MySQL master-slave-replicatie is vrij eenvoudig en eenvoudig in te stellen. Dit is de belangrijkste reden waarom mensen voor deze technologie kiezen als eerste stap om een betere databasebeschikbaarheid te bereiken. Het gaat echter ten koste van complexiteit in beheer en onderhoud; het is aan de beheerder om de gegevensintegriteit te handhaven, vooral tijdens failover, failback, onderhoud, upgrade enzovoort.
Er zijn veel artikelen die beschrijven hoe u een failover-bewerking uitvoert voor het instellen van replicatie. We hebben dit onderwerp ook behandeld in deze blogpost, Inleiding tot failover voor MySQL-replicatie - de 101 Blog. In deze blogpost gaan we de taken na een ramp behandelen bij het herstellen naar de oorspronkelijke topologie - het uitvoeren van een failback-bewerking.
Waarom hebben we failback nodig?
De replicatieleider (master) is het meest kritieke knooppunt in een replicatieconfiguratie. Het vereist goede hardwarespecificaties om ervoor te zorgen dat het schrijfbewerkingen kan verwerken, replicatiegebeurtenissen kan genereren, kritieke leesbewerkingen kan verwerken enzovoort op een stabiele manier. Wanneer een failover vereist is tijdens noodherstel of onderhoud, is het misschien niet ongewoon dat we een nieuwe leider promoten met inferieure hardware. Deze situatie kan tijdelijk in orde zijn, maar op lange termijn moet de aangewezen master worden teruggebracht om de replicatie te leiden nadat deze als gezond wordt beschouwd.
In tegenstelling tot failover vindt failback-operatie meestal plaats in een gecontroleerde omgeving door middel van omschakeling, het gebeurt zelden in paniekmodus. Dit geeft het operatieteam wat tijd om zorgvuldig te plannen en de oefening te oefenen voor een soepele overgang. Het belangrijkste doel is simpelweg om de goede oude meester terug te brengen naar de nieuwste staat en de replicatie-instellingen te herstellen naar de oorspronkelijke topologie. Er zijn echter gevallen waarin failback van cruciaal belang is, bijvoorbeeld wanneer de pas gepromoveerde master niet werkte zoals verwacht en de algehele databaseservice beïnvloedde.
Hoe failback veilig uitvoeren?
Nadat de failover heeft plaatsgevonden, is de oude master uit de replicatieketen voor onderhoud of herstel. Om de omschakeling uit te voeren, moet men het volgende doen:
- Voorzie de oude master in de juiste staat, door hem de meest up-to-date slave te maken.
- Stop de toepassing.
- Controleer of alle slaven zijn ingehaald.
- Promoot de oude meester als de nieuwe leider.
- Wijs alle slaves opnieuw toe aan de nieuwe master.
- Start de applicatie door naar de nieuwe master te schrijven.
Overweeg de volgende replicatie-instellingen:
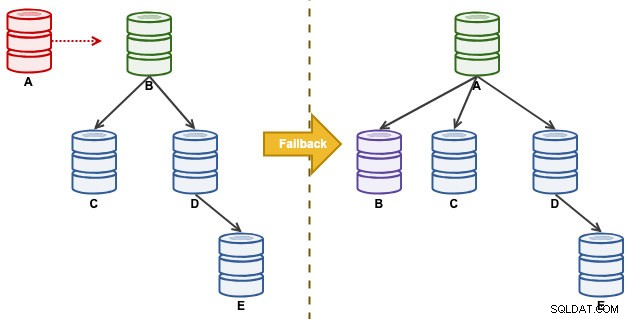
"A" was een master totdat een schijf vol-gebeurtenis de replicatieketen verwoestte. Na een failover-gebeurtenis werd onze replicatietopologie geleid door B en wordt deze gerepliceerd naar C tot E. De failback-oefening zal A terugbrengen als leider en de oorspronkelijke topologie van vóór de ramp herstellen. Houd er rekening mee dat alle knooppunten op MySQL 8.0.15 draaien met GTID ingeschakeld. Verschillende hoofdversies kunnen verschillende opdrachten en stappen gebruiken.
