Voor het geval je het nog niet hebt gezien, we hebben zojuist ClusterControl 1.7.5 uitgebracht met belangrijke verbeteringen en nieuwe handige functies. Enkele van de functies zijn Cluster Wide Maintenance, ondersteuning voor versie CentOS 8 en Debian 10, PostgreSQL 12 Support, MongoDB 4.2 en Percona MongoDB v4.0-ondersteuning, evenals het nieuwe MySQL Freeze Frame.
Wacht, maar wat is een MySQL Freeze Frame? Is dit iets nieuws voor MySQL?
Nou, het is niet iets nieuws binnen de MySQL-kernel zelf. Het is een nieuwe functie die we hebben toegevoegd aan ClusterControl 1.7.5 en die specifiek is voor MySQL-databases. Het MySQL Freeze Frame in ClusterControl 1.7.5 zal de volgende zaken behandelen:
- Momentopname MySQL-status vóór clusterfout.
- Snapshot MySQL-proceslijst vóór clusterfout (binnenkort beschikbaar).
- Inspecteer clusterincidenten in operationele rapporten of vanuit de s9s-opdrachtregeltool.
Dit zijn waardevolle sets met informatie die kunnen helpen bij het opsporen van bugs en het repareren van je MySQL/MariaDB-clusters als het mis gaat. In de toekomst zijn we van plan om ook snapshots van de SHOW ENGINE InnoDB-statuswaarden op te nemen. Dus blijf op de hoogte van onze toekomstige releases.
Houd er rekening mee dat deze functie zich nog in de bètafase bevindt. We verwachten meer datasets te verzamelen terwijl we met onze gebruikers werken. In deze blog laten we u zien hoe u deze functie kunt gebruiken, vooral wanneer u meer informatie nodig heeft bij het diagnosticeren van uw MySQL/MariaDB-cluster.
Clustercontrole bij het afhandelen van clusterstoringen
Voor clusterstoringen doet ClusterControl niets tenzij Auto Recovery (Cluster/Node) is ingeschakeld, zoals hieronder:

