Omdat hoge beschikbaarheid van het grootste belang is in de zakelijke realiteit van vandaag, is een van de meest voorkomende scenario's voor gebruikers hoe ze ervoor kunnen zorgen dat de database altijd beschikbaar is voor de applicatie.
Elke serviceprovider heeft een overgeërfd risico op serviceonderbreking, daarom is een van de stappen die genomen kunnen worden om op meerdere providers te vertrouwen om het risico en extra redundantie te verminderen.
Cloudserviceproviders zijn niet anders - ze kunnen falen en u moet dit van tevoren plannen. Welke opties zijn beschikbaar voor MariaDB Cluster? Laten we er eens naar kijken in deze blogpost.
MariaDB-databaseclustering in multi-cloudomgevingen
Als de door één cloudserviceprovider voorgestelde SLA niet voldoende is, is er altijd een optie om een rampherstelsite buiten die provider te maken. Hierdoor kunt u, wanneer een van de cloudproviders enige verslechtering van de service ervaart, altijd overstappen naar een andere provider en uw database up-and-beschikbaar houden.
Een van de problemen die typisch zijn voor multi-cloudopstellingen is de netwerklatentie die onvermijdelijk is als we het hebben over grotere afstanden of, in het algemeen, meerdere geografisch gescheiden locaties. De lichtsnelheid is vrij hoog, maar het is eindig, elke hop, elke router voegt ook wat latency toe aan de netwerkinfrastructuur.
MariaDB Cluster werkt uitstekend op netwerken met lage latentie. Het is een op het quorum gebaseerd cluster waar snelle communicatie tussen alle knooppunten vereist is om de operaties soepel te laten verlopen. Een toename van de netwerklatentie heeft invloed op de clusterbewerkingen, met name de prestaties van de schrijfbewerkingen. Er zijn verschillende manieren waarop dit probleem kan worden aangepakt.
Eerst hebben we een optie om afzonderlijke clusters te gebruiken die zijn verbonden met behulp van asynchrone replicatiekoppelingen. Hierdoor kunnen we latentie bijna vergeten, omdat asynchrone replicatie aanzienlijk beter geschikt is om te werken in omgevingen met hoge latentie.
Een andere optie is dat, gezien netwerken met lage latentie tussen datacenters, het nog steeds prima kan zijn om een MariaDB-cluster uit te voeren die zich over meerdere datacenters uitstrekt. Meerdere datacenters betekenen immers niet altijd grote geografische afstanden - u kunt net zo goed gebruik maken van meerdere providers in hetzelfde grootstedelijk gebied, verbonden met snelle netwerken met lage latentie. Dan hebben we het over latentietoename tot maximaal tientallen milliseconden, zeker niet honderden. Het hangt allemaal af van de toepassing, maar een dergelijke verhoging kan acceptabel zijn.
