Tijdens het bewaken van de prestaties of het oplossen van problemen zoals systeemtraagheid, kan het nodig zijn om query's te vinden of vast te leggen die een lange duur hebben, een hoge CPU hebben of significante I/O genereren tijdens de uitvoering. U kunt de DMV's of Query Store gebruiken om informatie te krijgen over de prestaties van query's, maar de informatie in beide bronnen is een aggregaat. De DMV's vertegenwoordigen de gemiddelde CPU, I/O, duur, enz. voor een query alleen zolang deze zich in de cache bevindt. Query Store biedt ook gemiddelde statistieken voor tal van bronnen, maar deze worden geaggregeerd over een bepaalde tijdsperiode (bijvoorbeeld 30 minuten of een uur). Er zijn natuurlijk monitoringoplossingen van derden die je dit alles en meer kunnen bieden (zoals SentryOne), maar voor dit bericht wilde ik me concentreren op native tools.
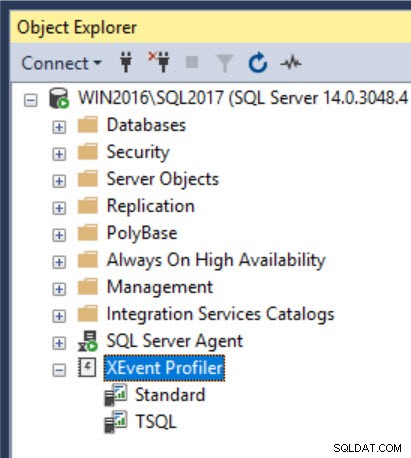
Als u de prestaties van query's voor afzonderlijke uitvoeringen wilt begrijpen om de exacte query of reeks query's te lokaliseren die mogelijk een probleem vormen, is de eenvoudigste optie om Extended Events te gebruiken. En een van de snelste manieren om aan de slag te gaan, is door XEvent Profiler te gebruiken, dat beschikbaar is via SQL Server Management Studio (vanaf versie 17.3):
 XEvent Profiler in SSMS
XEvent Profiler in SSMS
Basisgebruik
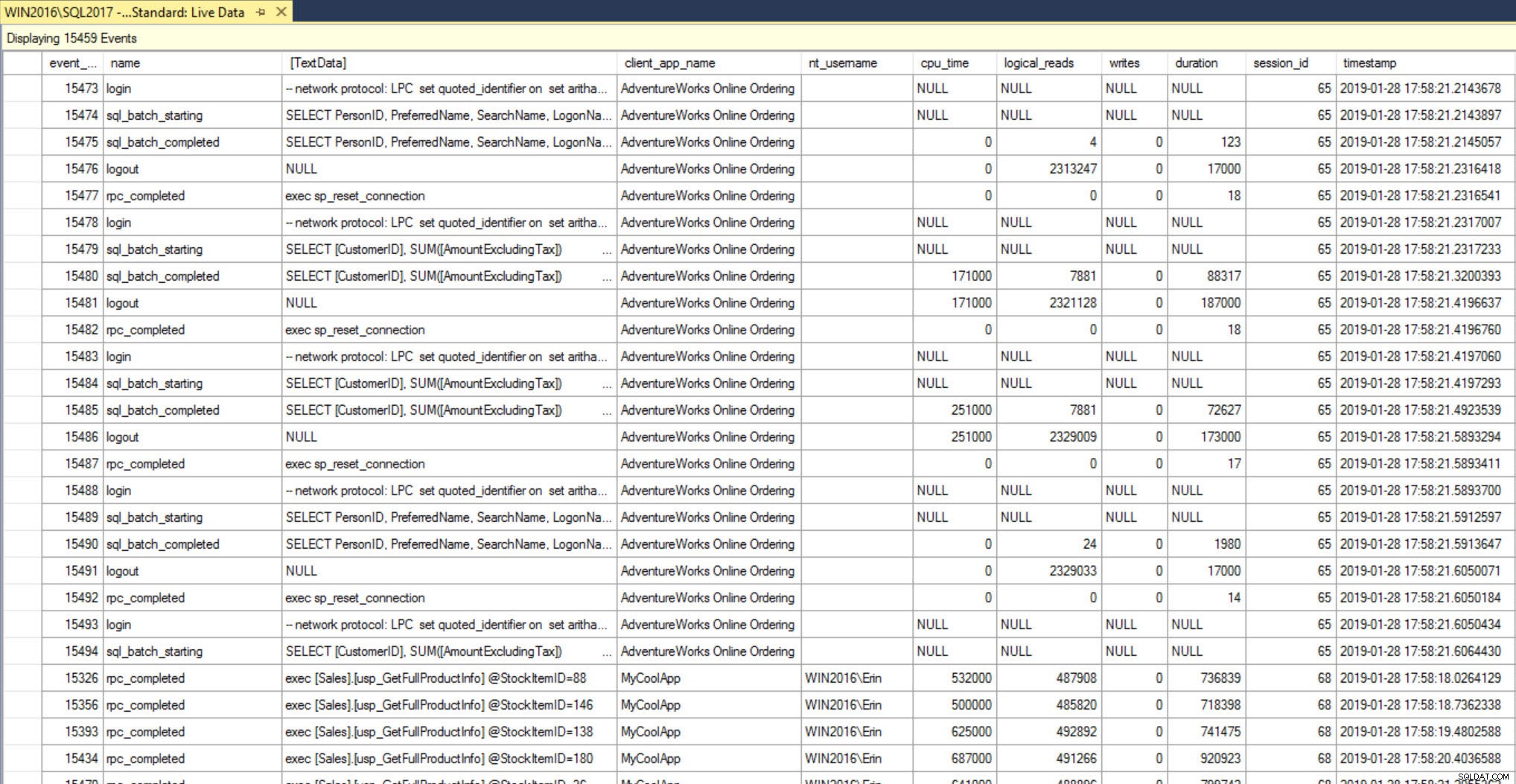
Er zijn twee opties voor XEvent Profiler:Standard en TSQL. Dubbelklik op de naam om een van beide te gebruiken. Achter de schermen wordt een intern gedefinieerde gebeurtenissessie gemaakt (als deze nog niet bestaat) en gestart, en de Live Data Viewer wordt onmiddellijk geopend met focus. Houd er rekening mee dat nadat je de sessie hebt gestart, deze ook zal verschijnen onder Beheer | Uitgebreide evenementen | Sessies. Ervan uitgaande dat u activiteit tegen de server heeft, zouden de items binnen vijf seconden of minder in de viewer moeten verschijnen.
