De tijd dat een database werd ingezet als een enkel knooppunt of exemplaar, is lang voorbij - een krachtige, zelfstandige server die de taak had om alle verzoeken aan de database af te handelen. Verticaal schalen was de juiste keuze - vervang de server door een andere, nog krachtigere. In deze tijden hoefde men zich niet echt druk te maken over de netwerkprestaties. Zolang de verzoeken binnenkwamen, was alles goed.
Maar tegenwoordig worden databases gebouwd als clusters met knooppunten die via een netwerk met elkaar zijn verbonden. Het is niet altijd een snel, lokaal netwerk. Nu bedrijven wereldwijde schaal bereiken, moet de database-infrastructuur zich ook over de hele wereld uitstrekken, dicht bij klanten blijven en latentie verminderen. Het gaat gepaard met extra uitdagingen waarmee we te maken krijgen bij het ontwerpen van een databaseomgeving met hoge beschikbaarheid. In deze blogpost gaan we in op de netwerkproblemen waarmee u te maken kunt krijgen en geven we enkele suggesties over hoe hiermee om te gaan.
Twee hoofdopties voor MySQL of MariaDB HA
We hebben dit specifieke onderwerp vrij uitgebreid behandeld in een van de whitepapers, maar laten we eens kijken naar de twee belangrijkste manieren om hoge beschikbaarheid voor MySQL en MariaDB te bouwen.
Galera-cluster
Galera Cluster is een gedeelde-niets, vrijwel synchrone clustertechnologie voor MySQL. Het maakt het mogelijk om multi-writer setups te bouwen die zich over de hele wereld kunnen uitstrekken. Galera gedijt goed in omgevingen met lage latentie, maar het kan ook worden geconfigureerd om te werken met lange WAN-verbindingen. Galera heeft een ingebouwd quorummechanisme dat ervoor zorgt dat gegevens niet in gevaar komen in het geval van netwerkpartitionering van sommige knooppunten.
MySQL-replicatie
MySQL-replicatie kan asynchroon of semi-synchroon zijn. Beide zijn ontworpen om grootschalige replicatieclusters te bouwen. Zoals bij elke andere master-slave- of primair-secundaire replicatieconfiguratie, kan er maar één schrijver zijn, de master. Andere nodes, slaves, worden gebruikt voor failover-doeleinden omdat ze de kopie van de dataset van de maser bevatten. Slaves kunnen ook worden gebruikt om de gegevens te lezen en een deel van de werklast van de master te ontlasten.
Beide oplossingen hebben hun eigen beperkingen en kenmerken, beide hebben verschillende problemen. Beide kunnen worden beïnvloed door onstabiele netwerkverbindingen. Laten we eens kijken naar die beperkingen en hoe we de omgeving kunnen ontwerpen om de impact van een onstabiele netwerkinfrastructuur te minimaliseren.
Galera Cluster - Netwerkproblemen
Laten we eerst eens kijken naar Galera Cluster. Zoals we hebben besproken, werkt het het beste in een omgeving met lage latentie. Een van de belangrijkste latency-gerelateerde problemen in Galera is de manier waarop Galera de schrijfbewerkingen afhandelt. We zullen in deze blog niet op alle details ingaan, maar verder lezen in onze Galera Cluster voor MySQL-tutorial. Het komt erop neer dat, vanwege het certificeringsproces voor schrijven, waarbij alle knooppunten in het cluster het erover eens moeten zijn of het schrijven kan worden toegepast of niet, uw schrijfprestaties voor een enkele rij strikt worden beperkt door de netwerkrondreistijd tussen de schrijver knooppunt en het verst verwijderde knooppunt. Zolang de latentie acceptabel is en zolang je niet te veel hotspots in je data hebt, kunnen WAN-setups prima werken. Het probleem begint wanneer de netwerklatentie van tijd tot tijd piekt. Het schrijven duurt dan 3 of 4 keer langer dan normaal en als gevolg daarvan kunnen databases overbelast raken met langlopende schrijfacties.
Een van de geweldige kenmerken van Galera Cluster is de mogelijkheid om de clusterstatus te detecteren en te reageren op netwerkpartitionering. Als een knooppunt van het cluster niet kan worden bereikt, wordt het uit het cluster verwijderd en kan het geen schrijfbewerkingen uitvoeren. Dit is cruciaal voor het handhaven van de integriteit van de gegevens gedurende de tijd dat het cluster wordt gesplitst - alleen de meerderheid van het cluster accepteert schrijfbewerkingen. De minderheid zal klagen. Om dit aan te pakken, introduceert Galera een breed scala aan controles en configureerbare time-outs om valse waarschuwingen over zeer tijdelijke netwerkproblemen te voorkomen. Helaas, als het netwerk onbetrouwbaar is, zal Galera Cluster niet correct kunnen werken - knooppunten zullen het cluster beginnen te verlaten en zich er later bij aansluiten. Het zal vooral problematisch zijn als we een Galera-cluster hebben die zich over het WAN uitstrekt - afzonderlijke delen van het cluster kunnen willekeurig verdwijnen als het onderling verbonden netwerk niet goed werkt.