Asynchrone replicatie tussen MariaDB-clusters
Laten we even kijken naar de asynchrone benadering. Het idee is eenvoudig:twee clusters die met elkaar zijn verbonden door middel van asynchrone replicatie.
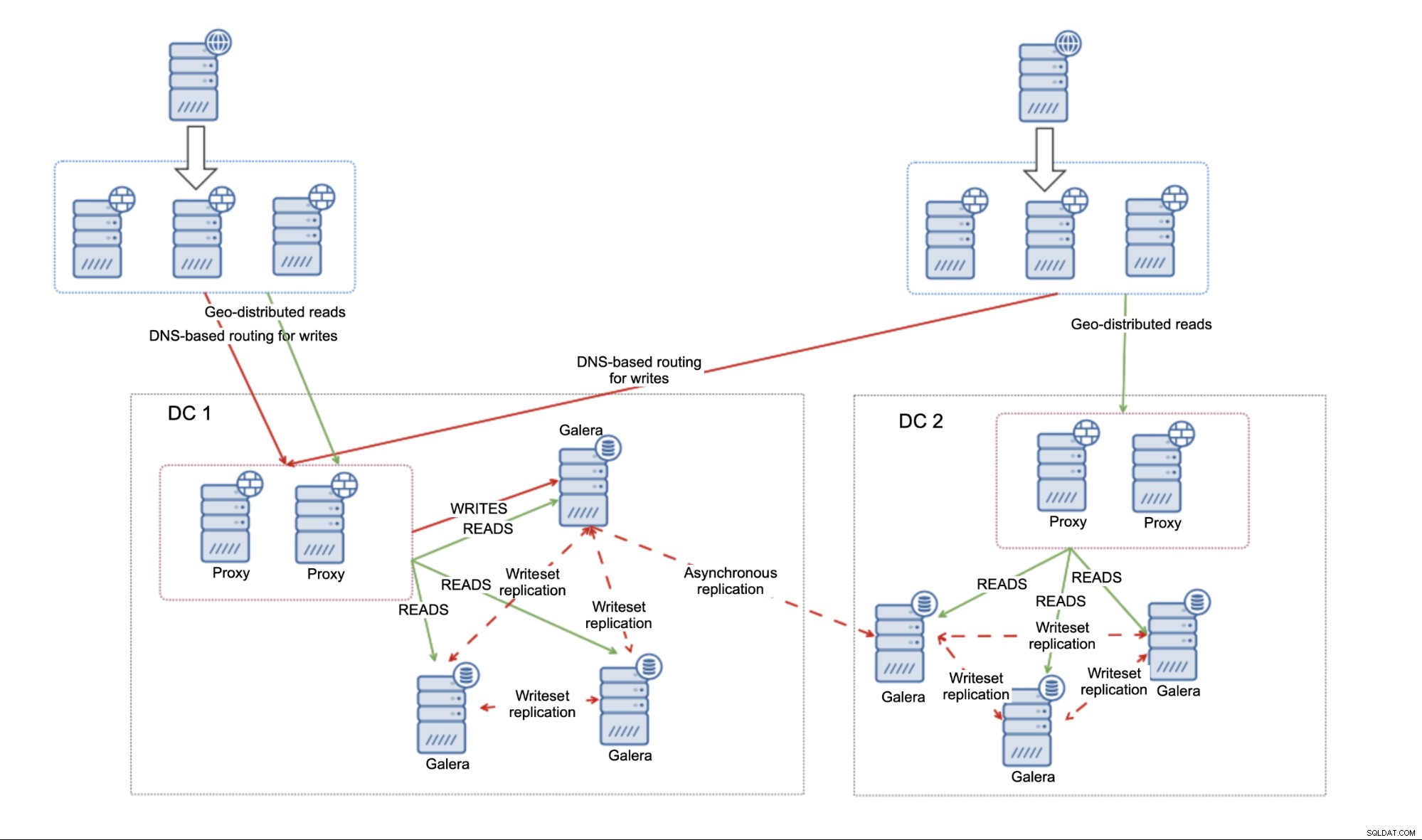
Dit heeft verschillende beperkingen. Om te beginnen moet u beslissen of u multi-master wilt gebruiken of dat u al het verkeer naar slechts één datacenter wilt sturen. We raden aan om niet naar beide datacenters te schrijven en master-master-replicatie te gebruiken. Dit kan tot ernstige problemen leiden als u niet voorzichtig bent.
Als u besluit om de actieve - passieve setup te gebruiken, wilt u waarschijnlijk een soort van DNS-gebaseerde routering voor schrijfbewerkingen implementeren, om ervoor te zorgen dat uw applicatieservers altijd verbinding maken met een set van proxy's die zich in het actieve datacenter bevinden. Dit kan worden bereikt door ofwel letterlijk DNS-invoer die zou worden gewijzigd wanneer failover vereist is, of het kan worden gedaan via een soort service-ontdekkingsoplossing zoals Consul of etcd.
Het belangrijkste nadeel van de omgeving die is gebouwd met behulp van de asynchrone replicatie is het gebrek aan vermogen om netwerksplitsingen tussen datacenters op te lossen. Dit wordt geërfd van de replicatie - ongeacht wat u met de replicatie wilt koppelen (enkele knooppunten, MariaDB-clusters), er is geen manier om het feit te omzeilen dat replicatie niet quorumbewust is. Er is geen mechanisme om de status van de knooppunten te volgen en het beeld op hoog niveau van de hele topologie te begrijpen. Als gevolg hiervan, wanneer de koppeling tussen twee datacenters uitvalt, krijg je twee afzonderlijke MariaDB-clusters die niet zijn verbonden en die beide klaar zijn om verkeer te accepteren. Het is aan de gebruiker om te bepalen wat hij in een dergelijk geval moet doen. Het is mogelijk om aanvullende tools te implementeren die de toestand van de databases van buitenaf (d.w.z. vanuit het derde datacenter) monitoren en vervolgens acties ondernemen (of geen acties ondernemen) op basis van die informatie. Het is ook mogelijk om tools samen te brengen die de infrastructuur delen met databases, maar die clusterbewust zijn en de status van de datacenterconnectiviteit kunnen volgen en kunnen worden gebruikt als de bron van waarheid voor de scripts die de omgeving zouden beheren. ClusterControl kan bijvoorbeeld worden geïmplementeerd in een cluster met drie knooppunten, knooppunt per datacenter, dat het RAFT-protocol gebruikt om het quorum te waarborgen. Als een knooppunt de verbinding met de rest van het cluster verliest, kan worden aangenomen dat het datacenter netwerkpartitionering heeft ondergaan.