Eenmaal ingeschakeld, zal ClusterControl proberen een knooppunt te herstellen of het cluster te herstellen door het opbrengen van de gehele clustertopologie.
Voor MySQL, bijvoorbeeld in een master-slave-replicatie, moet er op elk moment ten minste één master actief zijn, ongeacht het aantal beschikbare slave(s). ClusterControl probeert de topologie ten minste één keer te corrigeren voor replicatieclusters, maar biedt meer nieuwe pogingen voor multi-masterreplicatie zoals NDB-cluster en Galera-cluster. Knooppuntherstel probeert een falend databaseknooppunt te herstellen, b.v. wanneer het proces werd stopgezet (abnormale afsluiting), of het proces een OOM (Out-of-Memory) opliep. ClusterControl maakt via SSH verbinding met het knooppunt en probeert MySQL op te roepen. We hebben eerder geblogd over hoe ClusterControl automatisch databaseherstel en failover uitvoert, dus bezoek dat artikel voor meer informatie over het schema voor automatisch ClusterControl-herstel.
In de vorige versie van ClusterControl <1.7.5 veroorzaakten deze herstelpogingen alarmen. Maar wat onze klanten misten, was een completer incidentrapport met statusinformatie net voor de clusterstoring. Totdat we ons dit tekort realiseerden en deze functie in ClusterControl 1.7.5 toevoegden. We noemden het het "MySQL Freeze Frame". Het MySQL Freeze Frame biedt op het moment van schrijven een korte samenvatting van incidenten die hebben geleid tot wijzigingen in de clusterstatus net voor de crash. Het belangrijkste is dat het aan het einde van het rapport de lijst met hosts en hun MySQL Global Status-variabelen en -waarden bevat.
Hoe verschilt MySQL Freeze Frame met automatisch herstel?
Het MySQL Freeze Frame maakt geen deel uit van het automatisch herstel van ClusterControl. Of Auto Recovery nu is uitgeschakeld of ingeschakeld, het MySQL Freeze Frame zal altijd zijn werk doen zolang een cluster- of node-fout is gedetecteerd.
Hoe werkt MySQL Freeze Frame?
In ClusterControl zijn er bepaalde statussen die we classificeren als verschillende typen clusterstatus. MySQL Freeze Frame genereert een incidentrapport wanneer deze twee toestanden worden geactiveerd:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
In ClusterControl is een CLUSTER_DEGRADED wanneer u naar een cluster kunt schrijven, maar een of meer knooppunten zijn niet beschikbaar. Wanneer dit gebeurt, genereert ClusterControl het incidentrapport.
Voor CLUSTER_FAILURE, hoewel de nomenclatuur zichzelf verklaart, is het de toestand waarin je cluster faalt en niet langer lees- of schrijfbewerkingen kan verwerken. Dan is dat een CLUSTER_FAILURE-status. Ongeacht of een automatisch herstelproces probeert het probleem op te lossen of dat het is uitgeschakeld, ClusterControl genereert het incidentrapport.
Hoe schakel je MySQL Freeze Frame in?
ClusterControl's MySQL Freeze Frame is standaard ingeschakeld en genereert alleen een incidentrapport wanneer de toestanden CLUSTER_DEGRADED of CLUSTER_FAILURE worden geactiveerd of aangetroffen. Het is dus niet nodig aan de kant van de gebruiker om een ClusterControl-configuratie-instelling in te stellen, ClusterControl doet het automatisch voor u.
Het MySQL Freeze Frame-incidentrapport vinden
Op het moment van schrijven zijn er vier manieren om het incidentrapport te vinden. Deze kunnen worden gevonden door de volgende secties hieronder te doen.
Het tabblad Operationele rapporten gebruiken
De operationele rapporten van de vorige versies worden alleen gebruikt om de operationele rapporten die door gebruikers zijn gegenereerd, te maken, te plannen of weer te geven. Sinds versie 1.7.5 hebben we het incidentrapport opgenomen dat is gegenereerd door onze MySQL Freeze Frame-functie. Zie onderstaand voorbeeld:
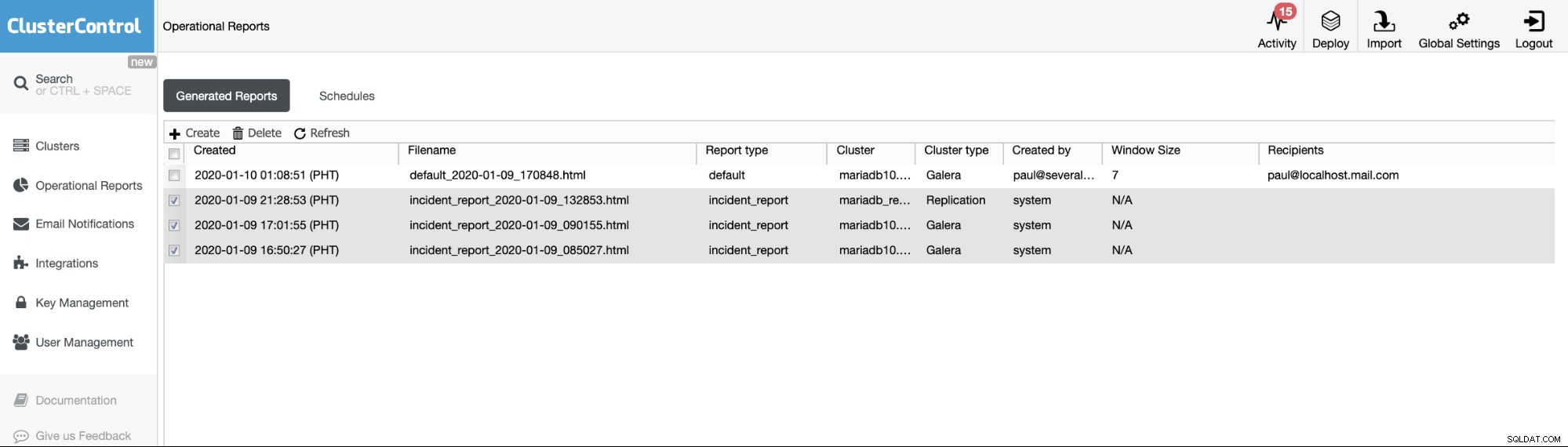
De aangevinkte items of items met Rapporttype ==incident_report, zijn het incident rapporten gegenereerd door de MySQL Freeze Frame-functie in ClusterControl.
Foutrapporten gebruiken
Door het cluster te selecteren en een foutenrapport te genereren, d.w.z. door dit proces te gaan:
S9s CLI-opdrachtregel gebruiken
In een gegenereerd incidentrapport staan instructies of hints over hoe je dit kunt gebruiken met het s9s CLI-commando. Hieronder ziet u wat er in het incidentrapport wordt weergegeven:
Tip! Door de s9s CLI-tool te gebruiken, kunt u gemakkelijk gegevens in dit rapport opnemen, bijvoorbeeld:
s9s report --list --long
s9s report --cat --report-id=NDus als u een foutenrapport wilt lokaliseren en genereren, kunt u deze aanpak gebruiken:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportAls ik de wsrep_*-variabelen op een specifieke host wil grep, kan ik het volgende doen:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Handmatig lokaliseren via systeembestandspad
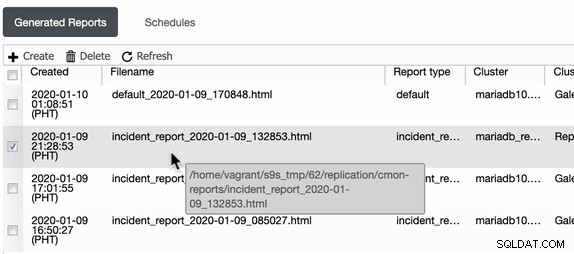
ClusterControl genereert deze incidentrapporten in de host waarop ClusterControl wordt uitgevoerd. ClusterControl maakt een map aan in /home/
Zijn er gevaren of waarschuwingen bij het gebruik van MySQL Freeze Frame?
ClusterControl verandert of wijzigt niets in uw MySQL-knooppunten of cluster. MySQL Freeze Frame leest alleen SHOW GLOBAL STATUS (vanaf deze tijd) met specifieke tussenpozen om records op te slaan, aangezien we de status van een MySQL-knooppunt of cluster niet kunnen voorspellen wanneer het kan crashen of wanneer het hardware- of schijfproblemen kan hebben. Het is niet mogelijk om dit te voorspellen, dus we slaan de waarden op en daarom kunnen we een incidentrapport genereren als een bepaald knooppunt uitvalt. In dat geval is het gevaar om dit te hebben bijna nul. Het kan in theorie een reeks clientverzoeken aan de server(s) toevoegen voor het geval er enkele vergrendelingen binnen MySQL worden vastgehouden, maar we hebben het nog niet opgemerkt. De reeks tests toont dit niet aan, dus we zouden blij zijn als u ons weten of een ondersteuningsticket indienen voor het geval er zich problemen voordoen.
Er zijn bepaalde situaties waarin een incidentrapport mogelijk geen globale statusvariabelen kan verzamelen als een netwerkprobleem het probleem was voordat ClusterControl een specifiek frame bevroor om gegevens te verzamelen. Dat is volkomen redelijk, want ClusterControl kan op geen enkele manier gegevens verzamelen voor verdere diagnose, aangezien er in de eerste plaats geen verbinding met het knooppunt is.
Ten slotte vraagt u zich misschien af waarom niet alle variabelen worden weergegeven in de sectie GLOBAL STATUS? Voor de tussentijd hebben we een filter ingesteld waarbij lege of 0-waarden worden uitgesloten in het incidentrapport. De reden is dat we wat schijfruimte willen besparen. Zodra deze incidentrapporten niet langer nodig zijn, kunt u deze verwijderen via het tabblad Operationele rapporten.
De MySQL Freeze Frame-functie testen
We geloven dat je deze graag wilt proberen en zien hoe het werkt. Maar zorg er alstublieft voor dat u dit niet uitvoert of test in een live- of productieomgeving. We behandelen twee scenario's in de MySQL/MariaDB, één voor master-slave-installatie en één voor installatie van het Galera-type.
Master-Slave-configuratietestscenario
In een master-slave(s)-opstelling is het gemakkelijk en eenvoudig om te proberen.
Stap één
Zorg ervoor dat u de Auto Recovery-modi (Cluster en Node) hebt uitgeschakeld, zoals hieronder:

dus het zal niet proberen of proberen het testscenario te repareren.
Stap twee
Ga naar je hoofdknooppunt en probeer alleen-lezen in te stellen:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Stap drie
Deze keer werd er alarm geslagen en dus een incidentrapport gegenereerd. Zie hieronder hoe mijn cluster eruit ziet:

en het alarm is geactiveerd:

en het incidentrapport is gegenereerd:

Galera-clusterconfiguratietestscenario
Voor op Galera gebaseerde installatie moeten we ervoor zorgen dat het cluster niet langer beschikbaar is, d.w.z. een clusterbrede storing. In tegenstelling tot de Master-Slave-test, kun je Auto Recovery ingeschakeld laten, omdat we zullen spelen met netwerkinterfaces.
Opmerking:Zorg ervoor dat u bij deze installatie meerdere interfaces hebt als u de knooppunten in een externe instantie test, aangezien u de interface niet omhoog kunt brengen als u de interface omlaag brengt waarmee u verbonden bent.
Stap één
Maak een Galera-cluster met 3 knooppunten (bijvoorbeeld met zwerver)
Stap twee
Geef de opdracht (zoals hieronder) om een netwerkprobleem te simuleren en doe dit voor alle knooppunten
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Stap drie
Mijn cluster is nu uitgeschakeld en heeft deze status:

heeft alarm geslagen,

en het genereert een incidentrapport:

Voor een voorbeeld van een incidentrapport kunt u dit onbewerkte bestand gebruiken en opslaan als html.
Het is vrij eenvoudig om te proberen, maar nogmaals, doe dit alstublieft alleen in een niet-live en niet-prodomgeving.
Conclusie
MySQL Freeze Frame in ClusterControl kan handig zijn bij het diagnosticeren van crashes. Bij het oplossen van problemen heb je een schat aan informatie nodig om de oorzaak te achterhalen en dat is precies wat MySQL Freeze Frame biedt.