 Live Data Viewer (na dubbelklikken om de standaardsessie te starten)
Live Data Viewer (na dubbelklikken om de standaardsessie te starten)
De Standard- en TSQL-sessies delen enkele evenementen, terwijl de Standard in totaal meer heeft. Hier is een lijst van de evenementen voor elk:
Standard TSQL
sql_batch_starting sql_batch_starting
sql_batch_completed
rpc_starting
rpc_completed
logout logout
login login
existing_connection existing_connection
attention Als u informatie wilt over het uitvoeren van query's, zoals hoe lang het duurde om de query uit te voeren of hoeveel I/O het kostte, dan is Standard een betere optie vanwege de twee voltooide gebeurtenissen. Voor beide sessies is het enige filter het uitsluiten van systeemquery's voor de batch-, rpc- en aandachtsgebeurtenissen.
Gegevens bekijken en opslaan
Als we de Standard-sessie starten en enkele query's uitvoeren, zien we in de viewer de gebeurtenis, de querytekst en andere nuttige informatie zoals de cpu_time, logische_reads en duur. Een van de voordelen van het gebruik van rpc_completed en sql_batch_completed is dat de invoerparameter wordt weergegeven. In het geval dat er een opgeslagen procedure is die grote variaties in prestaties heeft, kan het vastleggen van de invoerparameter uiterst nuttig zijn, omdat we een uitvoering die langer duurt, kunnen matchen met een specifieke waarde die wordt doorgegeven aan de opgeslagen procedure. Om zo'n parameter te vinden, moeten we de gegevens sorteren op duur, wat we niet kunnen doen wanneer de gegevensfeed actief is. Om enige vorm van analyse uit te voeren, moet de datafeed worden gestopt.