Multi-DC MariaDB-clusters
Als alternatief voor de asynchrone replicatie zou een volledig MariaDB Cluster-oplossing kunnen zijn die zich over meerdere datacenters uitstrekt.
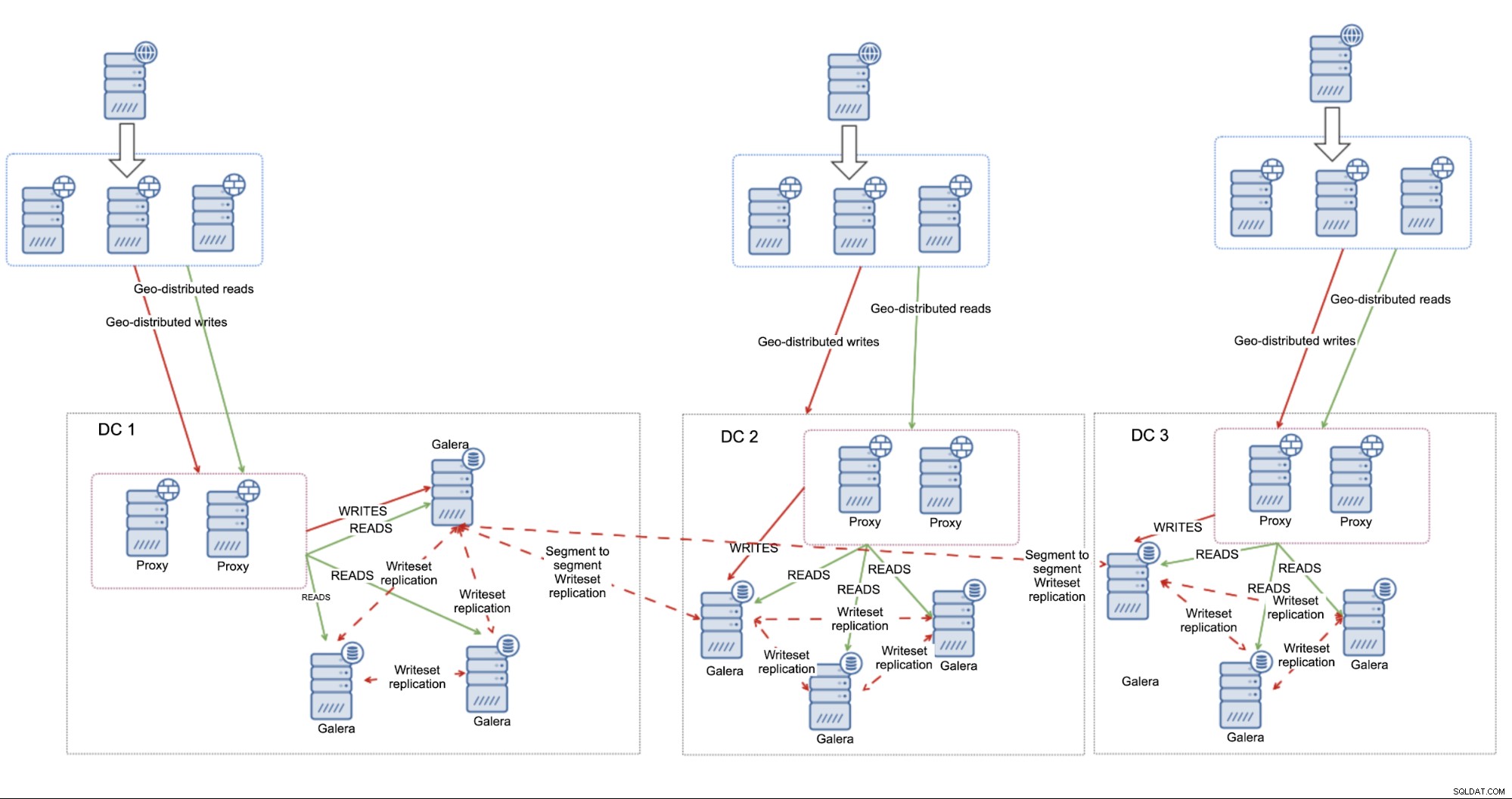
Zoals vermeld aan het begin van deze blog, MariaDB Cluster, net als elke Op Galera gebaseerde cluster, zal worden beïnvloed door de hoge latentie. Dat gezegd hebbende, is het volkomen acceptabel om het in "niet-zo-hoge" latentie-omgevingen uit te voeren en te verwachten dat het zich goed gedraagt en acceptabele prestaties levert. Het hangt allemaal af van de netwerkdoorvoer en het ontwerp, de afstand tussen datacenters en de applicatievereisten. Zo'n aanpak werkt geweldig, vooral als we segmenten gebruiken om afzonderlijke datacenters te onderscheiden. Het stelt MariaDB Cluster in staat om zijn intra-clusterconnectiviteit te optimaliseren en cross-DC-verkeer tot een minimum te beperken.
