In een vorige post hebben we besproken hoe u controle kunt krijgen over het failover-proces in ClusterControl door gebruik te maken van witte lijsten en zwarte lijsten. In dit bericht gaan we een soortgelijk concept bespreken. Maar deze keer zullen we ons concentreren op integraties met externe scripts en applicaties via tal van hooks die beschikbaar worden gesteld door ClusterControl.
Infrastructuuromgevingen kunnen op verschillende manieren worden gebouwd, omdat er vaak veel opties zijn om uit te kiezen voor een bepaald stukje van de puzzel. Hoe definiëren we naar welk databaseknooppunt we moeten schrijven? Gebruik je virtueel IP? Gebruik je een soort van service discovery? Misschien ga je met DNS-vermeldingen en verander je de A-records wanneer dat nodig is? Hoe zit het met de proxy-laag? Vertrouwt u op de 'read_only'-waarde voor uw proxy's om te beslissen over de schrijver, of brengt u de vereiste wijzigingen rechtstreeks aan in de configuratie van de proxy? Hoe gaat uw omgeving om met omschakelingen? Kun je gewoon doorgaan en het uitvoeren, of moet je misschien eerst wat voorbereidende acties ondernemen? Bijvoorbeeld het stoppen van een aantal andere processen voordat u daadwerkelijk de overstap kunt maken?
Het is niet mogelijk om een failover-software vooraf te configureren om alle verschillende instellingen te dekken die mensen kunnen maken. Dit is de belangrijkste reden om verschillende manieren te bieden om aan te sluiten op het failover-proces. Op deze manier kun je het aanpassen en het mogelijk maken om alle subtiliteiten van je opstelling aan te kunnen. In deze blogpost bekijken we hoe het failoverproces van ClusterControl kan worden aangepast met behulp van verschillende pre- en post-failoverscripts. We zullen ook enkele voorbeelden bespreken van wat kan worden bereikt met dergelijk maatwerk.
ClusterControl integreren
ClusterControl biedt verschillende hooks die kunnen worden gebruikt om externe scripts in te pluggen. Hieronder vindt u een lijst met enige uitleg.
- Replicatie_onfail_failover_script - dit script wordt uitgevoerd zodra is ontdekt dat een failover nodig is. Als het script niet-nul retourneert, wordt de failover geforceerd om af te breken. Als het script is gedefinieerd maar niet wordt gevonden, wordt de failover afgebroken. Vier argumenten worden aan het script toegevoegd:arg1='all servers' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' en worden als volgt doorgegeven:'scriptname arg1 arg2 arg3 arg4'. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replicatie_pre_failover_script - dit script wordt uitgevoerd voordat de failover plaatsvindt, maar nadat een kandidaat is gekozen en het mogelijk is om door te gaan met het failoverproces. Als het script niet-nul retourneert, wordt de failover geforceerd om af te breken. Als het script is gedefinieerd maar niet wordt gevonden, wordt de failover afgebroken. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replicatie_post_failover_script - dit script wordt uitgevoerd nadat de failover heeft plaatsgevonden. Als het script niet-nul retourneert, wordt er een waarschuwing in het takenlogboek geschreven. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replication_post_unsuccessful_failover_script - Dit script wordt uitgevoerd nadat de failoverpoging is mislukt. Als het script niet-nul retourneert, wordt er een waarschuwing in het takenlogboek geschreven. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replicatie_failed_reslave_failover_script - dit script wordt uitgevoerd nadat een nieuwe master is gepromoveerd en als het opnieuw tot slaaf maken van de slaves naar de nieuwe master mislukt. Als het script niet-nul retourneert, wordt er een waarschuwing in het takenlogboek geschreven. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replicatie_pre_switchover_script - dit script wordt uitgevoerd voordat de omschakeling plaatsvindt. Als het script niet-nul retourneert, wordt de omschakeling gedwongen te mislukken. Als het script is gedefinieerd maar niet wordt gevonden, wordt de omschakeling afgebroken. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
- Replicatie_post_switchover_script - dit script wordt uitgevoerd nadat de omschakeling heeft plaatsgevonden. Als het script niet-nul retourneert, wordt er een waarschuwing in het takenlogboek geschreven. Het script moet toegankelijk zijn op de controller en uitvoerbaar zijn.