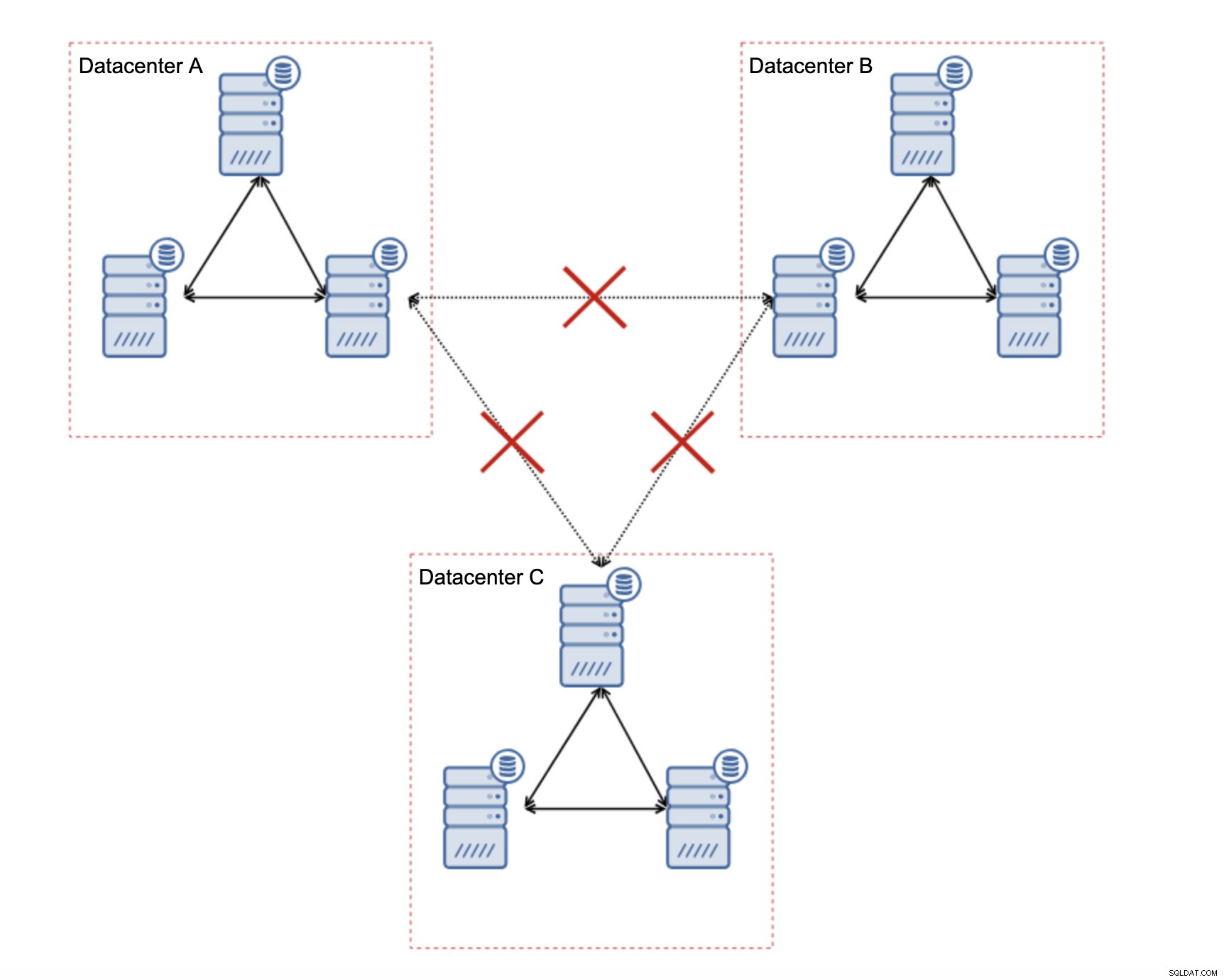
Hoe een Galera-cluster ontwerpen voor een instabiel netwerk?
Allereerst, als u netwerkproblemen heeft binnen het enkele datacenter, kunt u niet veel doen, tenzij u die problemen op de een of andere manier kunt oplossen. Een onbetrouwbaar lokaal netwerk is een no go voor Galera Cluster, je moet heroverwegen om een andere oplossing te gebruiken (hoewel, om eerlijk te zijn, een onbetrouwbaar netwerk altijd een probleem zal zijn). Aan de andere kant, als de problemen alleen verband houden met WAN-verbindingen (en dit is een van de meest typische gevallen), is het misschien mogelijk om WAN Galera-koppelingen te vervangen door reguliere asynchrone replicatie (als de Galera WAN-afstemming niet heeft geholpen).