Het belangrijkste voordeel van deze installatie is dat deze afhankelijk is van MariaDB Cluster om fouten af te handelen. Als u drie datacenters gebruikt, bent u vrijwel gedekt tegen de split-brain-situatie - zolang er een meerderheid is, blijft deze werken. Het is niet vereist om een volwaardig knooppunt in het derde datacenter te hebben - je kunt net zo goed Galera Arbitrator gebruiken, een daemon die als onderdeel van het cluster fungeert, maar die geen databasebewerkingen hoeft af te handelen. Het maakt verbinding met de knooppunten, neemt deel aan de quorumberekening en kan worden gebruikt om het verkeer door te sturen als de directe verbinding tussen de twee datacenters niet werkt.
In dat geval kan het hele failoverproces als volgt worden beschreven:definieer alle knooppunten in de load balancers (allemaal als datacenters dicht bij elkaar liggen, in andere gevallen wilt u misschien wat prioriteit toevoegen aan de knooppunten die zich dichter bij de load balancer bevinden) en dat is het zo'n beetje. MariaDB Cluster-knooppunten die de meerderheid vormen, zijn bereikbaar via elke proxy.
Een multi-cloud MariaDB-cluster implementeren met ClusterControl
Laten we eens kijken naar twee opties die u kunt gebruiken om multi-cloud MariaDB-clusters te implementeren met ClusterControl. Houd er rekening mee dat ClusterControl SSH-connectiviteit vereist voor alle knooppunten die het zal beheren, dus het is aan jou om te zorgen voor netwerkconnectiviteit tussen meerdere datacenters of cloudproviders. Zolang de connectiviteit er is, kunnen we op twee manieren doorgaan.
MariaDB-clusters implementeren met asynchrone replicatie
ClusterControl kan u helpen bij het implementeren van twee clusters die zijn verbonden met behulp van asynchrone replicatie. Wanneer u één MariaDB-cluster hebt geïmplementeerd, wilt u ervoor zorgen dat een van de knooppunten binaire logboeken heeft ingeschakeld. Hierdoor kun je dat knooppunt gebruiken als een master voor het tweede cluster dat we binnenkort zullen maken.