Zoals u kunt zien, bestrijken de hooks de meeste gevallen waarin u mogelijk een aantal acties wilt ondernemen - voor en na een omschakeling, voor en na een failover, wanneer de reslave is mislukt of wanneer de failover is mislukt. Alle scripts worden aangeroepen met vier argumenten (die al dan niet in het script worden verwerkt, het is niet vereist dat het script ze allemaal gebruikt):alle servers, hostnaam (of IP - zoals gedefinieerd in ClusterControl) van de oude master, hostnaam (of IP - zoals gedefinieerd in ClusterControl) van de master-kandidaat en de vierde, alle replica's van de oude master. Die opties zouden het mogelijk moeten maken om de meeste gevallen af te handelen.
Al deze hooks moeten worden gedefinieerd in een configuratiebestand voor een bepaalde cluster (/etc/cmon.d/cmon_X.cnf waarbij X de id van de cluster is). Een voorbeeld kan er als volgt uitzien:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shAangeroepen scripts moeten natuurlijk uitvoerbaar zijn, anders kan cmon ze niet uitvoeren. Laten we nu even het failoverproces in ClusterControl doorlopen en kijken wanneer de externe scripts worden uitgevoerd.
Failover-proces in ClusterControl
We hebben alle beschikbare haken gedefinieerd:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shHierna moet u het cmon-proces opnieuw starten. Als het klaar is, zijn we klaar om de failover te testen. De originele topologie ziet er als volgt uit:
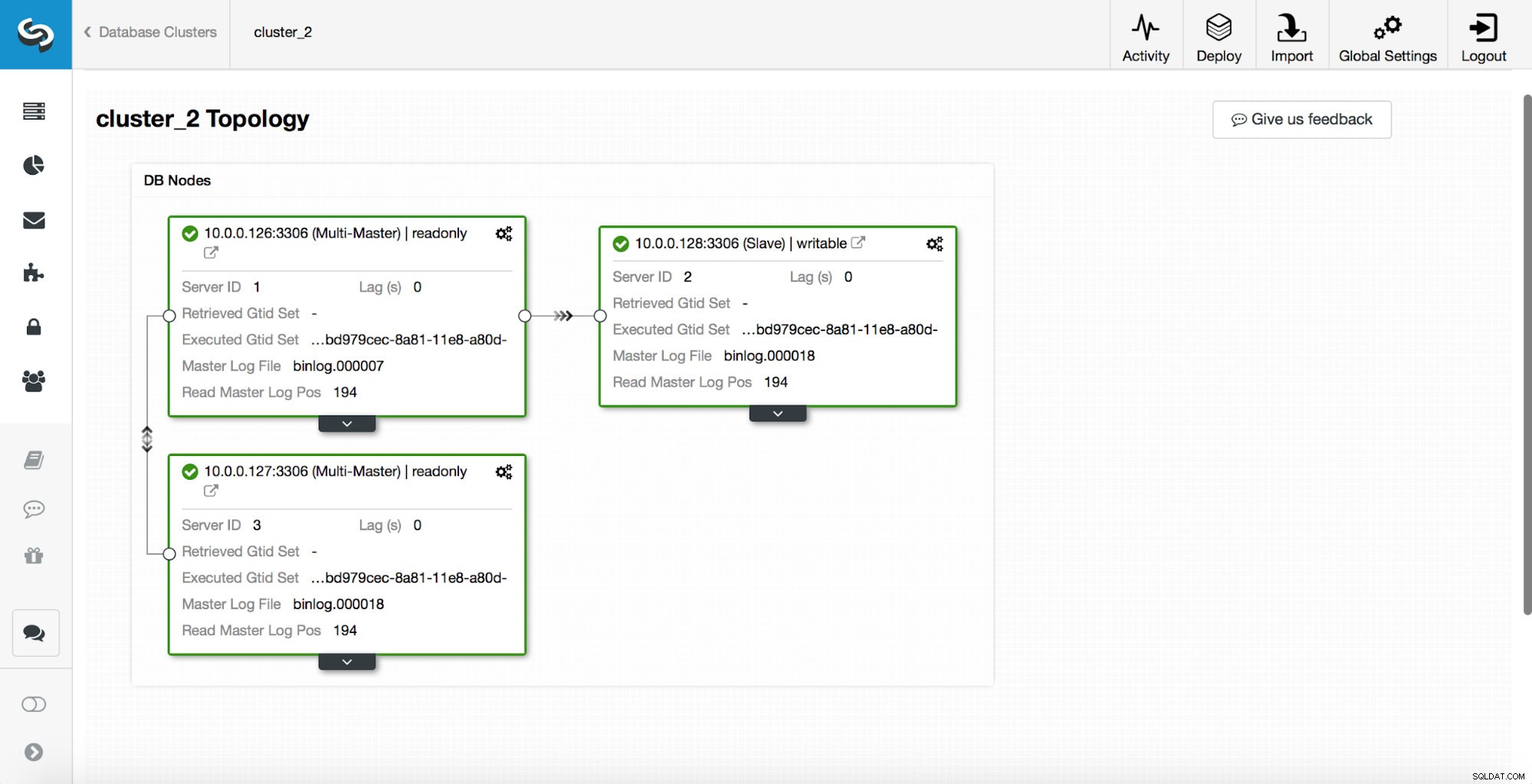
Een master is uitgeschakeld en het failoverproces is gestart. Houd er rekening mee dat de recentere logboekvermeldingen bovenaan staan, dus u wilt de failover van onder naar boven volgen.