Hoewel onze architectuur er nu zo uitziet na een failover (overgenomen uit de Topologieweergave van ClusterControl):
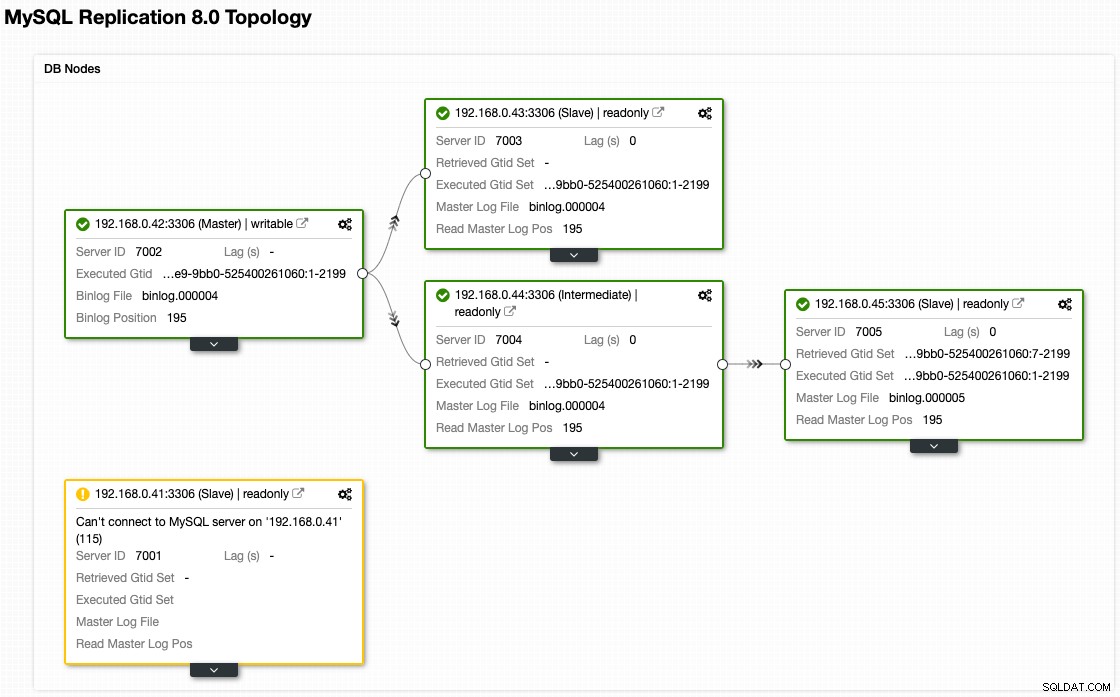
Node-inrichting
Voordat A een master kan zijn, moet deze worden bijgewerkt met de huidige databasestatus. De beste manier om dit te doen is door A als slaaf naar de actieve master te sturen, B. Aangezien alle knooppunten zijn geconfigureerd met log_slave_updates=ON (het betekent dat een slaaf ook binaire logs produceert), kunnen we andere slaves zoals C en D kiezen als de bron van de waarheid voor de eerste synchronisatie. Hoe dichter bij de actieve meester, hoe beter. Houd rekening met de extra belasting die dit kan veroorzaken bij het maken van de back-up. Dit onderdeel neemt de meeste failback-uren in beslag. Afhankelijk van de status van het knooppunt en de grootte van de dataset, kan het synchroniseren van de oude master enige tijd duren (dit kunnen uren en dagen zijn).
Zodra het probleem op "A" is opgelost en klaar is om deel te nemen aan de replicatieketen, is de beste eerste stap om te proberen te repliceren vanaf "B" (192.168.0.42) met de instructie CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Als de replicatie werkt, zou u het volgende in de replicatiestatus moeten zien:
Slave_IO_Running: Yes
Slave_SQL_Running: YesAls de replicatie mislukt, kijk dan naar de Last_IO_Error of Last_SQL_Error van de uitvoer van de slavestatus. Als u bijvoorbeeld de volgende fout ziet:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Vervolgens moeten we de replicatiegebruiker maken op de huidige actieve master, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Start vervolgens de slave opnieuw op A om opnieuw te beginnen met repliceren:
mysql> STOP SLAVE;
mysql> START SLAVE;Een andere veelvoorkomende fout die u ziet, is deze regel:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Dat betekent waarschijnlijk dat de slave problemen heeft met het lezen van het binaire logbestand van de huidige master. In sommige gevallen loopt de slave mogelijk ver achter waardoor de vereiste binaire gebeurtenissen om de replicatie te starten ontbreken in de huidige master, of het binaire bestand op de master is verwijderd tijdens de failover enzovoort. In dit geval is de beste manier om een volledige synchronisatie uit te voeren door een volledige back-up te maken op B en deze te herstellen op A. Op B kunt u mysqldump of Percona Xtrabackup gebruiken om een volledige back-up te maken:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupBreng het back-upbestand over naar A, initialiseer de bestaande MySQL-installatie opnieuw voor een correcte opschoning en voer databaseherstel uit:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordEenmaal hersteld, stelt u de replicatiekoppeling in naar de actieve master B (192.168.0.42) en schakelt u alleen-lezen in. Voer op A de volgende instructies uit:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Voor Percona Xtrabackup raadpleegt u de documentatiepagina over hoe u herstelt naar A. Het vereist een eerste stap om de back-up voor te bereiden voordat u de MySQL-gegevensdirectory vervangt.
