
In dit artikel zullen we onderzoeken wanneer en hoe de SQL PARTITION BY-clausule moet worden gebruikt en deze vergelijken met het gebruik van de GROUP BY-clausule.
De vensterfunctie begrijpen
Databasegebruikers gebruiken geaggregeerde functies zoals MAX(), MIN(), AVERAGE() en COUNT() voor het uitvoeren van gegevensanalyse. Deze functies werken op een hele tabel en retourneren enkelvoudige geaggregeerde gegevens met behulp van de GROUP BY-component. Soms hebben we geaggregeerde waarden nodig voor een kleine set rijen. In dit geval helpt de Window-functie in combinatie met de aggregatiefunctie om de gewenste output te bereiken. De functie Window gebruikt de clausule OVER() en kan de volgende functies bevatten:
- Partitionering door: Dit verdeelt de rijen of queryresultaten in kleine partities.
- Bestel op: Dit rangschikt de rijen in oplopende of aflopende volgorde voor het partitievenster. De standaardvolgorde is oplopend.
- Rij of bereik: U kunt de rijen in een partitie verder beperken door de start- en eindpunten op te geven.
In dit artikel zullen we ons concentreren op het verkennen van de SQL PARTITION BY-clausule.
Voorbereiding van voorbeeldgegevens
Stel dat we een tabel [SalesLT].[Orders] hebben waarin de details van de klantorder zijn opgeslagen. Het heeft een kolom [Stad] die de stad van de klant specificeert waar de bestelling is geplaatst.
CREATE TABLE [SalesLT].[Orders] ( orderid INT, orderdate DATE, customerName VARCHAR(100), City VARCHAR(50), amount MONEY ) INSERT INTO [SalesLT].[Orders] SELECT 1,'01/01/2021','Mohan Gupta','Alwar',10000 UNION ALL SELECT 2,'02/04/2021','Lucky Ali','Kota',20000 UNION ALL SELECT 3,'03/02/2021','Raj Kumar','Jaipur',5000 UNION ALL SELECT 4,'04/02/2021','Jyoti Kumari','Jaipur',15000 UNION ALL SELECT 5,'05/03/2021','Rahul Gupta','Jaipur',7000 UNION ALL SELECT 6,'06/04/2021','Mohan Kumar','Alwar',25000 UNION ALL SELECT 7,'07/02/2021','Kashish Agarwal','Alwar',15000 UNION ALL SELECT 8,'08/03/2021','Nagar Singh','Kota',2000 UNION ALL SELECT 9,'09/04/2021','Anil KG','Alwar',1000 Go
Laten we zeggen dat we de totale orderwaarde per locatie (Stad) willen weten. Voor dit doel gebruiken we de functies SUM() en GROUP BY, zoals hieronder weergegeven.
SELECT City AS CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] GROUP BY city ORDER BY city
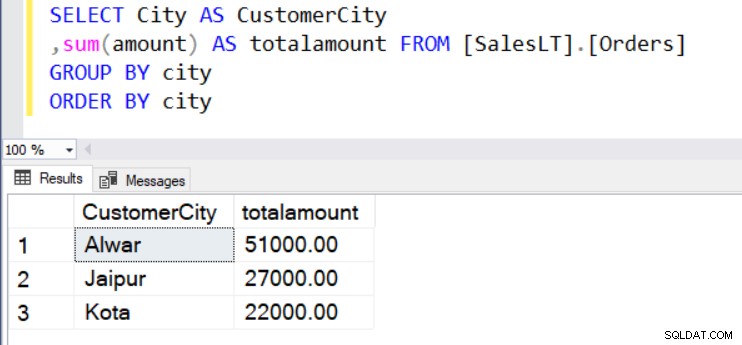
In de resultatenset kunnen we de niet-geaggregeerde kolommen in de SELECT-instructie niet gebruiken. We kunnen bijvoorbeeld [Klantnaam] niet weergeven in de uitvoer omdat deze niet is opgenomen in de GROUP BY-clausule.