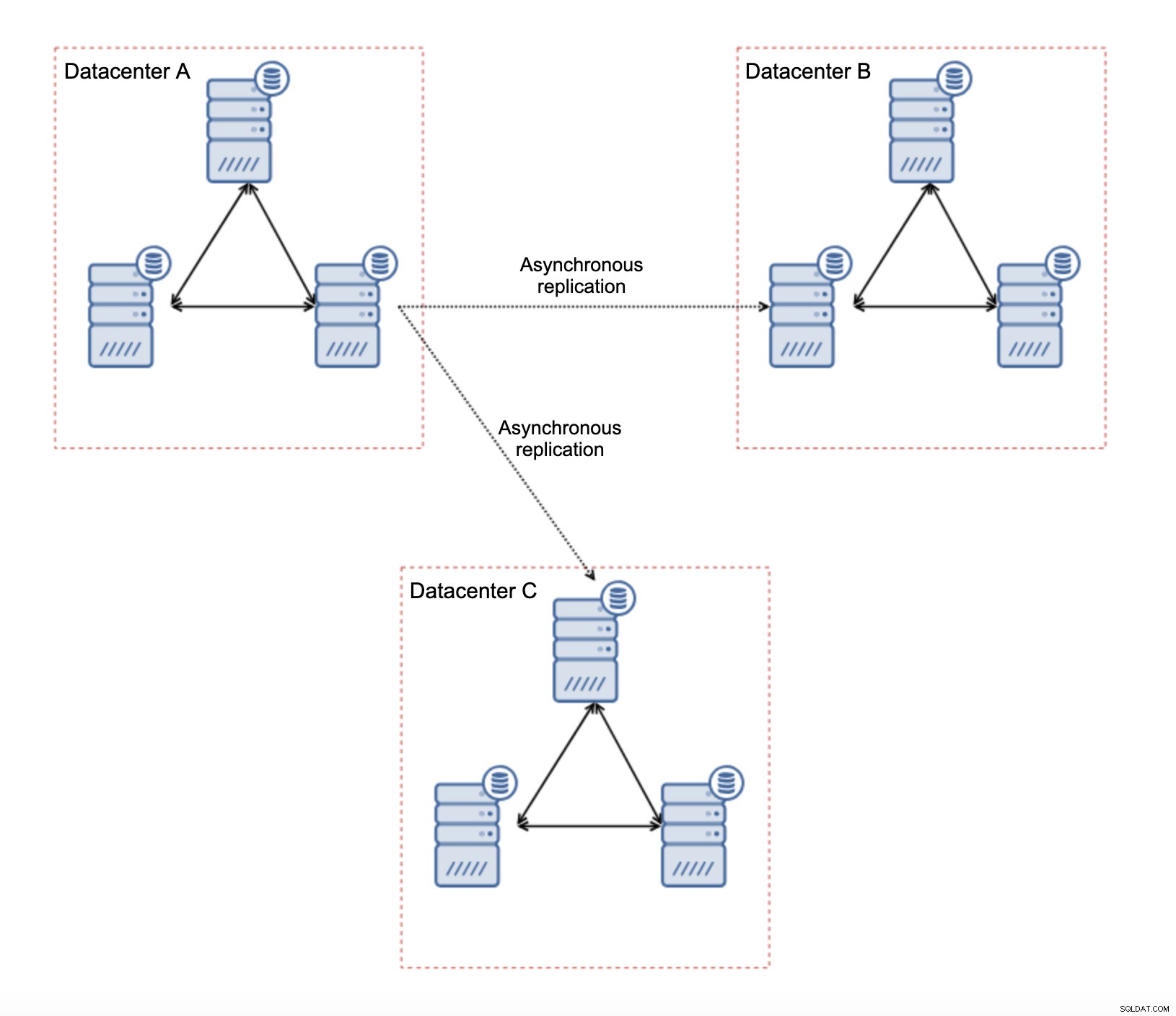
Er zijn verschillende inherente beperkingen in deze opstelling - het belangrijkste probleem is dat het schrijven vroeger lokaal gebeurde. Nu moeten alle schrijfbewerkingen naar het "master" -datacenter gaan (DC A in ons geval). Dit is niet zo erg als het klinkt. Houd er rekening mee dat in een volledig Galera-omgeving het schrijven wordt vertraagd door de latentie tussen knooppunten in verschillende datacenters. Zelfs lokale schrijfacties zullen worden beïnvloed. Het zal min of meer dezelfde vertraging zijn als bij een asynchrone installatie waarbij u de schrijfbewerkingen via WAN naar het 'master'-datacenter zou sturen.
