
De beschikbaarheid, toegankelijkheid en prestaties van gegevens zijn essentieel voor zakelijk succes. Het afstemmen van prestaties en het optimaliseren van SQL-query's zijn lastig, maar noodzakelijk voor databaseprofessionals. Ze moeten verschillende gegevensverzamelingen bekijken met behulp van uitgebreide gebeurtenissen, prestaties, uitvoeringsplannen, statistieken en indexen om er maar een paar te noemen. Soms vragen applicatie-eigenaren om meer systeembronnen (CPU en geheugen) om de systeemprestaties te verbeteren. Het is echter mogelijk dat u deze aanvullende bronnen niet nodig hebt en dat er kosten aan verbonden kunnen zijn. Soms zijn er alleen kleine verbeteringen nodig om het zoekgedrag te veranderen.
In dit artikel bespreken we enkele best practices voor het optimaliseren van SQL-query's die u kunt toepassen bij het schrijven van SQL-query's.
SELECT * vs SELECT kolomlijst
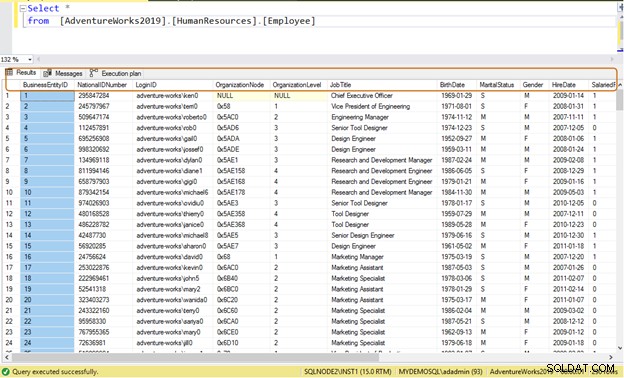
Gewoonlijk gebruiken ontwikkelaars de SELECT *-instructie om gegevens uit een tabel te lezen. Het leest alle beschikbare gegevens van de kolom in de tabel. Stel dat een tabel [AdventureWorks2019].[HumanResources].[Employee] gegevens van 290 werknemers opslaat en u moet de volgende informatie ophalen:
- Nationaal ID-nummer werknemer
- Geboorte
- Geslacht
- Inhuurdatum
Inefficiënte zoekopdracht: Als u het SELECT *-statement gebruikt, worden alle kolomgegevens voor alle 290 werknemers geretourneerd.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
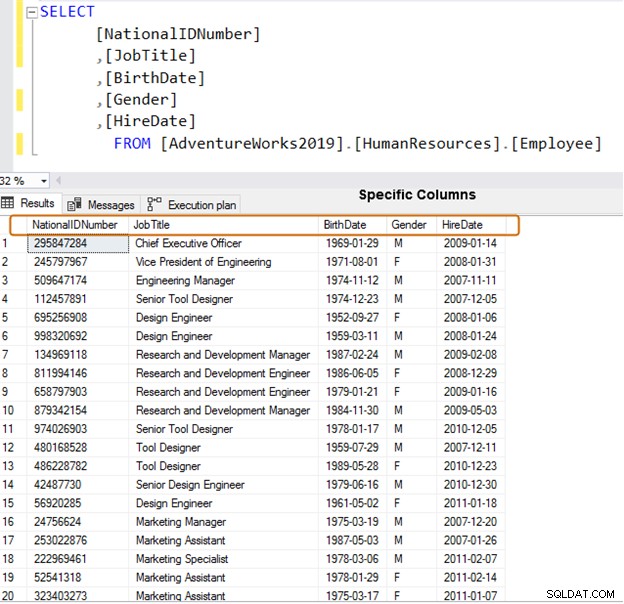
Gebruik in plaats daarvan specifieke kolomnamen voor het ophalen van gegevens.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
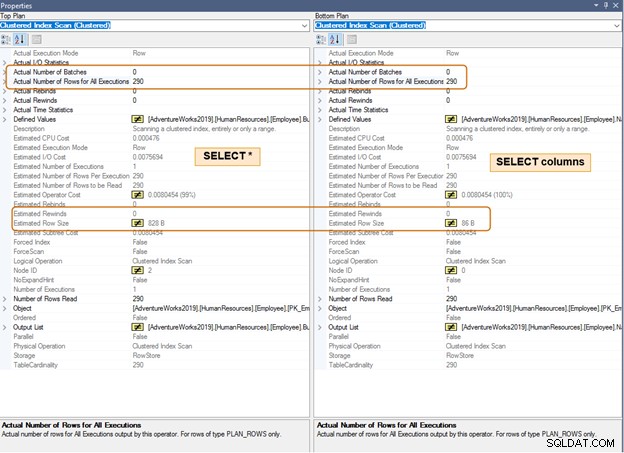
Noteer in het onderstaande uitvoeringsplan het verschil in de geschatte rijgrootte voor hetzelfde aantal rijen. Je zult ook een verschil merken in CPU en IO voor een groot aantal rijen.
