Ik doe dezelfde aanbevelingen over tempdb sinds ik meer dan 15 jaar geleden met SQL Server begon te werken, toen ik werkte met klanten met versie 2000. De essentie:maak meerdere gegevensbestanden met dezelfde grootte, met dezelfde automatische -groei-instellingen, schakel traceringsvlag 1118 (en misschien 1117) in en verminder uw tempdb-gebruik. Van de kant van de klant was dit de limiet van wat kan worden gedaan*, tot SQL Server 2019.
*Er zijn een paar aanvullende coderingsaanbevelingen die Pam Lahoud bespreekt in haar zeer informatieve bericht, TEMPDB – Files and Trace Flags and Updates, Oh My!
Wat ik interessant vind, is dat tempdb na al die tijd nog steeds een probleem is. Het SQL Server-team heeft in de loop der jaren veel wijzigingen aangebracht om problemen te verhelpen, maar het misbruik gaat door. De laatste aanpassing door het SQL Server-team is het verplaatsen van de systeemtabellen (metadata) voor tempdb naar In-Memory OLTP (ook wel voor geheugen geoptimaliseerd). Sommige informatie is beschikbaar in de release-opmerkingen van SQL Server 2019 en er was een demo van Bob Ward en Conor Cunningham tijdens de eerste dag van de PASS Summit-keynote. Pam Lahoud deed ook een korte demo tijdens haar algemene PASS Summit-sessie. Nu 2019 CTP 3.2 uit is, dacht ik dat het misschien tijd werd om zelf wat te testen.
Instellen
Ik heb SQL Server 2019 CTP 3.2 geïnstalleerd op mijn virtuele machine, die 8 GB geheugen heeft (max. servergeheugen ingesteld op 6 GB) en 4 vCPU's. Ik heb vier (4) tempdb-gegevensbestanden gemaakt, elk met een grootte van 1 GB.
Ik heb een kopie van WideWorldImporters hersteld en vervolgens drie opgeslagen procedures gemaakt (definities hieronder). Elke opgeslagen procedure accepteert een datuminvoer en duwt alle rijen van Sales.Order en Sales.OrderLines voor die datum naar het tijdelijke object. In Sales.usp_OrderInfoTV is het object een tabelvariabele, in Sales.usp_OrderInfoTT is het object een tijdelijke tabel gedefinieerd via SELECT … INTO met een niet-geclusterde achteraf toegevoegd, en in Sales.usp_OrderInfoTTALT is het object een vooraf gedefinieerde tijdelijke tabel die vervolgens wordt gewijzigd om een extra kolom te hebben. Nadat de gegevens aan het tijdelijke object zijn toegevoegd, is er een SELECT-instructie voor het object dat wordt toegevoegd aan de tabel Sales.Customers.
/*
Create the stored procedures
*/
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTV
GO
CREATE PROCEDURE Sales.usp_OrderInfoTV @OrderDate DATE
AS
BEGIN
DECLARE @OrdersInfo TABLE (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2),
OrderDate DATE);
INSERT INTO @OrdersInfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice,
OrderDate)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM @OrdersInfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName;
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTT @OrderDate DATE
AS
BEGIN
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
INTO #temporderinfo
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTTALT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTTALT @OrderDate DATE
AS
BEGIN
CREATE TABLE #temporderinfo (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2));
INSERT INTO #temporderinfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
/*
Create tables to hold testing data
*/
USE [WideWorldImporters];
GO
CREATE TABLE [dbo].[PerfTesting_Tests] (
[TestID] INT IDENTITY(1,1),
[TestName] VARCHAR (200),
[TestStartTime] DATETIME2,
[TestEndTime] DATETIME2
) ON [PRIMARY];
GO
CREATE TABLE [dbo].[PerfTesting_WaitStats] (
[TestID] [int] NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
GO
/*
Enable Query Store
(testing settings, not exactly what
I would recommend for production)
*/
USE [master];
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON;
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 600,
INTERVAL_LENGTH_MINUTES = 10,
MAX_STORAGE_SIZE_MB = 1024,
QUERY_CAPTURE_MODE = AUTO,
SIZE_BASED_CLEANUP_MODE = AUTO);
GO Testen
Het standaardgedrag voor SQL Server 2019 is dat de tempdb-metagegevens niet voor het geheugen zijn geoptimaliseerd, en we kunnen dit bevestigen door sys.configurations te controleren:
SELECT * FROM sys.configurations WHERE configuration_id = 1589;