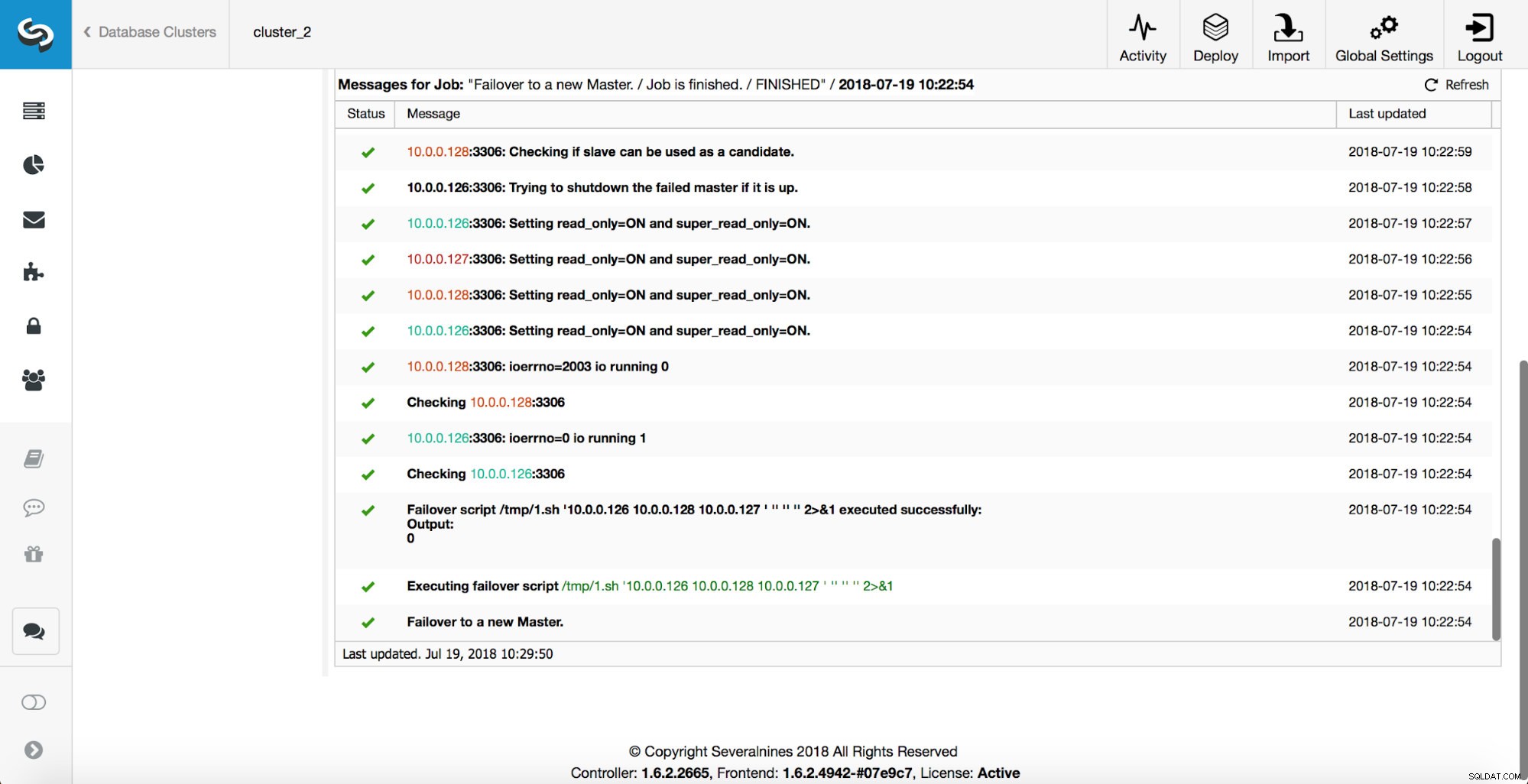
Zoals u kunt zien, activeert het onmiddellijk nadat de failover-taak is gestart de 'replication_onfail_failover_script' hook. Vervolgens worden alle bereikbare hosts gemarkeerd als alleen-lezen en probeert ClusterControl te voorkomen dat de oude master wordt uitgevoerd.