Zodra A correct is begonnen met repliceren, controleert u de Seconds_Behind_Master in de slave-status. Dit geeft je een idee van hoe ver de slaaf is achtergelaten en hoe lang je moet wachten voordat hij hem inhaalt. Op dit moment ziet onze architectuur er als volgt uit:
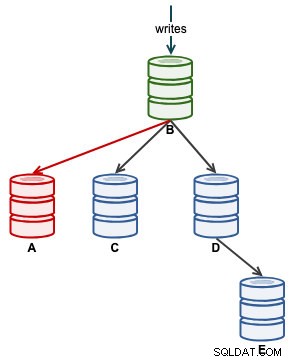
Zodra Seconds_Behind_Master terugvalt naar 0, is dat het moment waarop A de achterstand heeft ingehaald als een up-to-date slaaf.
Als u ClusterControl gebruikt, hebt u de mogelijkheid om het knooppunt opnieuw te synchroniseren door te herstellen vanaf een bestaande back-up of om de back-up rechtstreeks vanaf het actieve hoofdknooppunt te maken en te streamen:
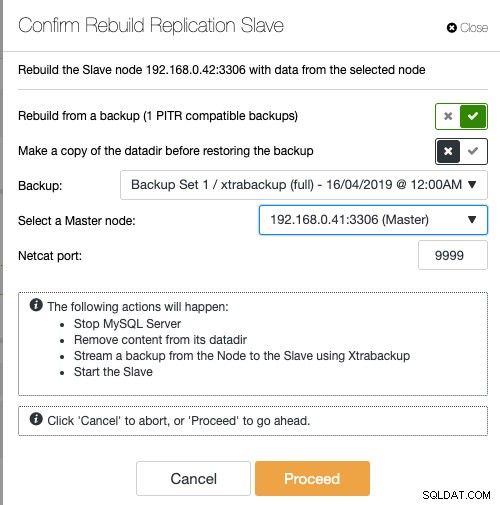
Het klaarzetten van de slaaf met een bestaande back-up is de aanbevolen manier om de slaaf te bouwen, aangezien het geen invloed heeft op de actieve hoofdserver bij het voorbereiden van het knooppunt.
Promoot de oude meester
Voordat A als de nieuwe master wordt gepromoveerd, is de veiligste manier om alle schrijfbewerkingen op B te stoppen. Als dit niet mogelijk is, dwingt u B gewoon om in de alleen-lezen modus te werken:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Voer vervolgens op A SHOW SLAVE STATUS uit en controleer de volgende replicatiestatus:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesDe waarde van Read_Master_Log_Pos en Exec_Master_Log_Pos moet identiek zijn, terwijl Seconds_Behind_Master 0 is en de status 'Slave has read all relay log' moet zijn. Zorg ervoor dat alle slaves alle instructies in hun relaislogboek hebben verwerkt, anders loopt u het risico dat de nieuwe zoekopdrachten transacties uit het relaislogboek beïnvloeden, waardoor allerlei problemen ontstaan (een toepassing kan bijvoorbeeld enkele rijen verwijderen die toegankelijk zijn voor transacties uit relaislog).
Op A, stop de replicatie en gebruik de RESET SLAVE ALL-instructie om alle replicatiegerelateerde configuraties te verwijderen en alleen-lezen uit te schakelen:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';Op dit punt is A klaar om schrijfbewerkingen te accepteren (read_only=OFF), maar slaves zijn er niet op aangesloten, zoals hieronder geïllustreerd:
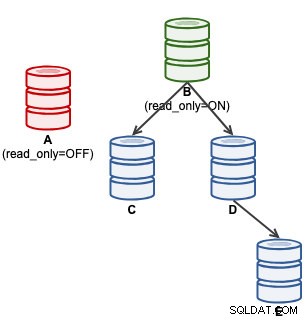
Voor ClusterControl-gebruikers kan het promoten van A worden gedaan door de functie "Slaaf promoten" onder Knooppuntacties te gebruiken. ClusterControl degradeert automatisch de actieve master B, promoveert slaaf A als master en repoint C en D om te repliceren van A. B wordt opzij gezet en de gebruiker moet expliciet "Change Replication Master" kiezen om in een later stadium weer deel te nemen aan B repliceren van A. .