SQL Server geeft de volgende foutmelding als u de niet-geaggregeerde kolom in de kolomlijst probeert te gebruiken.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount FROM [SalesLT].[Orders]
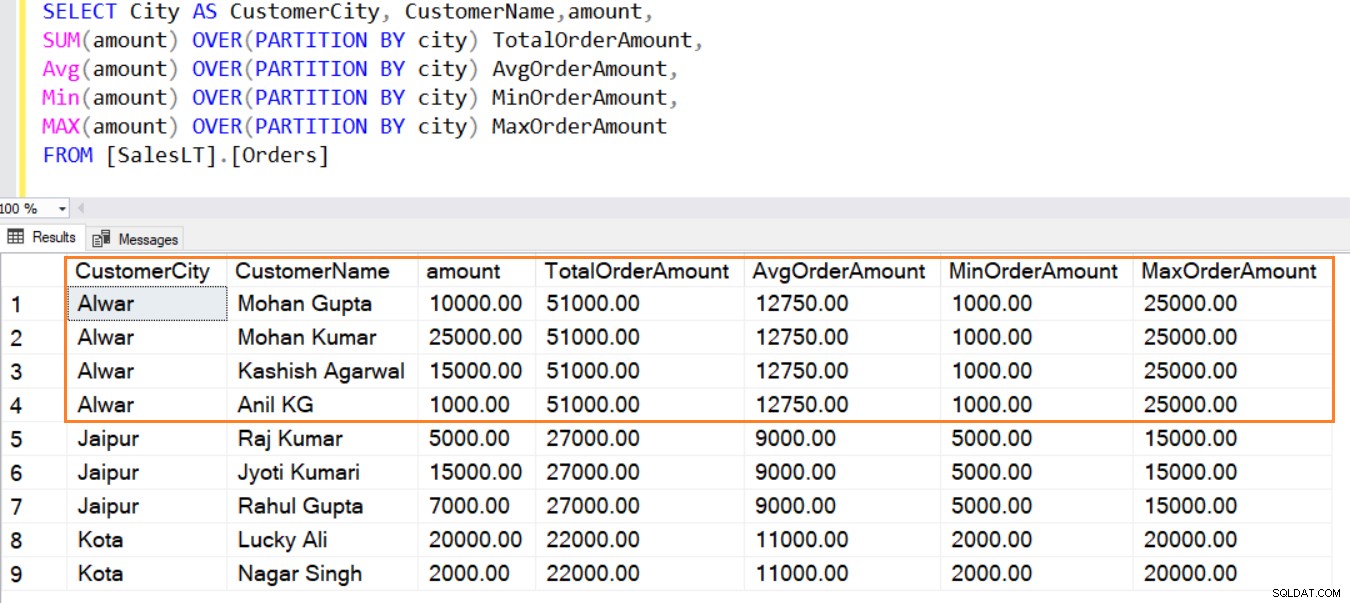
Zoals hieronder wordt getoond, maakt de clausule PARTITION BY een kleiner venster (set gegevensrijen), voert de aggregatie uit en geeft deze weer. U kunt in deze uitvoer ook niet-geaggregeerde kolommen bekijken.
Op dezelfde manier kunt u de functies AVG(), MIN(), MAX() gebruiken om het gemiddelde, minimale en maximale bedrag uit de rijen in een venster te berekenen.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount, Avg(amount) OVER(PARTITION BY city) AvgOrderAmount, Min(amount) OVER(PARTITION BY city) MinOrderAmount, MAX(amount) OVER(PARTITION BY city) MaxOrderAmount FROM [SalesLT].[Orders]
De SQL PARTITION BY-clausule gebruiken met de ROW_NUMBER()-functie
Voorheen kregen we de geaggregeerde waarden in een venster met behulp van de PARTITION BY-component. Stel dat we in plaats van het totaal het cumulatieve totaal in een partitie nodig hebben.