Het gebruik van asynchrone replicatie brengt alle problemen met zich mee die typisch zijn voor asynchrone replicatie. Replicatievertraging kan een probleem worden - niet dat Galera performanter zou zijn, het is gewoon dat Galera het verkeer zou vertragen via flow control, terwijl replicatie geen enkel mechanisme heeft om het verkeer op de master af te remmen.
Een ander probleem is de failover:als het "master" Galera-knooppunt (degene die fungeert als de master voor de slaves in andere datacenters) zou falen, moet een mechanisme worden gecreëerd om slaves opnieuw te verwijzen naar een ander, werkend masterknooppunt. Het kan een soort script zijn, het is ook mogelijk om iets met VIP te proberen waarbij de "slave" Galera-cluster slaven van Virtual IP die altijd wordt toegewezen aan de levende Galera-node in de "master" -cluster.
Het belangrijkste voordeel van een dergelijke opstelling is dat we de WAN Galera-link verwijderen, wat betekent dat ons "master" -cluster niet wordt vertraagd door het feit dat sommige knooppunten geografisch gescheiden zijn. Zoals we al zeiden, verliezen we de mogelijkheid om in alle datacenters te schrijven, maar latency-wise schrijven over het WAN is hetzelfde als lokaal schrijven naar het Galera-cluster dat zich over het WAN uitstrekt. Als gevolg hiervan zou de algehele latentie moeten verbeteren. Asynchrone replicatie is ook minder kwetsbaar voor de onstabiele netwerken. In het ergste geval wordt de replicatielink verbroken en wordt deze opnieuw gemaakt wanneer de netwerken convergeren.
Hoe MySQL-replicatie ontwerpen voor een instabiel netwerk?
In de vorige sectie hebben we het Galera-cluster behandeld en een oplossing was om asynchrone replicatie te gebruiken. Hoe ziet het eruit in een gewone asynchrone replicatieconfiguratie? Laten we eens kijken hoe een onstabiel netwerk de grootste verstoringen kan veroorzaken in de replicatie-instellingen.
Allereerst latentie - een van de belangrijkste pijnpunten voor Galera Cluster. In het geval van replicatie is het bijna een non-issue. Tenzij u semi-synchrone replicatie gebruikt, dat wil zeggen, in dat geval zal een verhoogde latentie het schrijven vertragen. Bij asynchrone replicatie heeft latentie geen invloed op de schrijfprestaties. Het kan echter enige invloed hebben op de replicatievertraging. Het is niet zo belangrijk als het was voor Galera, maar je kunt meer vertragingspieken en over het algemeen minder stabiele replicatieprestaties verwachten als het netwerk tussen knooppunten lijdt aan een hoge latentie. Dit is voornamelijk te wijten aan het feit dat de master net zo goed meerdere schrijfbewerkingen kan uitvoeren voordat de gegevensoverdracht naar de slave kan worden gestart op een netwerk met hoge latentie.
De instabiliteit van het netwerk kan zeker gevolgen hebben voor replicatiekoppelingen, maar het is, nogmaals, niet zo kritiek. MySQL-slaves zullen proberen opnieuw verbinding te maken met hun masters en de replicatie zal beginnen.
Het belangrijkste probleem met MySQL-replicatie is eigenlijk iets dat Galera Cluster intern oplost - netwerkpartitionering. We hebben het over netwerkpartitionering als de toestand waarin segmenten van het netwerk van elkaar worden gescheiden. MySQL-replicatie maakt gebruik van één enkele writer-node - master. Ongeacht hoe u uw omgeving ontwerpt, u moet uw schrijfbewerkingen naar de master sturen. Als de master niet beschikbaar is (om welke reden dan ook), kan de toepassing zijn werk niet doen, tenzij deze in een soort van alleen-lezen modus draait. Daarom is het nodig om zo snel mogelijk de nieuwe master te kiezen. Hier komen de problemen naar voren.
Ten eerste, hoe u kunt zien welke host een master is en welke niet. Een van de gebruikelijke manieren is om de variabele "read_only" te gebruiken om slaves van de master te onderscheiden. Als node read_only heeft ingeschakeld (set read_only=1), is het een slave (aangezien slaves geen directe schrijfbewerkingen zouden moeten verwerken). Als het knooppunt read_only uitgeschakeld heeft (set read_only=0), is het een master. Om dingen veiliger te maken, is een gebruikelijke benadering om read_only=1 in de MySQL-configuratie in te stellen - in het geval van een herstart is het veiliger als de node als slaaf verschijnt. Dergelijke "taal" kan worden begrepen door proxy's zoals ProxySQL of MaxScale.
Laten we een voorbeeld bekijken.
