Reden voor het probleem :
TOKEN methode in SSIS gebruikt de implementatie van strtok functie in C++ . Ik heb deze informatie verzameld tijdens het lezen van het boek Microsoft® SQL Server® 2012 Integration Services
. Het wordt vermeld als opmerking op pagina 113 (Ik vind dit boek leuk! Veel leuke informatie. ).
Ik heb gezocht naar de implementatie van strtok functie en ik vond de volgende links.
INFO:strtok():C-functie -- Documentatiesupplement - Het codevoorbeeld in deze link laat zien dat de functie opeenvolgende scheidingstekens negeert.
De antwoorden op de volgende SO-vragen wijzen erop dat strtok functie is ontworpen om opeenvolgende scheidingstekens te negeren.
Weten wanneer er geen gegevens verschijnen tussen twee token-scheidingstekens met strtok()
strtok_s-gedrag met opeenvolgende scheidingstekens
Ik denk dat de TOKEN en TOKENCOUNT functies werken volgens ontwerp, maar of SSIS zich zo zou moeten gedragen, is misschien een vraag voor het Microsoft SSIS-team.
Originele post - Bovenstaande sectie is een update:
Ik heb een eenvoudig pakket gemaakt in SSIS 2012 op basis van uw gegevensinvoer. Zoals je in je vraag had beschreven, is de TOKEN functie gedraagt zich niet zoals bedoeld. Ik ben het met je eens dat de functie niet lijkt te werken. Dit bericht is niet een antwoord op uw oorspronkelijke probleem.
Hier is een alternatieve manier om de uitdrukking op een relatief eenvoudigere manier te schrijven. Dit werkt alleen als het laatste segment in uw invoerrecord altijd een waarde heeft (zeg A1 , B2 , C3 enz.).
Expressie kan worden herschreven als :
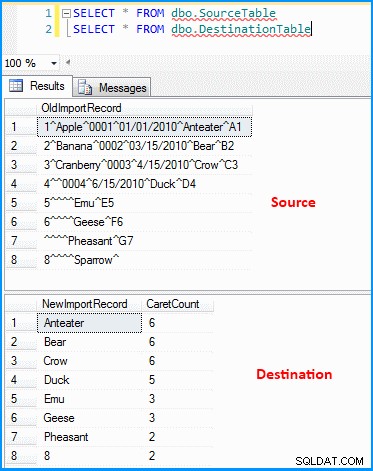
Deze instructie neemt het invoerrecord als parameter, het scheidingsteken (^) als de tweede parameter. De derde parameter berekent het totale aantal segmenten in de records wanneer ze worden gesplitst door het scheidingsteken. Als u gegevens in het laatste segment heeft, heeft u gegarandeerd twee segmenten. Je kunt dan 1 aftrekken om het voorlaatste segment op te halen.
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
Ik heb een eenvoudig pakket gemaakt met een gegevensstroomtaak. OLE DB-bron haalt de gegevens op en de afgeleide transformatie parseert en splitst de gegevens volgens de onderstaande schermafbeelding. De uitvoer wordt vervolgens ingevoegd in de bestemmingstabel. U kunt de bron- en bestemmingstabellen zien in de laatste schermafbeelding. Bestemmingstabel heeft twee kolommen. De eerste kolom slaat de voorlaatste segmentgegevens op en de segmenten tellen op basis van het scheidingsteken (wat weer niet correct is). U kunt merken dat het laatste record niet de juiste resultaten opleverde. Als het laatste record niet de waarde 8 had , dan zal de bovenstaande uitdrukking mislukken omdat de uitdrukking de index nul zal opleveren.
Ik hoop dat dat helpt om je uitdrukking te vereenvoudigen.
Als je niets meer van iemand anders hoort, raad ik je aan dit probleem te registreren op de Microsoft Connect-website .
Maak een tabel en vul scripts :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Afgeleide kolomtransformatie binnen gegevensstroomtaak :
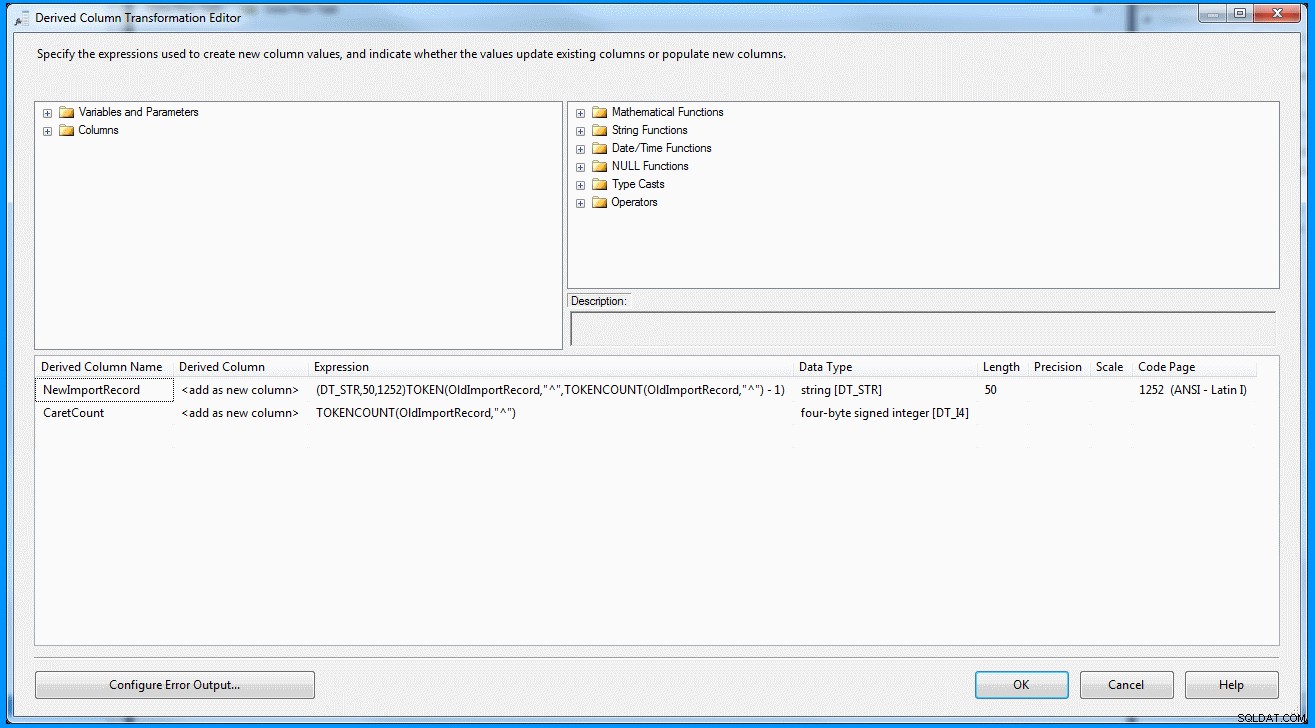
Gegevens in bron- en bestemmingstabellen :