 De gegevensfeed in de Live Viewer stoppen
De gegevensfeed in de Live Viewer stoppen
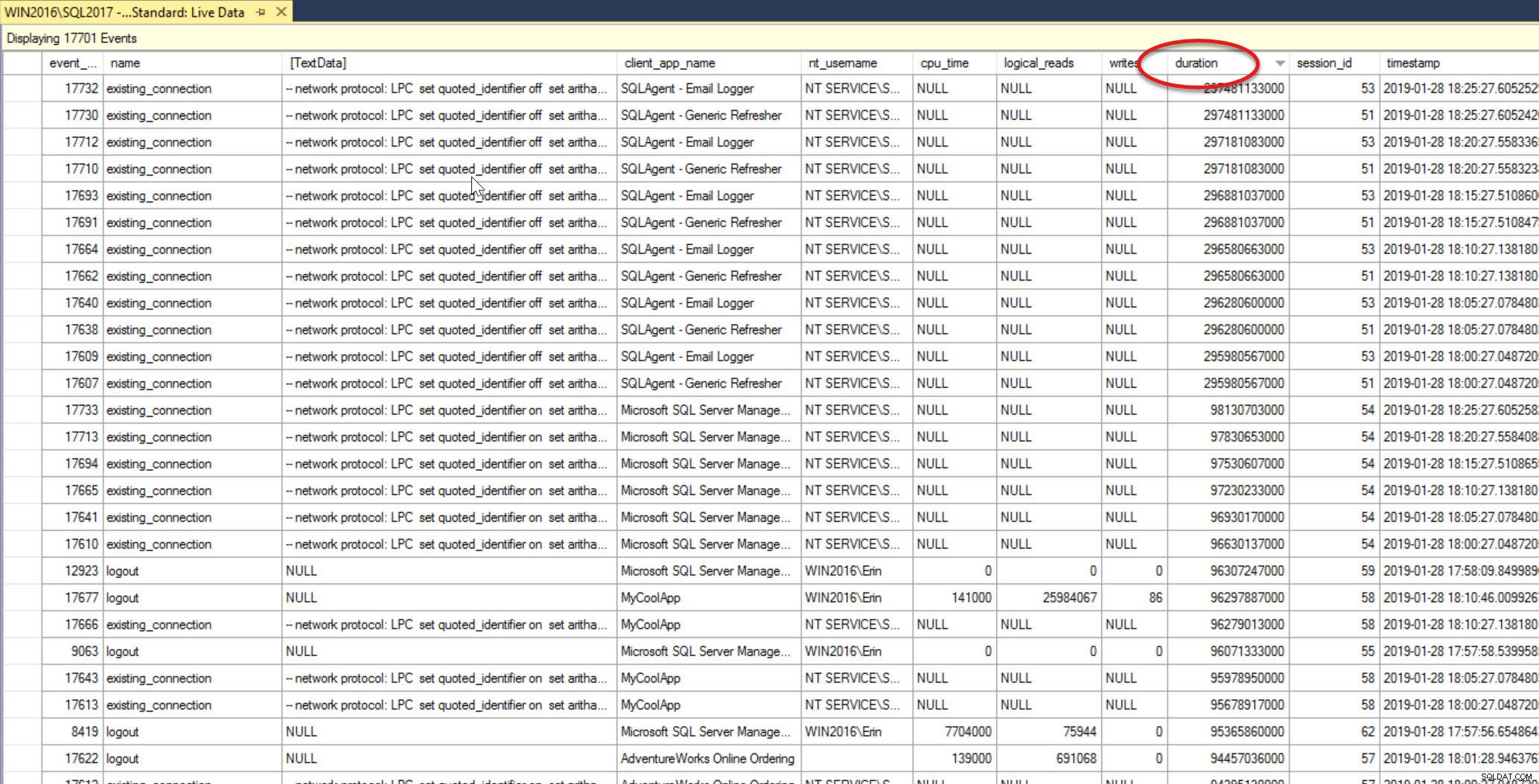
Nu mijn zoekopdrachten niet langer in een waas voorbij rollen, kan ik op de duurkolom klikken om mijn evenementen te sorteren. De eerste keer dat ik erop klik, wordt het in oplopende volgorde gesorteerd en omdat ik lui ben en niet naar beneden wil scrollen, klik ik opnieuw om in aflopende volgorde te sorteren.