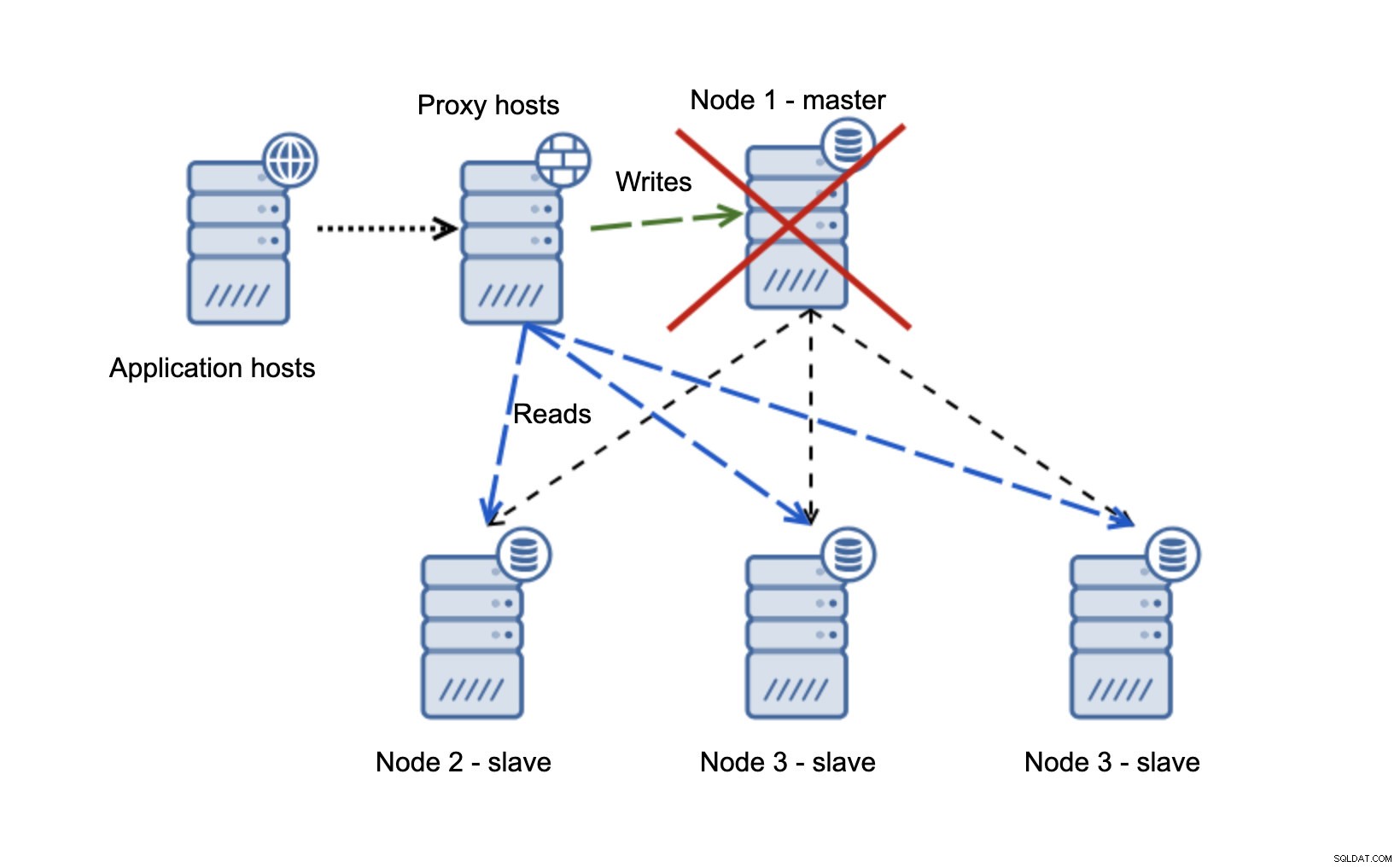
We hebben applicatiehosts die verbinding maken met de proxylaag. Proxy's voeren de lees-/schrijfsplitsing uit en sturen SELECT's naar slaves en schrijven naar master. Als de master niet beschikbaar is, wordt een failover uitgevoerd, wordt een nieuwe master gepromoveerd, de proxylaag detecteert dat en begint schrijfbewerkingen naar een ander knooppunt te verzenden.
Als node1 opnieuw wordt opgestart, komt het met read_only=1 en wordt het als slaaf gedetecteerd. Het is niet ideaal omdat het niet repliceert, maar het is acceptabel. In het ideale geval zou de oude master helemaal niet moeten verschijnen totdat hij is herbouwd en van de nieuwe master is afgebouwd.
