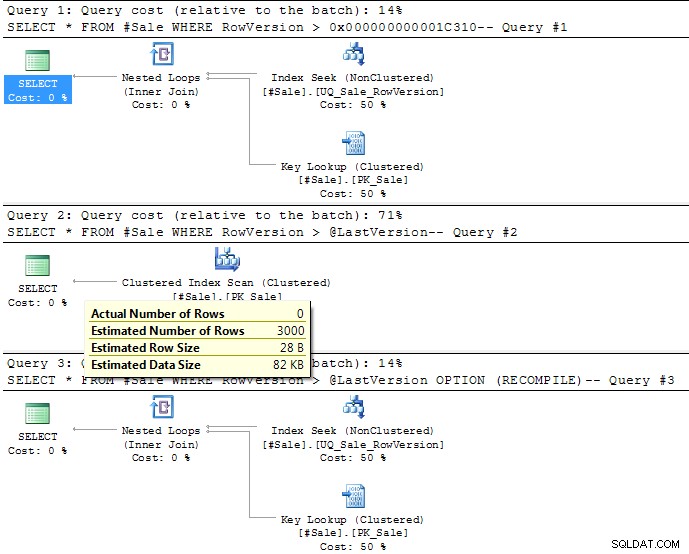
Query 2 gebruikt een variabele.
Op het moment dat de batch wordt gecompileerd, kent SQL Server de waarde van de variabele niet, dus valt hij terug op heuristieken die erg lijken op OPTIMIZE FOR (UNKNOWN)
Voor > het gaat ervan uit dat 30% van de rijen uiteindelijk overeenkomen (of 3000 rijen in uw voorbeeldgegevens). Dit is te zien in de afbeelding van het uitvoeringsplan zoals hieronder. Dit is aanzienlijk meer dan de 12 rijen (0,12%), namelijk het omslagpunt
voor deze zoekopdracht of het een geclusterde indexscan of een niet-geclusterde indexzoekopdracht en sleutelzoekopdrachten gebruikt.
Je zou OPTION (RECOMPILE) . moeten gebruiken om ervoor te zorgen dat het rekening houdt met de werkelijke variabelewaarde zoals weergegeven in het derde plan hieronder.
Script
CREATE TABLE #Sale
(
SaleId INT IDENTITY(1, 1)
CONSTRAINT PK_Sale PRIMARY KEY,
Test1 VARCHAR(10) NULL,
RowVersion rowversion NOT NULL
CONSTRAINT UQ_Sale_RowVersion UNIQUE
)
/*A better way of populating the table!*/
INSERT INTO #Sale (Test1)
SELECT TOP 10000 NULL
FROM master..spt_values v1, master..spt_values v2
GO
SELECT *
FROM #Sale
WHERE RowVersion > 0x000000000001C310-- Query #1
DECLARE @LastVersion rowversion = 0x000000000001C310
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion-- Query #2
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion
OPTION (RECOMPILE)-- Query #3
DROP TABLE #Sale