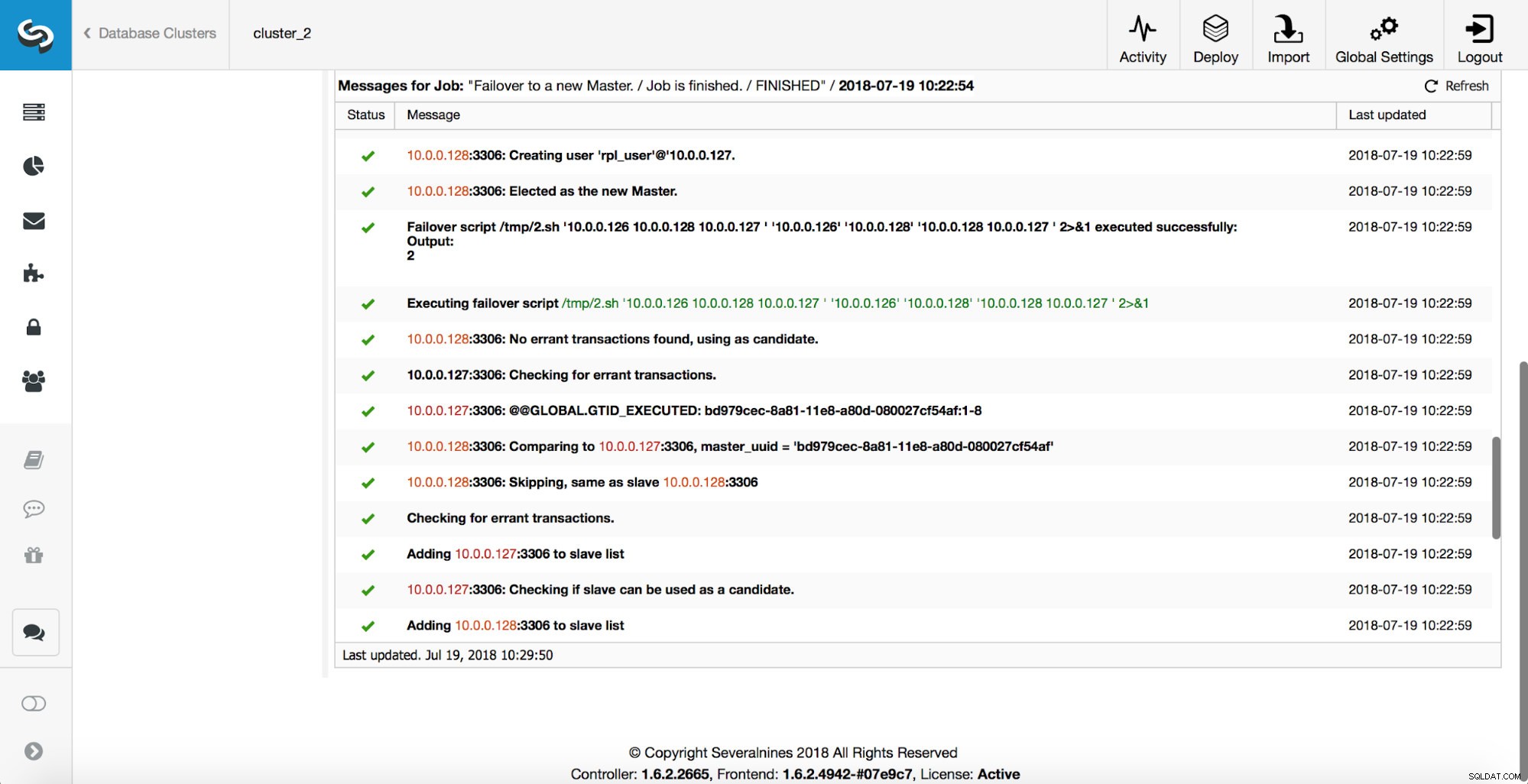
Vervolgens wordt de hoofdkandidaat gekozen en worden er gezondheidscontroles uitgevoerd. Zodra bevestigd is dat de master-kandidaat kan worden gebruikt als een nieuwe master, wordt het 'replication_pre_failover_script' uitgevoerd.
