Subtree-kosten moeten met een grote korrel zout worden genomen (en vooral als je enorme kardinaliteitsfouten hebt). SET STATISTICS IO ON; SET STATISTICS TIME ON; output is een betere indicator van de werkelijke prestaties.
De nulrij-sortering neemt niet 87% van de bronnen in beslag. Dit probleem in uw plan is een schatting van de statistieken. De kosten die in het daadwerkelijke plan worden weergegeven, zijn nog geschatte kosten. Het past ze niet aan om rekening te houden met wat er werkelijk is gebeurd.
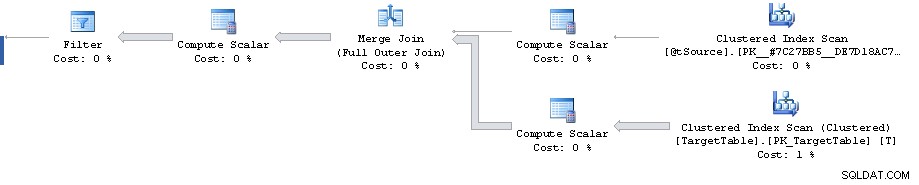
Er is een punt in het plan waar een filter 1.911.721 rijen reduceert tot 0, maar de geschatte rijen die verder gaan zijn 1.860.310. Daarna zijn alle kosten nep, met als hoogtepunt de 87% geschatte kosten van 3.348.560 rijen sorteren.
De kardinaliteitsschattingsfout kan worden gereproduceerd buiten de Merge verklaring door te kijken naar het geschatte plan voor de Full Outer Join met equivalente predikaten (geeft dezelfde schatting van 1.860.310 rijen).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Dat gezegd hebbende, het plan tot aan het filter zelf ziet er echter behoorlijk sub-optimaal uit. Het doet een volledige geclusterde indexscan wanneer u misschien een plan met 2 geclusterde indexbereiken zoekt. Eén om de enkele rij op te halen die overeenkomt met de primaire sleutel van de join-on-bron en de andere om de T.Key1 = @id op te halen bereik (hoewel dit misschien is om te voorkomen dat u later in geclusterde sleutelvolgorde moet sorteren?)
Misschien kun je deze herschrijving proberen en kijken of het beter of slechter werkt
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;