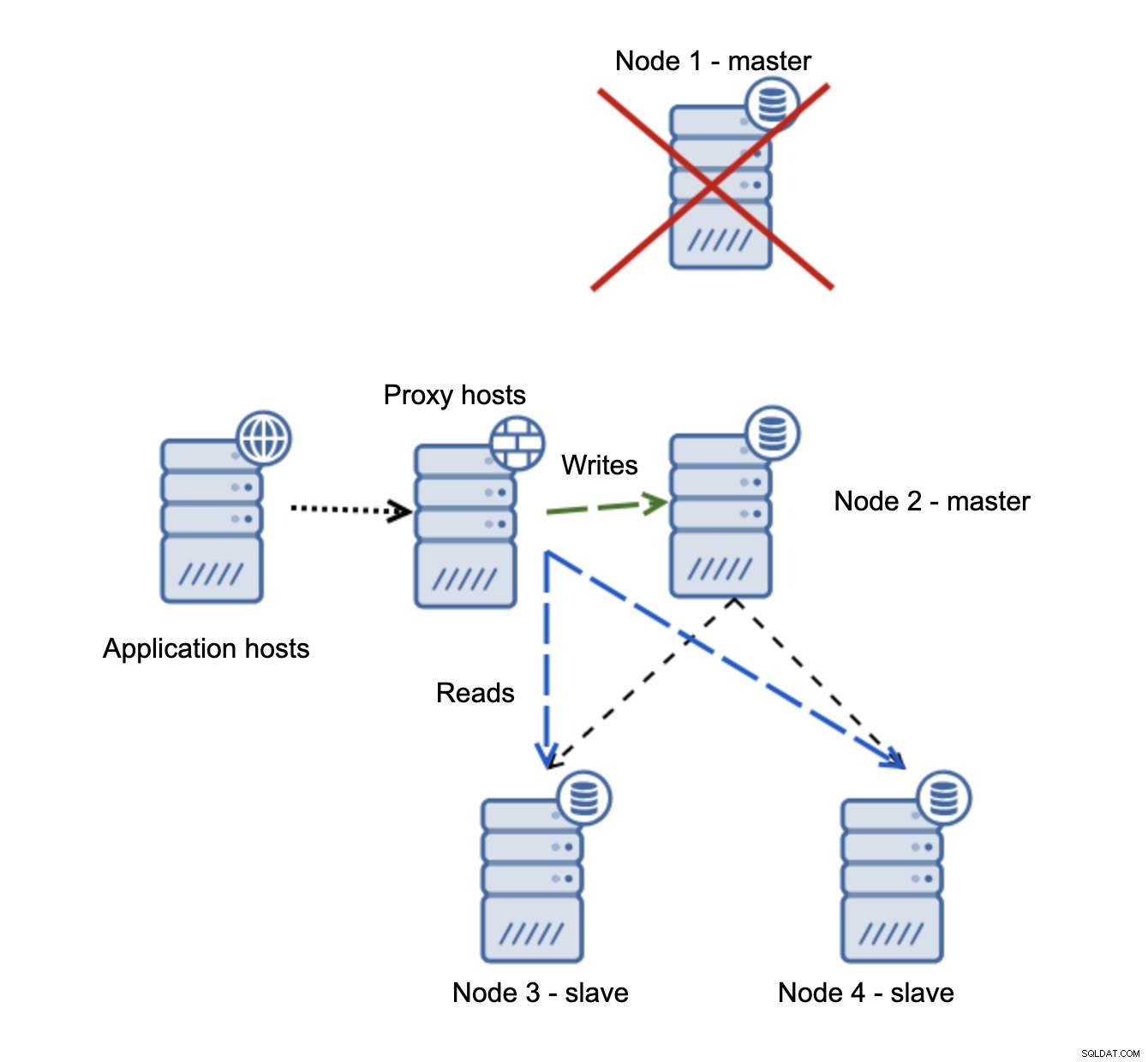
Veel problematischer is de situatie als we te maken hebben met netwerkpartitionering. Laten we dezelfde setup bekijken:applicatielaag, proxylaag en databases.