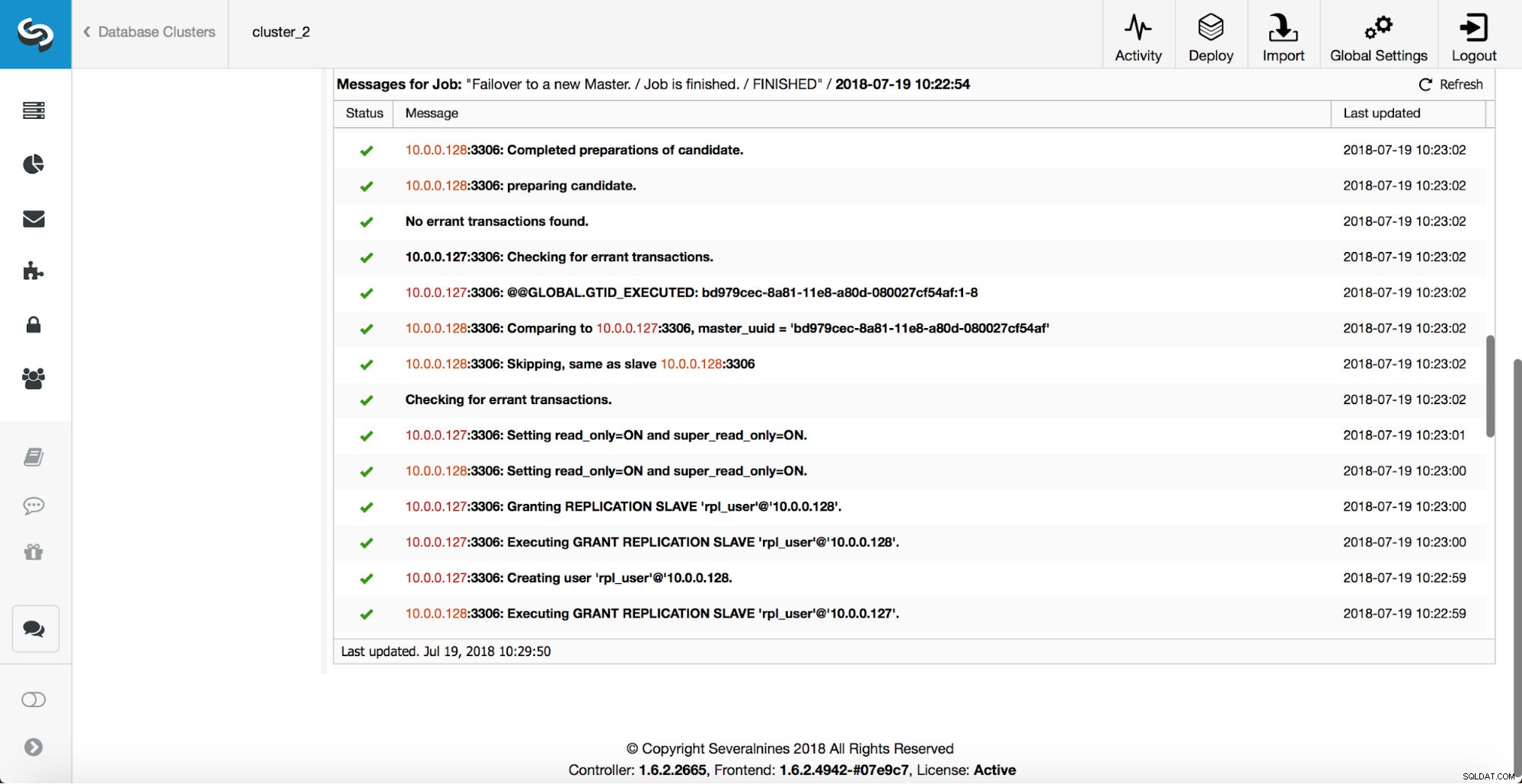
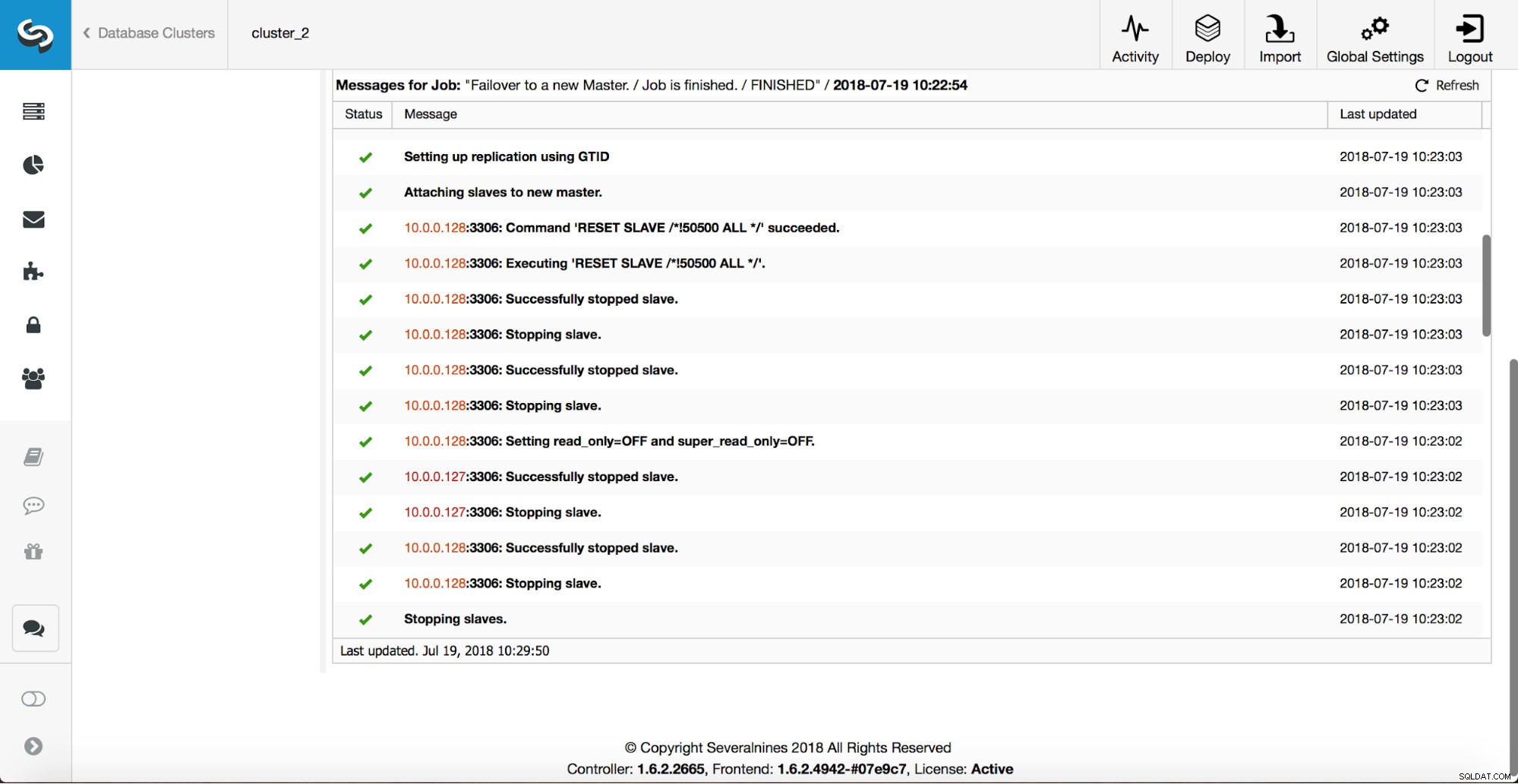
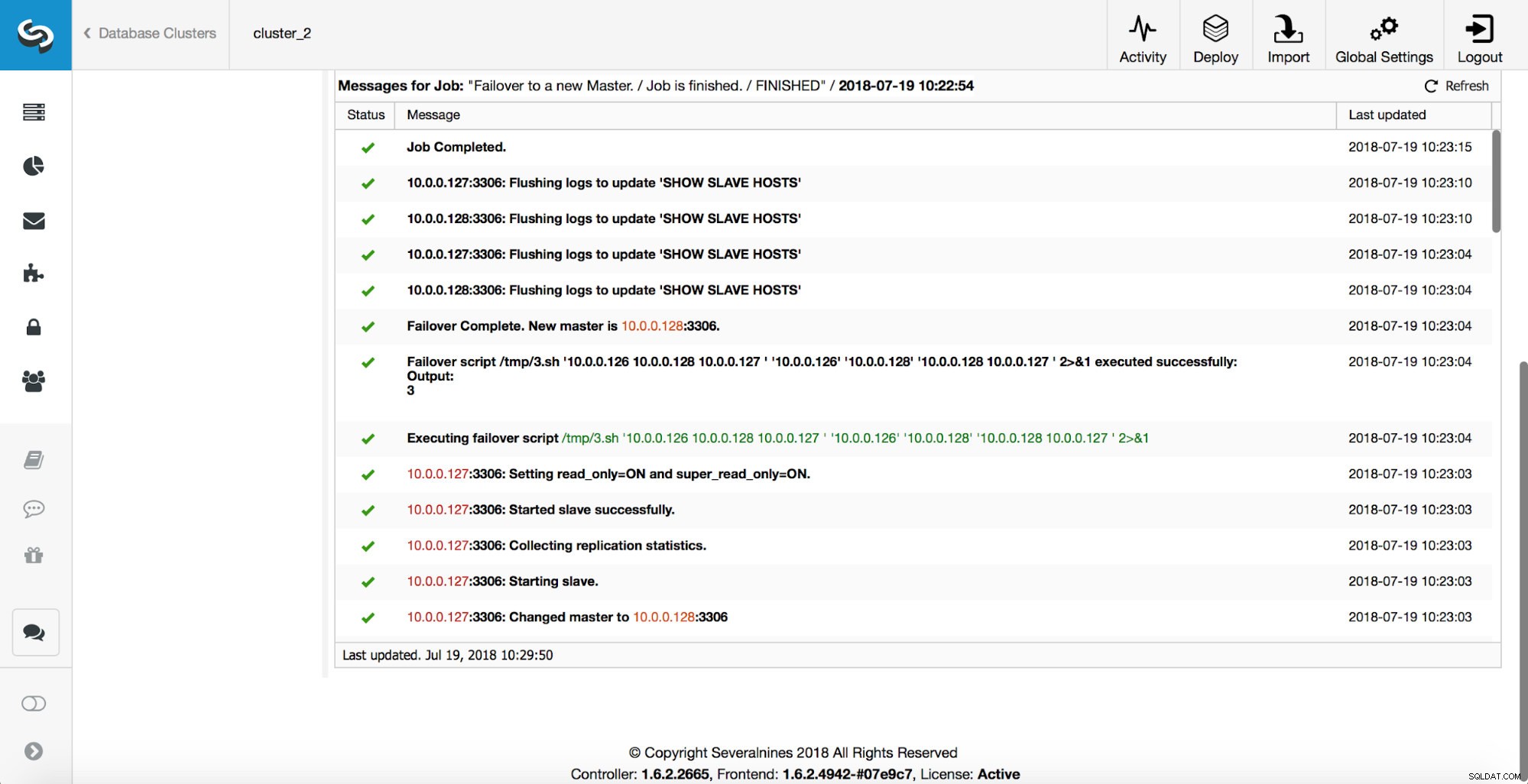
Er worden meer controles uitgevoerd, replica's worden gestopt en als slaaf gemaakt van de nieuwe master. Eindelijk, nadat de failover is voltooid, wordt een laatste hook, 'replication_post_failover_script', geactiveerd.
Wanneer haken nuttig kunnen zijn?
In deze sectie zullen we een aantal voorbeelden bespreken waarin het een goed idee kan zijn om externe scripts te implementeren. We zullen niet in details treden omdat die te nauw verband houden met een bepaalde omgeving. Het is meer een lijst met suggesties die nuttig kunnen zijn om te implementeren.