Slaaf opnieuw plaatsen
Het is nu veilig om de master op gerelateerde slaves te wijzigen om te repliceren vanaf A (192.168.0.41). Configureer op alle slaves behalve E het volgende:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Als u een ClusterControl-gebruiker bent, kunt u deze stap overslaan omdat het opnieuw plaatsen automatisch wordt uitgevoerd wanneer u eerder besloot om A te promoten.
We kunnen dan onze applicatie starten om op A te schrijven. Op dit moment ziet onze architectuur er ongeveer zo uit:
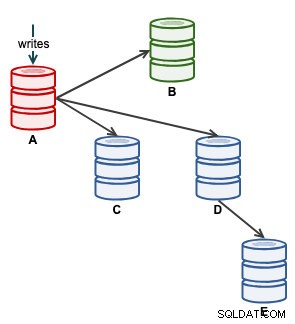
Vanuit de ClusterControl-topologieweergave hebben we ons replicatiecluster hersteld naar de oorspronkelijke architectuur die er als volgt uitziet:
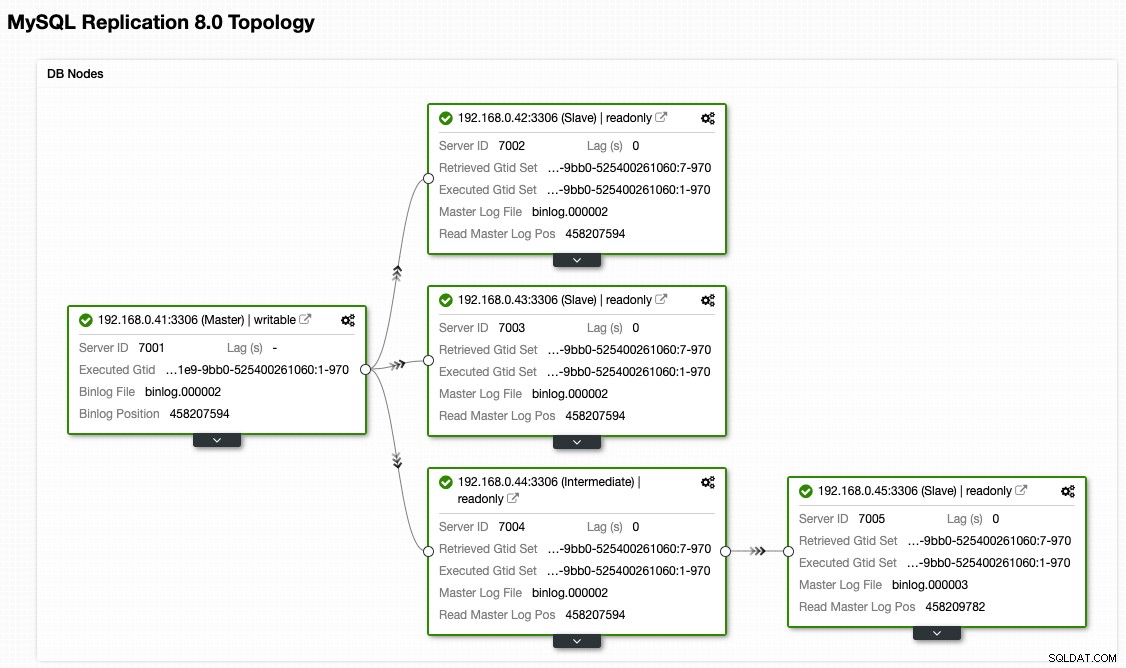
Houd er rekening mee dat failback-oefeningen veel minder riskant zijn in vergelijking met failover. Het is belangrijk om deze oefening tijdens de daluren te plannen om de impact op uw bedrijf te minimaliseren.
Laatste gedachten
Failover- en failback-bewerkingen moeten zorgvuldig worden uitgevoerd. De bewerking is vrij eenvoudig als u een klein aantal knooppunten heeft, maar voor meerdere knooppunten met een complexe replicatieketen kan het een riskante en foutgevoelige oefening zijn. We hebben ook laten zien hoe ClusterControl kan worden gebruikt om complexe bewerkingen te vereenvoudigen door ze uit te voeren via de gebruikersinterface, plus de topologieweergave wordt in realtime gevisualiseerd, zodat u inzicht heeft in de replicatietopologie die u wilt bouwen.