 Evenementen gesorteerd op duur aflopend
Evenementen gesorteerd op duur aflopend
Nu kan ik alle gebeurtenissen zien die ik heb vastgelegd in volgorde van de hoogste duur naar de laagste. Als ik op zoek was naar een specifieke opgeslagen procedure die traag was, zou ik ofwel naar beneden kunnen scrollen totdat ik het vind (wat pijnlijk kan zijn), of ik zou de gegevens kunnen groeperen of filteren. Groeperen is hier gemakkelijker, omdat ik de naam van de opgeslagen procedure ken.
De object_name wordt weergegeven in het bovenste deel van de viewer, maar als u op een rpc_completed-gebeurtenis klikt, worden alle elementen weergegeven die zijn vastgelegd in het detailvenster. Klik met de rechtermuisknop op object_name, die het zal markeren, en selecteer Kolom in tabel weergeven.
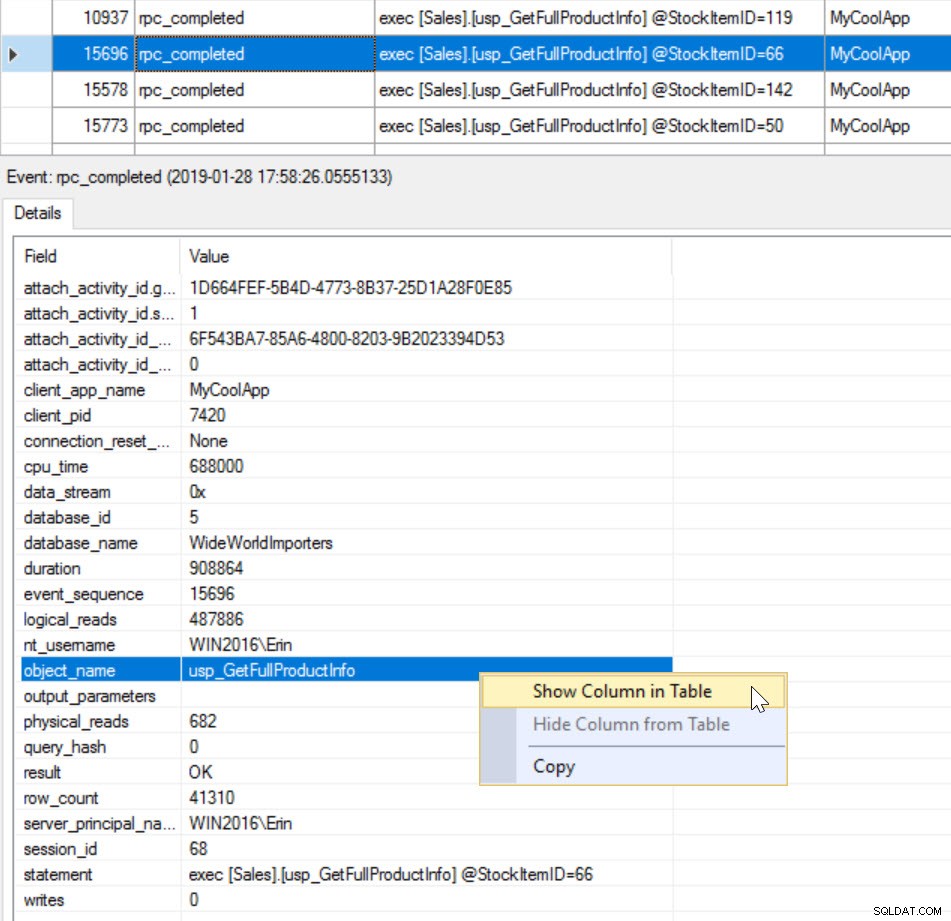 Voeg objectnaam toe aan gegevensviewer
Voeg objectnaam toe aan gegevensviewer
In het bovenste deelvenster kan ik nu met de rechtermuisknop op objectnaam klikken en Groeperen op deze kolom selecteren. Als ik de gebeurtenissen onder usp_GetPersonInfo uitbreid en opnieuw sorteer op duur, zie ik nu dat de uitvoering met PersonID=3133 de hoogste duur had.
