Whatever SET COMPATIBILITY_LEVEL = 150; GO
Als we nu onze zes-rij-query opnieuw uitvoeren:
SELECT TOP (6) EmployeeID, Language = dbo.GetLanguage(LanguageID) FROM dbo.Employees;
We krijgen een plan met de tabel Talen en de kosten die gepaard gaan met toegang:
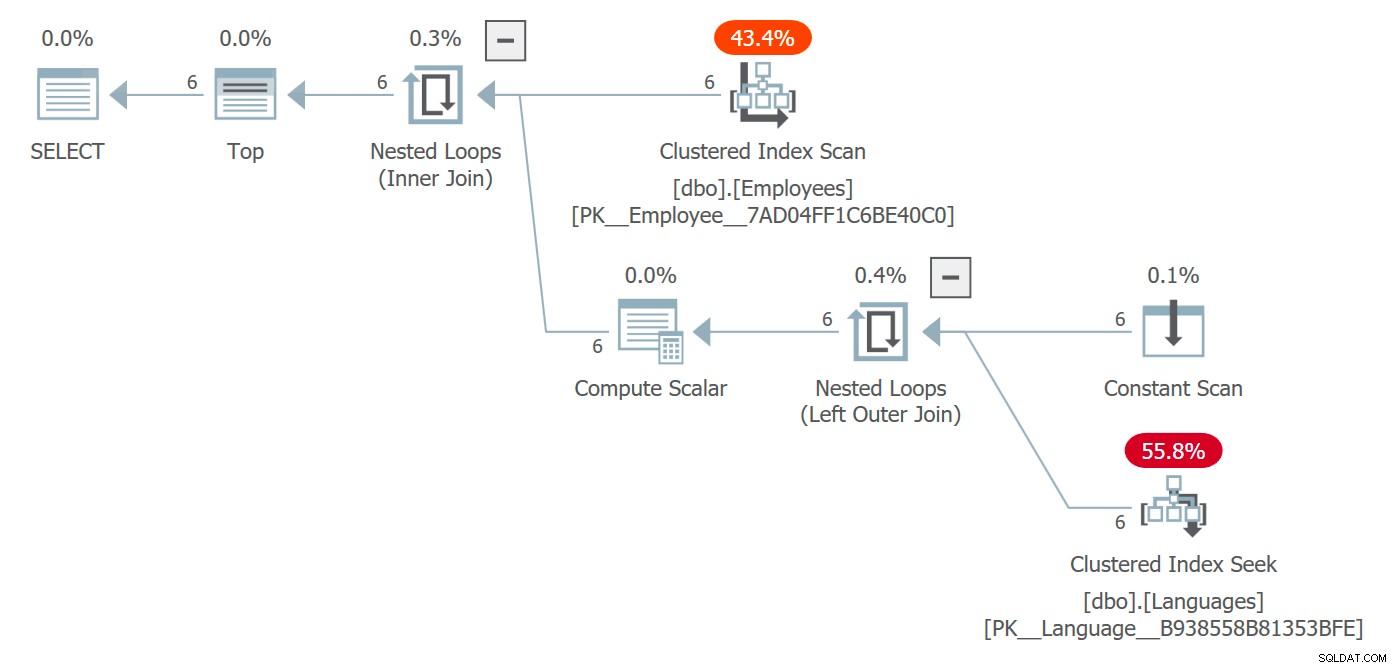 Plan met toegang tot objecten waarnaar wordt verwezen in scalaire UDF
Plan met toegang tot objecten waarnaar wordt verwezen in scalaire UDF
Hier koos de optimizer voor een geneste lusverbinding, maar onder andere omstandigheden had hij een andere verbindingsstrategie kunnen kiezen, parallellisme overwogen en in wezen vrij zijn geweest om de vorm van het plan volledig te veranderen. U zult dit waarschijnlijk niet zien in een query die 6 rijen retourneert en op geen enkele manier een prestatieprobleem is, maar op grotere schaal zou het kunnen.
Het plan geeft aan dat de functie niet per rij wordt aangeroepen - terwijl de zoekopdracht eigenlijk zes keer wordt uitgevoerd, kun je zien dat de functie zelf niet langer wordt weergegeven in sys.dm_exec_function_stats . Een nadeel dat u kunt wegnemen, is dat als u deze DMV gebruikt om te bepalen of een functie actief wordt gebruikt (zoals we vaak doen voor procedures en indexen), deze niet langer betrouwbaar zal zijn.
Voorbehoud
Niet elke scalaire functie is inlineable en zelfs wanneer een functie *inlineable is*, zal deze niet noodzakelijk in elk scenario inline zijn. Dit heeft vaak te maken met de complexiteit van de functie, de complexiteit van de betreffende query of de combinatie van beide. U kunt controleren of een functie inlineable is in de sys.sql_modules catalogusweergave:
SELECT OBJECT_NAME([object_id]), definition, is_inlineable FROM sys.sql_modules;
En als u, om welke reden dan ook, niet wilt dat een bepaalde functie (of een functie in een database) inline is, hoeft u niet te vertrouwen op het compatibiliteitsniveau van de database om dat gedrag te beheersen. Ik heb nooit van die losse koppeling gehouden, die verwant is aan het wisselen van kamer om een ander televisieprogramma te kijken in plaats van simpelweg van kanaal te veranderen. U kunt dit op moduleniveau regelen met de INLINE-optie:
ALTER FUNCTION dbo.GetLanguage(@id int) RETURNS sysname WITH INLINE = OFF AS BEGIN RETURN (SELECT Name FROM dbo.Languages WHERE LanguageID = @id); END GO
En u kunt dit op databaseniveau regelen, maar los van het compatibiliteitsniveau:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
Hoewel je een behoorlijk goede use case moet hebben om met die hamer te zwaaien, IMHO.
Conclusie
Nu, ik suggereer niet dat je elk stukje logica kunt abstraheren in een scalaire UDF, en aannemen dat SQL Server nu gewoon voor alle gevallen zorgt. Als u een database heeft met veel scalar UDF-gebruik, moet u de nieuwste SQL Server 2019 CTP downloaden, een back-up van uw database daar herstellen en de DMV controleren om te zien hoeveel van die functies inlineable zullen zijn wanneer de tijd daar is. Het kan een belangrijk punt zijn voor de volgende keer dat u pleit voor een upgrade, aangezien u in wezen al die prestaties en verspilde tijd voor het oplossen van problemen terugkrijgt.
Als je in de tussentijd last hebt van scalaire UDF-prestaties en je zult niet snel upgraden naar SQL Server 2019, dan zijn er misschien andere manieren om het probleem of de problemen te verhelpen.
Opmerking:ik heb dit artikel geschreven en in de wachtrij geplaatst voordat ik me realiseerde dat ik al een ander stuk elders had gepost.