STONITH-script
Shoot The Other Node In The Head (STONITH) is een proces om ervoor te zorgen dat de oude meester, die dood is, dood blijft (en ja... we houden niet van zombies die rondzwerven in onze infrastructuur). Het laatste dat u waarschijnlijk wilt, is een niet-reagerende oude master die vervolgens weer online gaat en als resultaat krijgt u twee beschrijfbare masters. Er zijn voorzorgsmaatregelen die u kunt nemen om ervoor te zorgen dat de oude master niet wordt gebruikt, zelfs niet als deze opnieuw verschijnt, en het is veiliger om offline te blijven. Manieren om ervoor te zorgen dat dit kan verschillen van omgeving tot omgeving. Daarom is er hoogstwaarschijnlijk geen ingebouwde ondersteuning voor STONITH in de failover-tool. Afhankelijk van de omgeving, wil je misschien de CLI-opdracht uitvoeren die een VM stopt (en zelfs verwijdert) waarop de oude master draait. Als u een installatie op locatie heeft, heeft u mogelijk meer controle over de hardware. Het is misschien mogelijk om een soort van beheer op afstand te gebruiken (geïntegreerde Lights-out of een andere externe toegang tot de server). Mogelijk hebt u ook toegang tot beheersbare stopcontacten en schakelt u de stroom in een ervan uit om ervoor te zorgen dat de server nooit meer start zonder menselijke tussenkomst.
Servicedetectie
We noemden al iets over service discovery. Er zijn talloze manieren om informatie over een replicatietopologie op te slaan en te detecteren welke host een master is. Absoluut, een van de meer populaire opties is om etc.d of Consul te gebruiken om gegevens over de huidige topologie op te slaan. Hiermee kan een applicatie of proxy op deze data vertrouwen om het verkeer naar de juiste node te sturen. ClusterControl (net als de meeste tools die failover-afhandeling ondersteunen) heeft geen directe integratie met etc.d of Consul. De taak om de topologiegegevens bij te werken ligt bij de gebruiker. Ze kan hooks zoals replication_post_failover_script of replication_post_switchover_script gebruiken om enkele van de scripts aan te roepen en de vereiste wijzigingen aan te brengen. Een andere vrij gebruikelijke oplossing is om DNS te gebruiken om verkeer naar correcte instanties te leiden. Als je de Time-To-Live van een DNS-record laag houdt, zou je een domein moeten kunnen definiëren dat naar je master verwijst (d.w.z. writes.cluster1.example.com). Dit vereist een wijziging in de DNS-records en, nogmaals, hooks zoals replication_post_failover_script of replication_post_switchover_script kunnen erg handig zijn om de vereiste wijzigingen aan te brengen nadat een failover heeft plaatsgevonden.
Proxy-herconfiguratie
Elke proxyserver die wordt gebruikt, moet verkeer naar de juiste instanties sturen. Afhankelijk van de proxy zelf, kan de manier waarop een masterdetectie wordt uitgevoerd ofwel (gedeeltelijk) hardcoded zijn of kan de gebruiker zelf bepalen wat hij of zij wil. Het ClusterControl-failovermechanisme is zo ontworpen dat het goed integreert met proxy's die het heeft geïmplementeerd en geconfigureerd. Het kan nog steeds voorkomen dat er proxy's zijn die niet door ClusterControl zijn geïnstalleerd en dat er enkele handmatige acties moeten worden uitgevoerd terwijl de failover wordt uitgevoerd. Dergelijke proxy's kunnen ook worden geïntegreerd met het ClusterControl-failoverproces via externe scripts en hooks zoals replication_post_failover_script of replication_post_switchover_script.
Aanvullende logboekregistratie
Het kan voorkomen dat u gegevens van het failover-proces wilt verzamelen voor foutopsporingsdoeleinden. ClusterControl heeft uitgebreide afdrukken om het proces te kunnen volgen en te achterhalen wat er is gebeurd en waarom. Toch kan het voorkomen dat u wat aanvullende, aangepaste informatie wilt verzamelen. In principe kunnen alle hooks hier worden gebruikt - u kunt de initiële status verzamelen, vóór de failover kunt u de status van de omgeving volgen in alle stadia van de failover.