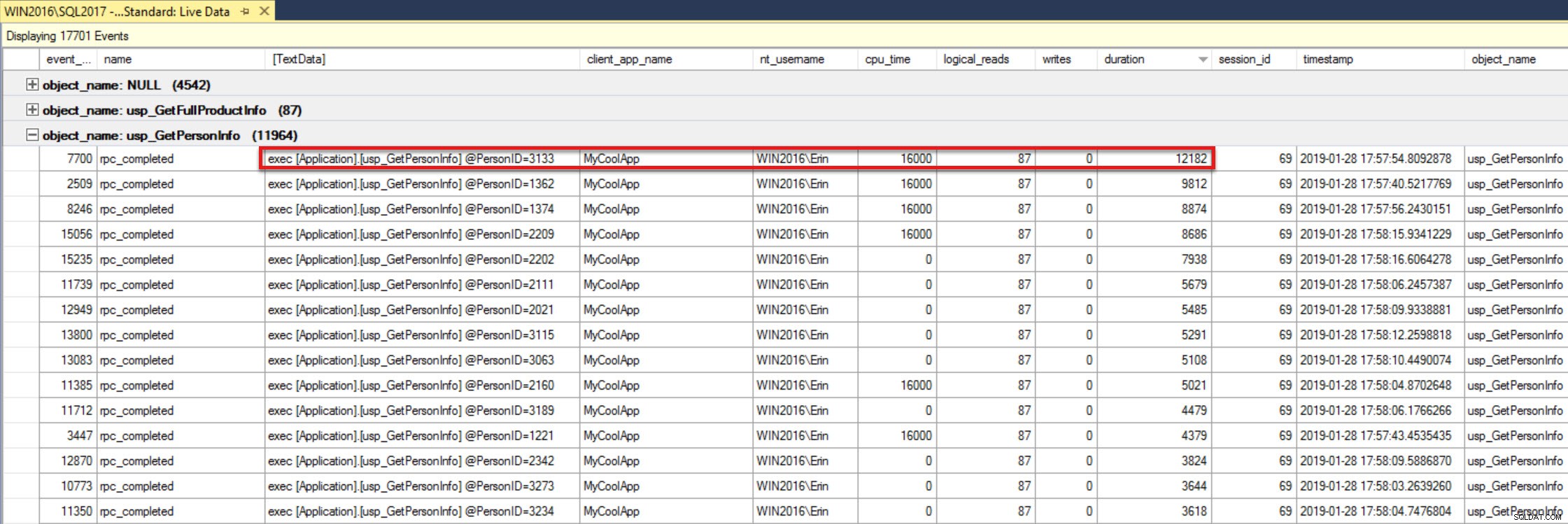 Evenementen gegroepeerd op objectnaam, usp_GetPersonInfo gesorteerd op duur aflopend
Evenementen gegroepeerd op objectnaam, usp_GetPersonInfo gesorteerd op duur aflopend
Om de gegevens te filteren:Gebruik de knop Filters..., de menuoptie (Uitgebreide gebeurtenissen | Filters...), of CTRL + R om een venster te openen om de resultatenset te verkleinen op basis van de verschillende weergegeven velden. In dit geval hebben we gefilterd op object_name =usp_GetPersonInfo, maar u kunt ook filteren op velden zoals server_principal_name of client_app_name, aangezien deze zijn verzameld.
Het is de moeite waard erop te wijzen dat noch de Standard- of TSQL-sessie naar een bestand schrijft. In feite is er geen doel voor beide evenementsessies (als je niet wist dat je een evenementsessie zonder doel kunt maken, weet je het nu). Als u deze gegevens voor verdere analyse wilt opslaan, moet u een van de volgende dingen doen:
- Stop de datafeed en sla de uitvoer op in een bestand via het menu Uitgebreide gebeurtenissen (Exporteren naar | XEL-bestand...)