Voor alle drie de opgeslagen procedures gebruiken we sqlcmd om 20 gelijktijdige threads te genereren die een van de twee verschillende .sql-bestanden uitvoeren. Het eerste .sql-bestand, dat door 19 threads zal worden gebruikt, zal de procedure 1000 keer in een lus uitvoeren. Het tweede .sql-bestand, dat slechts één (1) thread heeft, zal de procedure 3000 keer in een lus uitvoeren. Het bestand bevat ook TSQL om twee interessante statistieken vast te leggen:totale duur en wachtstatistieken. We zullen Query Store gebruiken om de gemiddelde duur van de procedure vast te leggen.
/*
Example of first .sql file
which calls the SP 1000 times
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @Date DATE;
DECLARE @Counter INT = 1;
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
WHILE @Counter <= 1000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1;
END
GO
/*
Example of second .sql file
which calls the SP 3000 times
and captures total duration and
wait statisics
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @DATE DATE;
DECLARE @Counter INT = 1;
DECLARE @TestID INT;
DECLARE @TestName VARCHAR(200) = 'Execution of usp_OrderInfoTT - Disk Based System Tables';
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_Tests] ([TestName]) VALUES (@TestName);
SELECT @TestID = MAX(TestID) FROM [WideWorldImporters].[dbo].[PerfTesting_Tests];
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
/*
set start time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestStartTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
WHILE @Counter <= 3000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1
END
/*
set end time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestEndTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
WITH [DiffWaits] AS
(SELECT
-- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT
-- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0),
[Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results.
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP',
N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT',
N'CLR_SEMAPHORE', N'CXCONSUMER', N'DBMIRROR_DBM_EVENT',
N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC',
N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT',
N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE',
N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PARALLEL_REDO_DRAIN_WORKER',
N'PARALLEL_REDO_LOG_CACHE', N'PARALLEL_REDO_TRAN_LIST', N'PARALLEL_REDO_WORKER_SYNC',
N'PARALLEL_REDO_WORKER_WAIT_WORK', N'PREEMPTIVE_XE_GETTARGETSTATE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH',
N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY',
N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP',
N'SNI_HTTP_ACCEPT', N'SOS_WORK_DISPATCHER', N'SP_SERVER_DIAGNOSTICS_SLEEP',
N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR',
N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_RECOVERY', N'WAIT_XTP_HOST_WAIT',
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE',
N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
)
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_WaitStats] (
[TestID],
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
@TestID,
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO Voorbeeld van een opdrachtregelbestand:
Resultaten
Na het uitvoeren van de opdrachtregelbestanden die 20 threads genereren voor elke opgeslagen procedure, laat het controleren van de totale duur van de 12.000 uitvoeringen van elke procedure het volgende zien:
SELECT *, DATEDIFF(SECOND, TestStartTime, TestEndTime) AS [TotalDuration] FROM [dbo].[PerfTesting_Tests] ORDER BY [TestID];

De opgeslagen procedures met de tijdelijke tabellen (usp_OrderInfoTT en usp_OrderInfoTTC) duurden langer om te voltooien. Als we kijken naar de prestaties van individuele zoekopdrachten:
SELECT
[qsq].[query_id],
[qsp].[plan_id],
OBJECT_NAME([qsq].[object_id]) AS [ObjectName],
[rs].[count_executions],
[rs].[last_execution_time],
[rs].[avg_duration],
[rs].[avg_logical_io_reads],
[qst].[query_sql_text]
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
WHERE ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTT'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTV'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTTALT'))
ORDER BY [qsq].[query_id], [rs].[last_execution_time];

We kunnen zien dat de SELECT … INTO voor usp_OrderInfoTT gemiddeld ongeveer 28 ms duurde (duur in Query Store wordt opgeslagen in microseconden), en slechts 9 ms duurde toen de tijdelijke tabel vooraf was gemaakt. Voor de tabelvariabele duurde de INSERT gemiddeld iets meer dan 22 ms. Interessant is dat de SELECT-query iets meer dan 1 ms duurde voor de tijdelijke tabellen en ongeveer 2,7 ms voor de tabelvariabele.
Een controle van wachtstatistieken vindt een bekend wait_type, PAGELATCH*:
SELECT * FROM [dbo].[PerfTesting_WaitStats] ORDER BY [TestID], [Percentage] DESC;