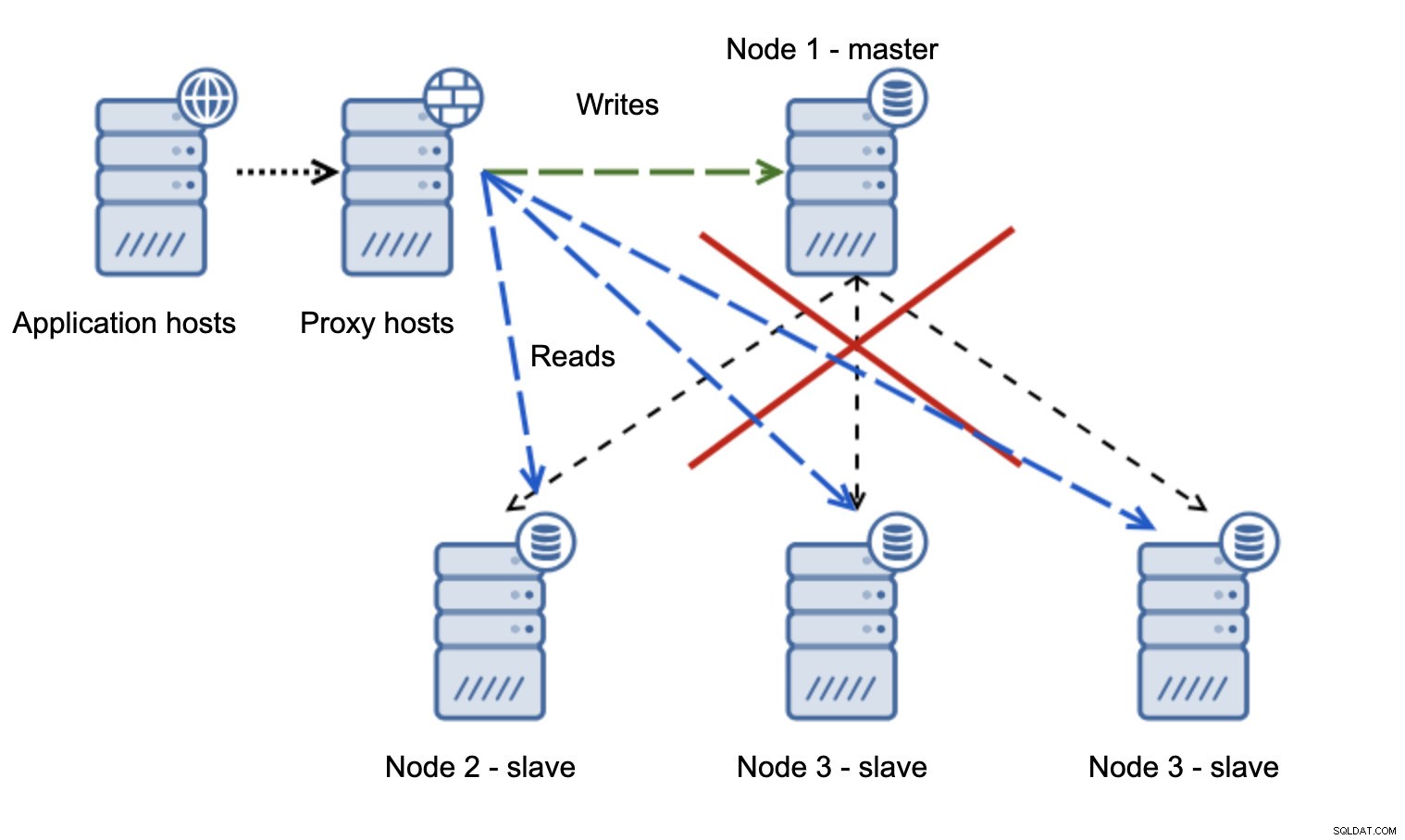
Wanneer het netwerk de master onbereikbaar maakt, is de toepassing niet bruikbaar omdat er geen schrijfbewerkingen zijn die hun bestemming bereiken. Nieuwe master wordt gepromoot, schrijfbewerkingen worden ernaar doorgestuurd. Wat gebeurt er dan als de netwerkproblemen ophouden en de oude meester bereikbaar wordt? Het is niet gestopt, daarom gebruikt het nog steeds read_only=0:
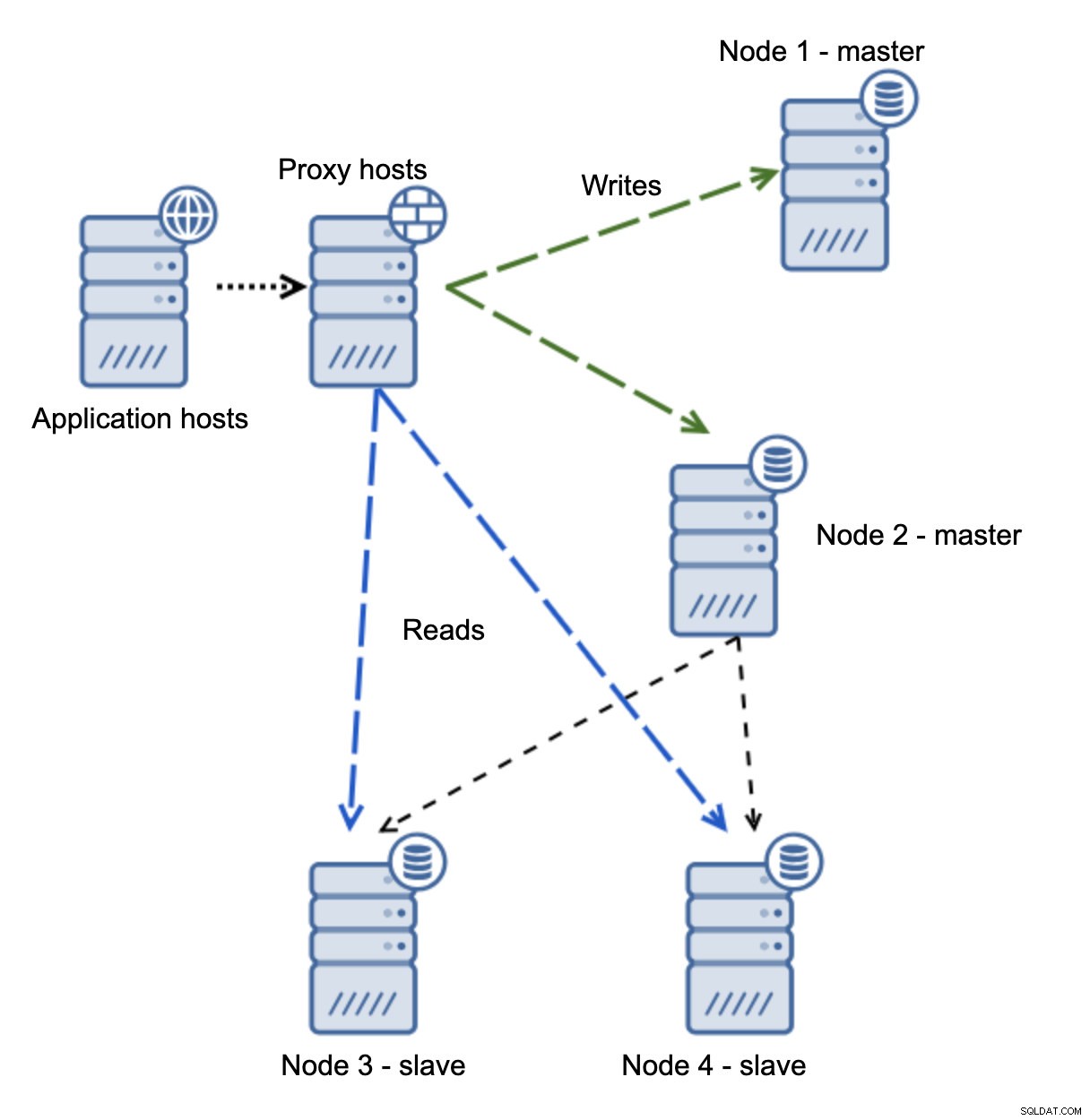
Je bent nu in een gespleten brein beland, toen schrijven naar twee knooppunten werd geleid. Deze situatie is behoorlijk slecht, aangezien het samenvoegen van uiteenlopende datasets enige tijd kan duren en het een behoorlijk complex proces is.
Wat kan er gedaan worden om dit probleem te voorkomen? Er is geen wondermiddel, maar er kunnen enkele maatregelen worden genomen om de kans op een gespleten brein te minimaliseren.
Allereerst kunt u slimmer zijn in het detecteren van de status van de master. Hoe zien de slaven het? Kunnen ze ervan repliceren? Misschien kunnen sommige slaven nog steeds verbinding maken met de master, wat betekent dat de master actief is of in ieder geval het mogelijk maakt om deze te stoppen als dat nodig is. Hoe zit het met de proxy-laag? Zien alle proxy-knooppunten de master als niet beschikbaar? Als sommigen nog steeds verbinding kunnen maken, kunt u proberen die knooppunten te gebruiken om naar de master te ssh-en en deze te stoppen vóór de failover?