Gebruik van COUNT() versus EXISTS
Stel dat u wilt controleren of een specifiek record in de SQL-tabel bestaat. Gewoonlijk gebruiken we AANTAL (*) om het record te controleren, en het geeft het aantal records in de uitvoer terug.
We kunnen hiervoor echter de functie IF EXISTS() gebruiken. Voor de vergelijking heb ik de statistieken ingeschakeld voordat ik de zoekopdrachten uitvoerde.
De zoekopdracht voor COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
De zoekopdracht voor IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Ik heb statisticsparser gebruikt om de statistische resultaten van beide zoekopdrachten te analyseren. Bekijk de resultaten hieronder. De query met COUNT(*) heeft 276 logische reads, terwijl de IF EXISTS() 83 logische reads heeft. U kunt zelfs een significantere vermindering van logische leesbewerkingen krijgen met de IF EXISTS(). Daarom moet u het gebruiken om SQL-query's te optimaliseren voor betere prestaties.

Vermijd het gebruik van SQL DISTINCT
Wanneer we unieke records van de query willen, gebruiken we gewoonlijk de SQL DISTINCT-clausule. Stel dat u twee tabellen samenvoegt en in de uitvoer de dubbele rijen retourneert. Een snelle oplossing is om de DISTINCT-operator op te geven die de gedupliceerde rij onderdrukt.
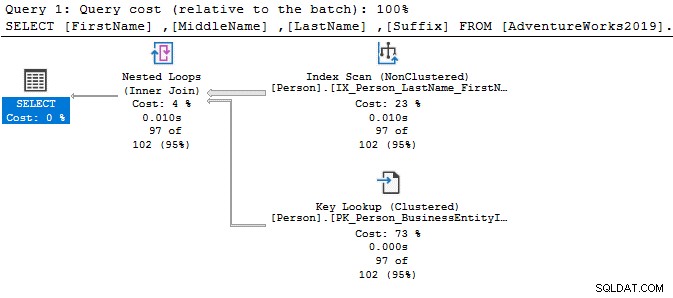
Laten we eens kijken naar de eenvoudige SELECT-instructies en de uitvoeringsplannen vergelijken. Het enige verschil tussen beide zoekopdrachten is een DISTINCT-operator.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Met de DISTINCT-operator zijn de querykosten 77%, terwijl de eerdere query (zonder DISTINCT) slechts 23% batchkosten heeft.
U kunt GROUP BY, CTE of een subquery gebruiken om efficiënte SQL-code te schrijven in plaats van DISTINCT te gebruiken om verschillende waarden uit de resultatenset te halen. Bovendien kunt u extra kolommen ophalen voor een afzonderlijke resultatenset.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Gebruik van wildcards in de SQL-query
Stel dat u wilt zoeken naar de specifieke records met namen die beginnen met de opgegeven tekenreeks. Ontwikkelaars gebruiken een wildcard om naar de overeenkomende records te zoeken.
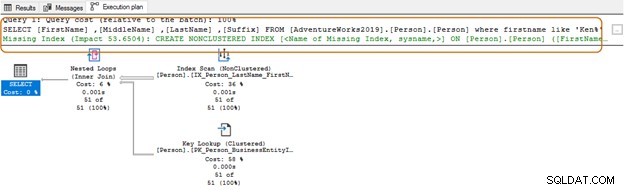
In de onderstaande zoekopdracht zoekt het naar de tekenreeks Ken in de voornaamkolom. Deze zoekopdracht haalt de verwachte resultaten op van Ken dra en Ken net. Maar het levert ook onverwachte resultaten op, bijvoorbeeld Macken zie en Nken ge.