- Stop de datafeed en sla de uitvoer op in een tabel in een database via het menu Uitgebreide gebeurtenissen (Exporteren naar | Tabel...)
- Wijzig de gebeurtenissessie en voeg het gebeurtenisbestand toe als een doel.
Optie 1 is mijn aanbeveling, omdat het een bestand op schijf maakt dat u met anderen kunt delen en later in Management Studio kunt bekijken voor verdere analyse. Binnen Management Studio heb je de mogelijkheid om gegevens uit te filteren die niet relevant zijn, te sorteren op een of meer kolommen, de gegevens te groeperen en berekeningen uit te voeren (bijvoorbeeld gemiddelden). U kunt dit doen als de gegevens een tabel zijn, maar u moet de TSQL schrijven; het analyseren van de gegevens in de gebruikersinterface is eenvoudiger en sneller.
De XEvent Profiler-sessies wijzigen
U kunt de Standard- en TSQL-gebeurtenissessies wijzigen en de wijzigingen die u aanbrengt, blijven behouden tijdens het opnieuw opstarten van de instantie. Als de gebeurtenissessies echter worden verwijderd (nadat u wijzigingen hebt aangebracht), worden ze teruggezet naar de standaardwaarden. Als u merkt dat u voortdurend dezelfde wijzigingen aanbrengt, raad ik u aan de wijzigingen uit te schrijven en een nieuwe gebeurtenissessie te maken die ook bij het opnieuw opstarten blijft bestaan. Als we bijvoorbeeld kijken naar de uitvoer die tot nu toe is vastgelegd, kunnen we zien dat zowel ad-hocquery's als opgeslagen procedures zijn uitgevoerd. En hoewel het geweldig is dat ik de verschillende invoerparameters voor de opgeslagen procedures kan zien, zie ik niet de individuele instructies die met deze reeks gebeurtenissen worden uitgevoerd. Om die informatie te krijgen, zou ik de sp_statement_completed-gebeurtenis moeten toevoegen.
Begrijp dat zowel de Standard- als de TSQL-evenementsessies zijn ontworpen om lichtgewicht te zijn. De gebeurtenissen statement_completed worden vaker geactiveerd dan de batch- en rpc-gebeurtenissen, dus er kan meer overhead zijn wanneer deze gebeurtenissen deel uitmaken van een gebeurtenissessie. Bij het gebruik van statement events, ik zeer raden aan om aanvullende predikaten op te nemen. Ter herinnering:de rpc- en batchgebeurtenissen filteren alleen systeemquery's uit - er is geen ander predikaat. Over het algemeen raad ik ook aanvullende predikaten aan voor deze gebeurtenissen, vooral voor een hoge werkbelasting.
Als u zich zorgen maakt of het uitvoeren van de standaard- of TSQL-sessies een prestatieverlies op uw systeem zal veroorzaken, begrijp dan dat de Live Data Viewer de verbinding verbreekt als het teveel overhead op het systeem veroorzaakt. Dit is een grote veiligheid, maar ik zou nog steeds attent zijn bij het gebruik van deze evenementsessies. Ik geloof dat ze een fantastische eerste stap zijn voor het oplossen van problemen, vooral voor degenen die nieuw zijn bij SQL Server of Extended Events. Als u de Live Data Viewer echter open heeft staan en wegloopt van uw computer, gaat de gebeurtenissessie door . Als u de Live Data Viewer stopt of sluit, wordt de gebeurtenissessie gestopt, wat ik aanraad als u klaar bent met het verzamelen van gegevens of het oplossen van problemen.
Voor gebeurtenissessies die u voor een langere periode wilt laten lopen, maakt u afzonderlijke gebeurtenissessies die naar het doel event_file schrijven en de juiste predikaten hebben. Als je meer informatie nodig hebt om aan de slag te gaan met Extended Events, bekijk dan de sessie die ik vorig jaar op SQLBits gaf over het migreren van Profiler naar Extended Events.