Merk op dat we alleen PAGELATCH* zien wachten op tests 1 en 2, wat de procedures waren met de tijdelijke tabellen. Voor usp_OrderInfoTV, die een tabelvariabele gebruikte, zien we alleen SOS_SCHEDULER_YIELD-wachttijden. Let op: Dit betekent op geen enkele manier dat u tabelvariabelen moet gebruiken in plaats van tijdelijke tabellen , en het betekent ook niet dat u niet laat PAGELATCH wacht met tabelvariabelen. Dit is een bedacht scenario; Ik zeer raad je aan te testen met JOUW code om te zien welke wait_types verschijnen.
Nu zullen we de instantie wijzigen om voor het geheugen geoptimaliseerde tabellen te gebruiken voor de tempdb-metadata. Er zijn twee manieren om dit te doen, via het ALTER SERVER CONFIGURATION commando, of door sp_configure te gebruiken. Aangezien deze instelling een geavanceerde optie is, moet u bij gebruik van sp_configure eerst de geavanceerde opties inschakelen.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON; GO
Na deze wijziging is het noodzakelijk om opnieuw op te starten naar de instantie. (OPMERKING:u kunt dit weer wijzigen in GEEN voor geheugen geoptimaliseerde tabellen gebruiken, u hoeft alleen de instantie opnieuw te starten.) Als we na de herstart sys.configurations opnieuw controleren, kunnen we zien dat de metadatatabellen voor het geheugen zijn geoptimaliseerd:

Na het opnieuw uitvoeren van de opdrachtregelbestanden, toont de totale duur van de 21.000 uitvoeringen van elke procedure het volgende (merk op dat de resultaten worden gerangschikt per opgeslagen procedure voor eenvoudigere vergelijking):