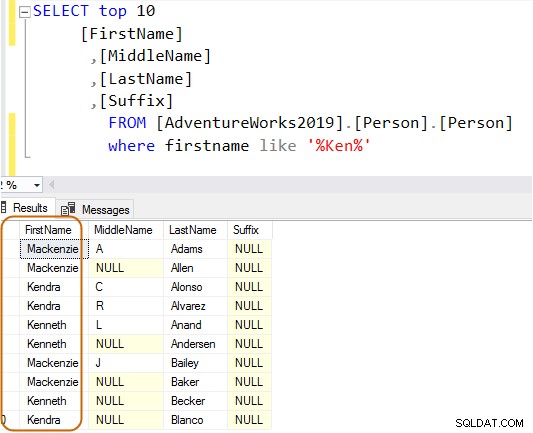
In het uitvoeringsplan ziet u de indexscan en de sleutelzoekopdracht voor de bovenstaande zoekopdracht.
U kunt het onverwachte resultaat vermijden door het jokerteken aan het einde van de tekenreeks te gebruiken.
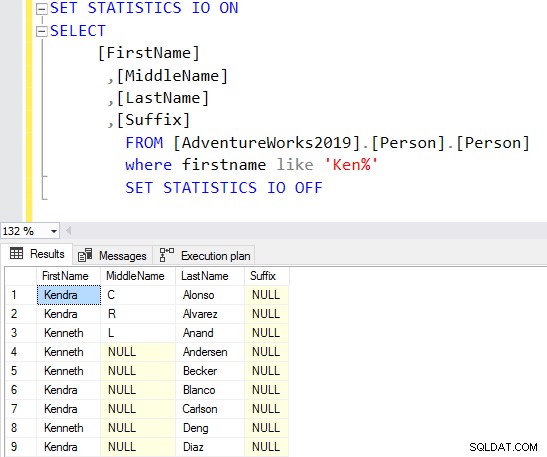
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Nu krijgt u het gefilterde resultaat op basis van uw vereisten.
Door het jokerteken aan het begin te gebruiken, kan de query-optimizer mogelijk de geschikte index niet gebruiken. Zoals te zien is in de onderstaande schermafbeelding, suggereert de queryoptimalisatie met een trailing wild-teken ook een ontbrekende index.
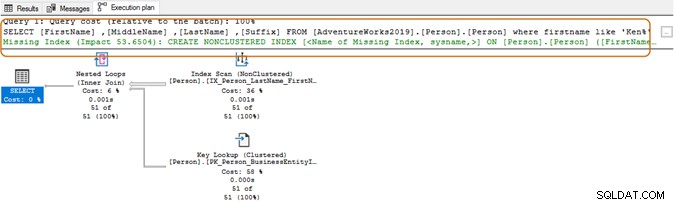
Hier wilt u uw toepassingsvereisten evalueren. Probeer het gebruik van een jokerteken in de zoekreeksen te vermijden, omdat het query-optimalisatieprogramma zou kunnen dwingen een tabelscan te gebruiken. Als de tabel enorm is, vereist dit meer systeembronnen voor IO, CPU en geheugen, en kan dit prestatieproblemen veroorzaken voor uw SQL-query.
Gebruik van de WHERE- en HAVING-clausules
De WHERE- en HAVING-clausules worden gebruikt als gegevensrijfilters. De WHERE-component filtert de gegevens voordat de groeperingslogica wordt toegepast, terwijl de HAVING-component rijen filtert na de aggregatieberekeningen.
In de onderstaande query gebruiken we bijvoorbeeld een gegevensfilter in de HAVING-component zonder een WHERE-component.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
De volgende query filtert de gegevens eerst in de WHERE-component en gebruikt vervolgens de HAVING-component voor het filter voor verzamelde gegevens.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Ik raad het gebruik van de WHERE-clausule voor gegevensfiltering en de HAVING-clausule voor uw verzamelde gegevensfilter als best practice aan.
Gebruik van de IN- en EXISTS-clausules
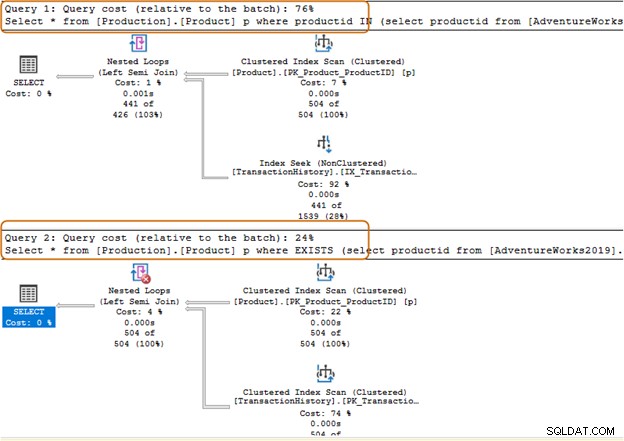
Vermijd het gebruik van de IN-operatorclausule voor uw SQL-query's. In de onderstaande zoekopdracht hebben we bijvoorbeeld eerst de product-ID uit de tabel [Productie].[TransactionHistory]) gevonden en vervolgens naar de bijbehorende records in de tabel [Productie].[Product] gezocht.
