Demonstratie van mogelijke verklaring.
Maak tabelscript
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
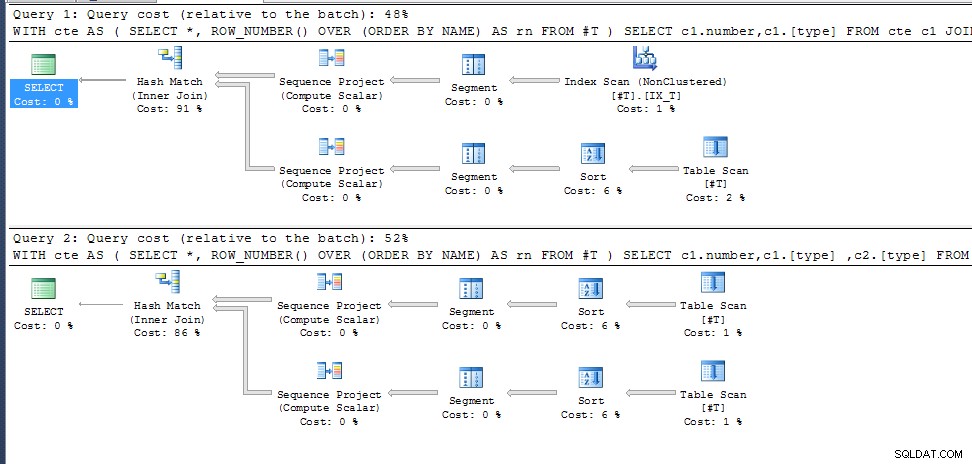
Query één (retourneert 35 resultaten)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Query twee (zelfde als voorheen, maar door c2.[type] toe te voegen aan de selectielijst levert het 0 resultaten op);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Waarom?
row_number() voor dubbele NAMEN is niet gespecificeerd, dus het kiest gewoon welke past in het beste uitvoeringsplan voor de vereiste uitvoerkolommen. In de tweede query is dit hetzelfde voor beide cte-aanroepen, in de eerste wordt een ander toegangspad gekozen met als resultaat een andere rijnummering.
Voorgestelde oplossing
U neemt zelf deel aan de CTE op ROW_NUMBER() over (order by t.[Date])
In tegenstelling tot wat mogelijk was verwacht, zal de CTE waarschijnlijk niet worden gerealiseerd
wat zou hebben gezorgd voor consistentie voor de self-join en dus ga je uit van een correlatie tussen ROW_NUMBER() aan beide kanten die misschien niet bestaan voor records waar een duplicaat [Date] bestaat in de gegevens.
Wat als u ROW_NUMBER() over (order by t.[Date], t.[id]) om ervoor te zorgen dat in het geval van gebonden data de rijnummering in een gegarandeerd consistente volgorde is. (Of een andere kolom/combinatie van kolommen die records kunnen onderscheiden als id het niet doet)