Een cumulatief totaal werkt op de volgende manieren.
| Rij | Cumulatief totaal |
| 1 | Rang 1+ 2 |
| 2 | Rang 2+3 |
| 3 | Rang 3+4 |
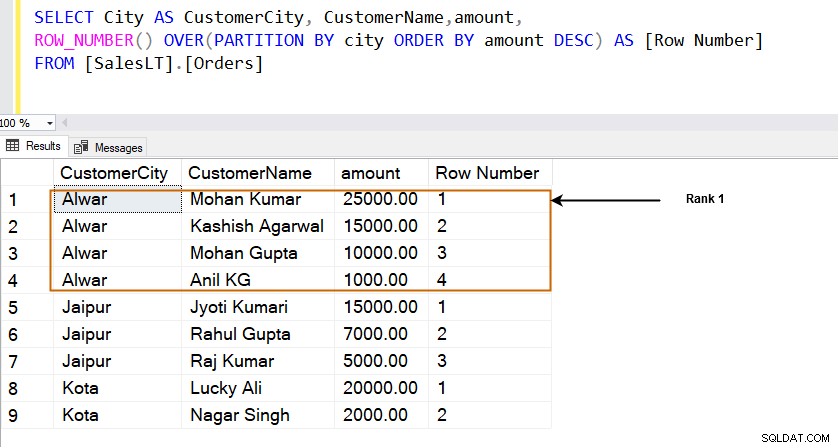
De rijrangschikking wordt berekend met de functie ROW_NUMBER(). Laten we eerst deze functie gebruiken en de rijrangschikkingen bekijken.
- De functie ROW_NUMBER() gebruikt de clausules OVER en PARTITION BY en sorteert resultaten in oplopende of aflopende volgorde. Het begint rijen te rangschikken vanaf 1 per sorteervolgorde.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number] FROM [SalesLT].[Orders]
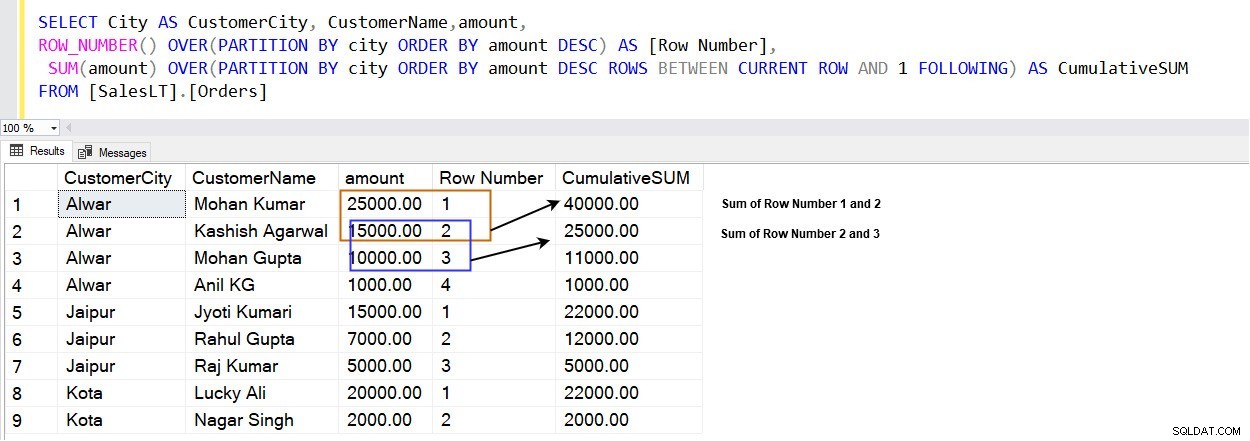
In de stad [Alwar] bevindt de rij met het hoogste bedrag (25000,00) zich bijvoorbeeld in rij 1. Zoals hieronder wordt weergegeven, rangschikt deze rijen in het venster dat is gespecificeerd door de clausule PARTITION BY. We hebben bijvoorbeeld drie verschillende steden [Alwar], [Jaipur] en [Kota], en elk venster (stad) krijgt zijn rijrangschikking.
Om het cumulatieve totaal te berekenen, gebruiken we de volgende argumenten.