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
In de onderstaande query hebben we de IN-clausule vervangen door een EXISTS-clausule.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Laten we nu de statistieken vergelijken na het uitvoeren van beide zoekopdrachten.
De IN-clausule gebruikt 504 scans, terwijl de EXISTS-clausule 1 scan gebruikt voor de [Production].[TransactionHistory])-tabel].
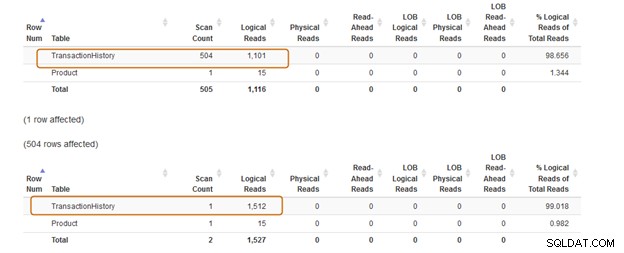
De IN-clausule querybatch kost 74%, terwijl de EXISTS-clausule 24% kost. Daarom moet u de IN-component vermijden, vooral als de subquery een grote dataset retourneert.
Ontbrekende indexen
Soms, wanneer we een SQL-query uitvoeren en zoeken naar het daadwerkelijke uitvoeringsplan in SSMS, krijgt u een suggestie over een index die uw SQL-query zou kunnen verbeteren.
Als alternatief kunt u de dynamische beheerweergaven gebruiken om de details van ontbrekende indexen in uw omgeving te controleren.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Meestal volgen DBA's het advies van SSMS en maken ze de indexen. Het kan op dit moment de queryprestaties verbeteren. U moet de index echter niet rechtstreeks op basis van die aanbevelingen maken. Het kan andere queryprestaties beïnvloeden en uw INSERT- en UPDATE-instructies vertragen.
- Bekijk eerst de bestaande indexen voor uw SQL-tabel.
- Opmerking, overindexering en onderindexering zijn beide slecht voor de prestaties van zoekopdrachten.
- Pas de ontbrekende indexaanbevelingen met de grootste impact toe na het bekijken van uw bestaande indexen en implementeer deze in uw lagere omgeving. Als uw werklast goed werkt na het implementeren van de nieuwe ontbrekende index, is het de moeite waard it toe te voegen.
Ik raad u aan dit artikel te raadplegen voor gedetailleerde best practices voor indexering:11 SQL Server Index Best Practices for Improved Performance Tuning.
Query-hints
Ontwikkelaars specificeren de queryhints expliciet in hun t-SQL-instructies. Deze queryhints overschrijven het gedrag van de queryoptimalisatie en dwingen deze om een uitvoeringsplan op te stellen op basis van uw queryhint. Veelgebruikte zoektips zijn NOLOCK, Optimize For en Recompile Merge/Hash/Loop. Het zijn kortetermijnoplossingen voor uw vragen. U moet echter werken aan het analyseren van uw zoekopdracht, indexen, statistieken en uitvoeringsplan voor een permanente oplossing.
Volgens best practices moet u het gebruik van elke queryhint tot een minimum beperken. U wilt de queryhints in de SQL-query gebruiken nadat u eerst de implicaties ervan hebt begrepen, en niet onnodig gebruiken.
Herinneringen voor SQL-queryoptimalisatie
Zoals we hebben besproken, is SQL-queryoptimalisatie een open weg. U kunt best practices en kleine fixes toepassen die de prestaties aanzienlijk kunnen verbeteren. Overweeg de volgende tips voor een betere ontwikkeling van zoekopdrachten:
- Kijk altijd naar de toewijzingen van systeembronnen (schijven, CPU, geheugen)
- Bekijk uw opstarttraceervlaggen, indexen en databaseonderhoudstaken
- Analyseer uw werklast met behulp van uitgebreide evenementen, profiler of databasebewakingstools van derden
- Implementeer altijd een oplossing (zelfs als u 100% zeker bent) eerst in de testomgeving en analyseer de impact ervan; zodra u tevreden bent, plant u de productie-implementaties