Er was zeker een prestatieverbetering voor zowel usp_OrderInfoTT als usp_OrderInfoTTC , en een lichte prestatieverbetering voor usp_OrderInfoTV. Laten we de duur van de zoekopdracht eens bekijken:
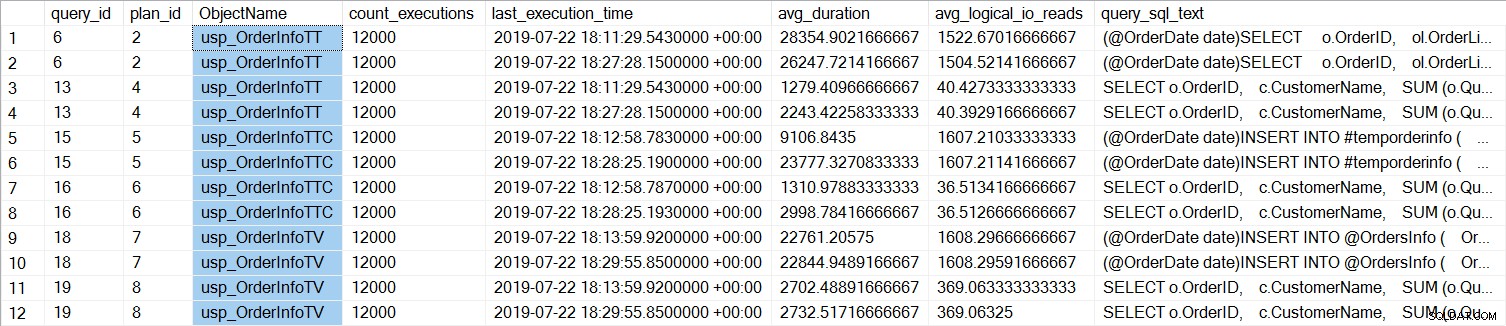
Voor alle query's is de duur van de query bijna hetzelfde, behalve de toename van de INSERT-duur wanneer de tabel vooraf is gemaakt, wat volkomen onverwacht is. We zien wel een interessante verandering in wachtstatistieken:
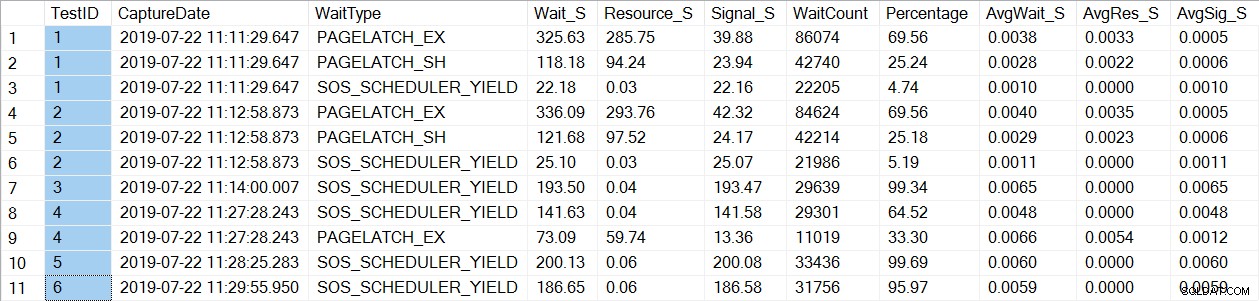
Voor usp_OrderInfoTT wordt een SELECT … INTO uitgevoerd om de tijdelijke tabel te maken. De wachttijden veranderen van PAGELATCH_EX en PAGELATCH_SH in alleen PAGELATCH_EX en SOS_SCHEDULER_YIELD. We zien de PAGELATCH_SH-wachttijden niet meer.
Voor usp_OrderInfoTTC, dat de tijdelijke tabel aanmaakt en vervolgens invoegt, verschijnen de PAGELATCH_EX- en PAGELATCH_SH-wachten niet langer en zien we alleen SOS_SCHEDULER_YIELD-wachten.
Ten slotte zijn de wachttijden voor OrderInfoTV consistent - alleen SOS_SCHEDULER_YIELD, met bijna dezelfde totale wachttijd.
Samenvatting
Op basis van deze testen zien we in alle gevallen wel een verbetering, significant voor de opgeslagen procedures met tijdelijke tabellen. Er is een kleine wijziging voor de tabelvariabele procedure. Het is uiterst belangrijk om te onthouden dat dit één scenario is, met een kleine belastingstest. Ik was erg geïnteresseerd om deze drie zeer eenvoudige scenario's uit te proberen, om te proberen te begrijpen wat het meest zou kunnen profiteren van het geheugengeoptimaliseerd maken van de tempdb-metadata. Deze werklast was klein en liep voor een zeer beperkte tijd - in feite had ik meer gevarieerde resultaten met meer threads, wat de moeite waard is om in een ander bericht te onderzoeken. Het grootste voordeel is dat, zoals bij alle nieuwe functies en functionaliteit, testen belangrijk is. Voor deze functie wilt u een basislijn van de huidige prestaties hebben waarmee u statistieken kunt vergelijken, zoals batchverzoeken/sec en wachtstatistieken nadat de metadata voor het geheugen is geoptimaliseerd.
Aanvullende overwegingen
Het gebruik van In-Memory OLTP vereist een bestandsgroep van het type MEMORY OPTIMIZED DATA. Na het inschakelen van MEMORY_OPTIMIZED TEMPDB_METADATA wordt er echter geen extra bestandsgroep gemaakt voor tempdb. Bovendien is het niet bekend of de voor geheugen geoptimaliseerde tabellen duurzaam zijn (SCHEMA_AND_DATA) of niet (SCHEMA_ONLY). Meestal kan dit worden bepaald via sys.tables (durability_desc), maar er wordt niets teruggestuurd voor de betrokken systeemtabellen wanneer dit in tempdb wordt opgevraagd, zelfs niet bij gebruik van de Dedicated Administrator Connection. U hebt wel de mogelijkheid om niet-geclusterde indexen te bekijken voor de voor geheugen geoptimaliseerde tabellen. U kunt de volgende query gebruiken om te zien welke tabellen voor geheugen zijn geoptimaliseerd in tempdb:
SELECT * FROM tempdb.sys.dm_db_xtp_object_stats x JOIN tempdb.sys.objects o ON x.object_id = o.object_id JOIN tempdb.sys.schemas s ON o.schema_id = s.schema_id;
Voer vervolgens voor een van de tabellen sp_helpindex uit, bijvoorbeeld:
EXEC sys.sp_helpindex N'sys.sysobjvalues';

Merk op dat als het een hash-index is (waarvoor het schatten van de BUCKET_COUNT vereist is als onderdeel van het maken), de beschrijving "niet-geclusterde hash" zou bevatten.