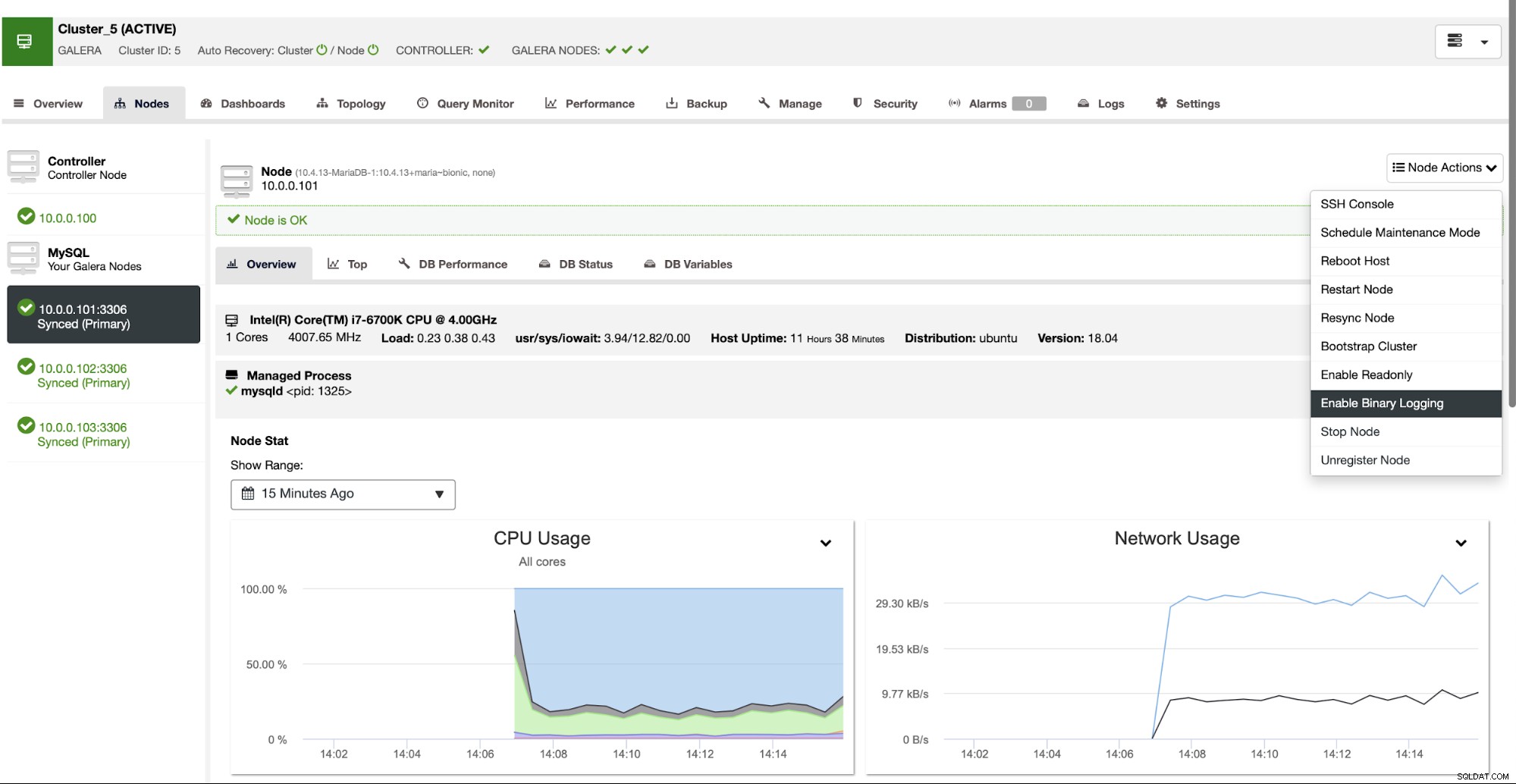
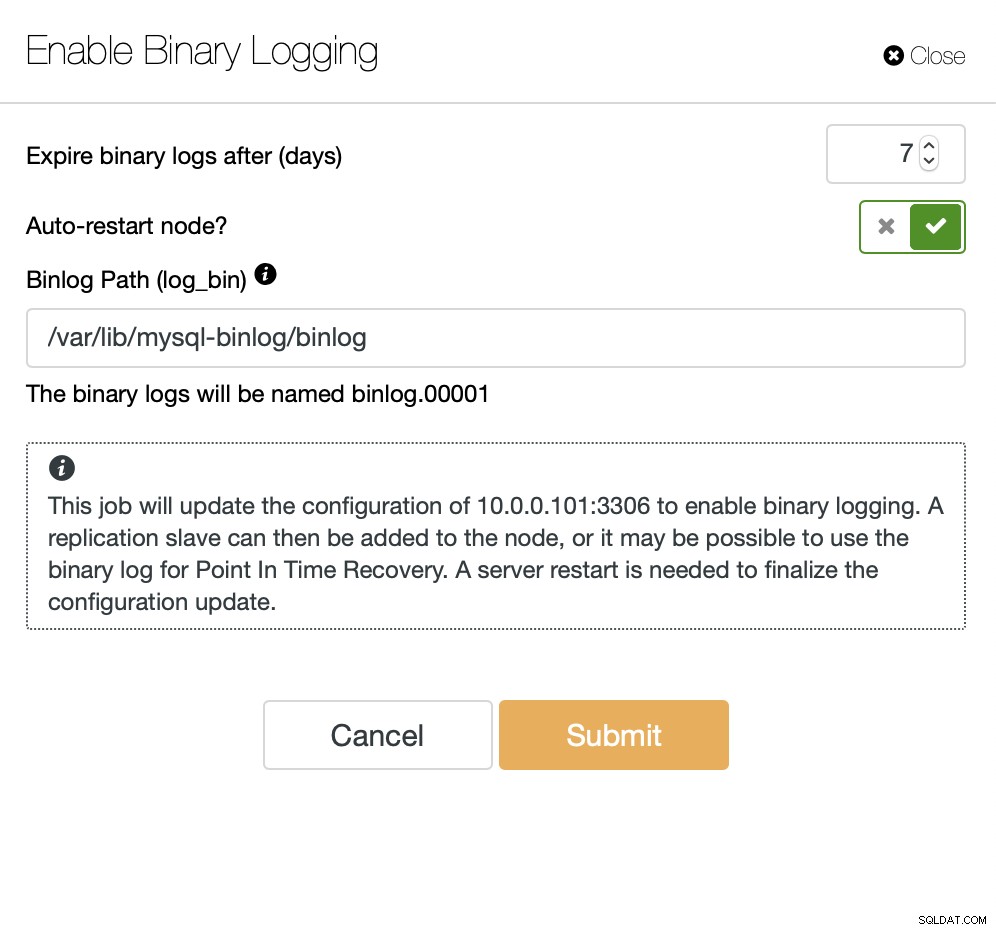
Zodra het binaire logboek is ingeschakeld, kunnen we de taak Create Slave Cluster gebruiken om de implementatiewizard te starten.
