Ik neem aan dat de reden is dat ze dit gewoon niet als een prioriteitsfunctie hebben beschouwd die het waard is om te implementeren. Het lijkt erop dat Postgres doet steun beide
UNION en UNION ALL .
Als je sterke argumenten hebt voor deze functie, kun je feedback geven op Connect (of wat de URL van de vervanging ook zal zijn).
Het kan handig zijn om te voorkomen dat duplicaten worden toegevoegd, omdat een dubbele rij die in een latere stap aan een vorige wordt toegevoegd, bijna altijd een oneindige lus zal veroorzaken of de maximale recursielimiet zal overschrijden.
Er zijn nogal wat plaatsen in de SQL-standaarden
waar code wordt gebruikt om UNION . aan te tonen zoals hieronder
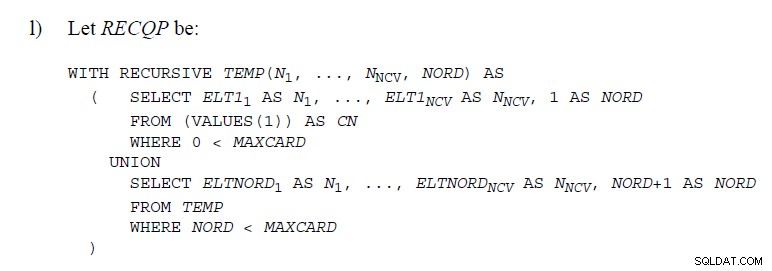
In dit artikel wordt uitgelegd hoe ze worden geïmplementeerd in SQL Server . Ze doen zoiets niet "onder de motorkap". De stapelspoel verwijdert rijen terwijl het werkt, dus het zou niet mogelijk zijn om te weten of een latere rij een duplicaat is van een verwijderde. Ondersteuning van UNION zou een iets andere aanpak nodig hebben.
In de tussentijd kun je vrij eenvoudig hetzelfde bereiken in een TVF met meerdere verklaringen.
Om een dwaas voorbeeld hieronder te nemen (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
De UNION wijzigen naar UNION ALL en het toevoegen van een DISTINCT aan het einde zal je niet redden van de oneindige recursie.
Maar u kunt dit implementeren als
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Het bovenstaande gebruikt IGNORE_DUP_KEY om duplicaten te verwijderen. Als de kolomlijst te breed is om te worden geïndexeerd, hebt u DISTINCT . nodig en NOT EXISTS in plaats van. Je zou waarschijnlijk ook een parameter willen om het maximale aantal recursies in te stellen en oneindige lussen te vermijden.