- HUIDIGE RIJ:Het specificeert het begin- en eindpunt in het gespecificeerde bereik.
- 1 volgend:het specificeert het aantal rijen (1) dat moet volgen vanaf de huidige rij.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS CumulativeSUM FROM [SalesLT].[Orders]
De volgende afbeelding laat zien dat u een cumulatief totaal krijgt in plaats van een algemeen totaal in een venster dat wordt gespecificeerd door de clausule PARTITION BY.
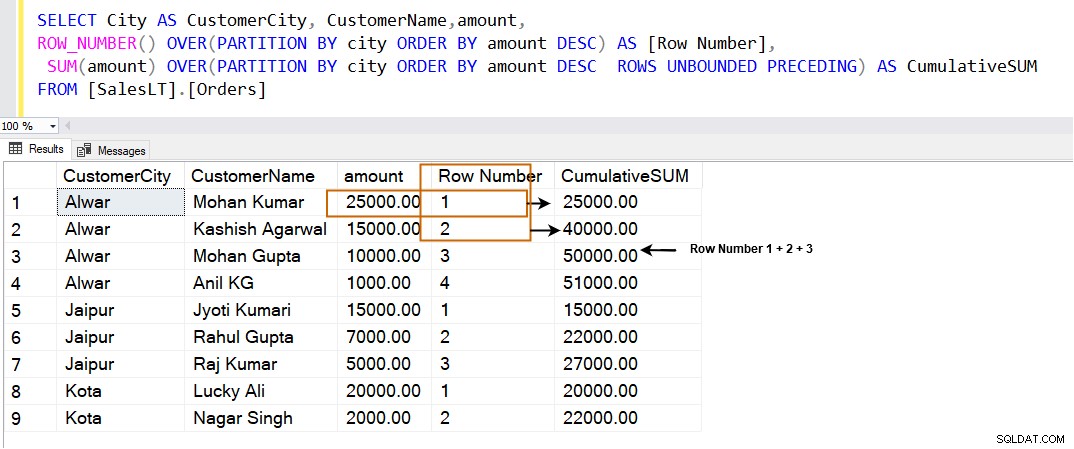
Als we ROWS UNBOUNDED PRECEDING . gebruiken in de SQL PARTITION BY-component berekent het het cumulatieve totaal op de volgende manier. Het gebruikt de huidige rijen samen met de rijen met de hoogste waarden in het opgegeven venster.
| Rij | Cumulatief totaal |
| 1 | Rang 1 |
| 2 | Rang 1+2 |
| 3 | Rang 1+2+3 |
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS UNBOUNDED PRECEDING) AS CumulativeSUM FROM [SalesLT].[Orders]
De clausule GROUP BY en SQL PARTITION BY vergelijken
| GROEP OP | PARTITIE DOOR |
| Het retourneert één rij per groep na berekening van de totale waarden. | Het retourneert alle rijen van de SELECT-instructie samen met extra kolommen met geaggregeerde waarden. |
| We kunnen de niet-geaggregeerde kolom in de SELECT-instructie niet gebruiken. | We kunnen vereiste kolommen gebruiken in de SELECT-instructie, en het produceert geen fouten voor de niet-geaggregeerde kolom. |
| Het vereist het gebruik van de HAVING-component om records uit de SELECT-instructie te filteren. | De functie PARTITION kan extra predikaten hebben in de WHERE-component, afgezien van de kolommen die in de SELECT-instructie worden gebruikt. |
| De GROUP BY wordt gebruikt in reguliere aggregaten. | PARTITION BY wordt gebruikt in vensteraggregaten. |
| We kunnen het niet gebruiken voor het berekenen van rijnummers of hun rangen. | Het kan rijnummers en hun rangen berekenen in het kleinere venster. |
Het in gebruik nemen
Het wordt aanbevolen om de SQL PARTITION BY-component te gebruiken wanneer u met meerdere gegevensgroepen werkt voor de geaggregeerde waarden in de afzonderlijke groep. Op dezelfde manier kan het worden gebruikt om originele rijen te bekijken met de extra kolom met geaggregeerde waarden.