De failover-beheersoftware kan ook slimmer zijn in het detecteren van de status van het netwerk. Misschien gebruikt het RAFT of een ander clusterprotocol om een quorumbewuste cluster te bouwen. Als een software voor failoverbeheer het gesplitste brein kan detecteren, kan het ook een aantal acties ondernemen op basis hiervan, zoals bijvoorbeeld alle knooppunten in het gepartitioneerde segment instellen op alleen-lezen om ervoor te zorgen dat de oude master niet als beschrijfbaar wordt weergegeven wanneer de netwerken samenkomen.
U kunt ook tools zoals Consul of Etcd opnemen om de status van het cluster op te slaan. De proxylaag kan worden geconfigureerd om gegevens van Consul te gebruiken, niet de status van de read_only variabele. Het is dan aan de failover-beheersoftware om de nodige wijzigingen aan te brengen in Consul, zodat alle proxy's het verkeer naar een correcte, nieuwe master sturen.
Sommige van die hints kunnen zelfs worden gecombineerd om de storingsdetectie nog betrouwbaarder te maken. Al met al is het mogelijk om de kans dat het replicatiecluster last krijgt van onbetrouwbare netwerken te minimaliseren.
Zoals je kunt zien, of we het nu hebben over Galera of MySQL-replicatie, onstabiele netwerken kunnen een serieus probleem worden. Aan de andere kant, als je de omgeving correct ontwerpt, kun je het nog steeds laten werken. We hopen dat deze blogpost je zal helpen om omgevingen te creëren die stabiel zullen werken, zelfs als de netwerken dat niet zijn.