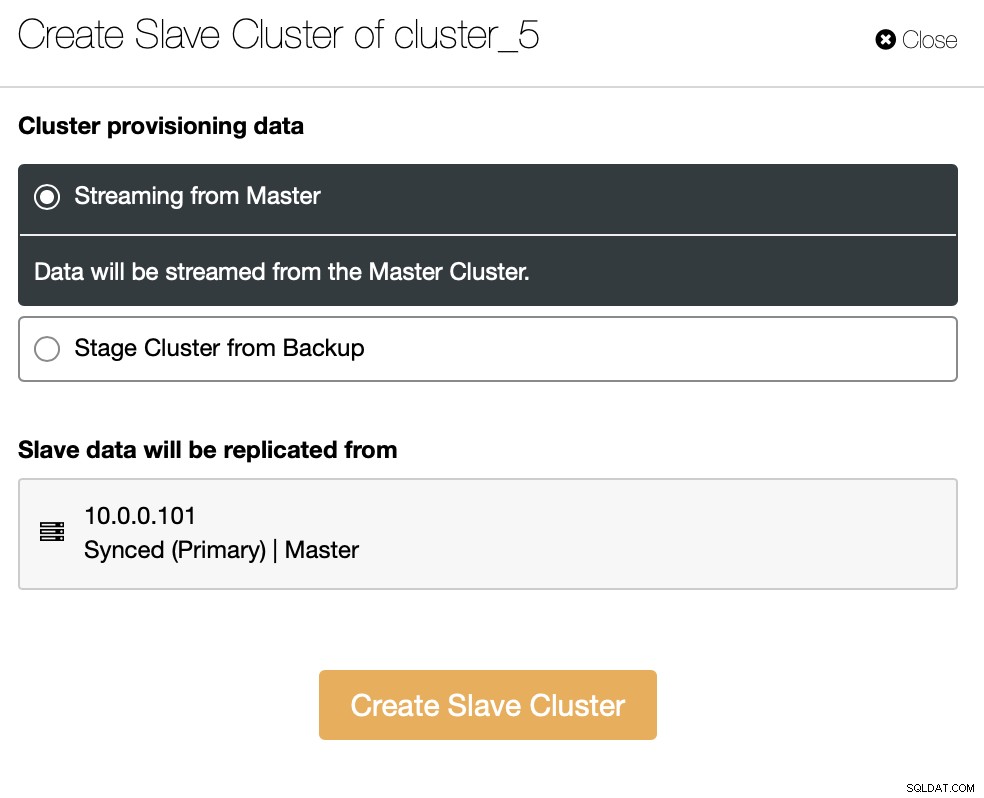
We kunnen de gegevens rechtstreeks van de master streamen of u kunt er een gebruiken van de back-ups om de gegevens te verstrekken.
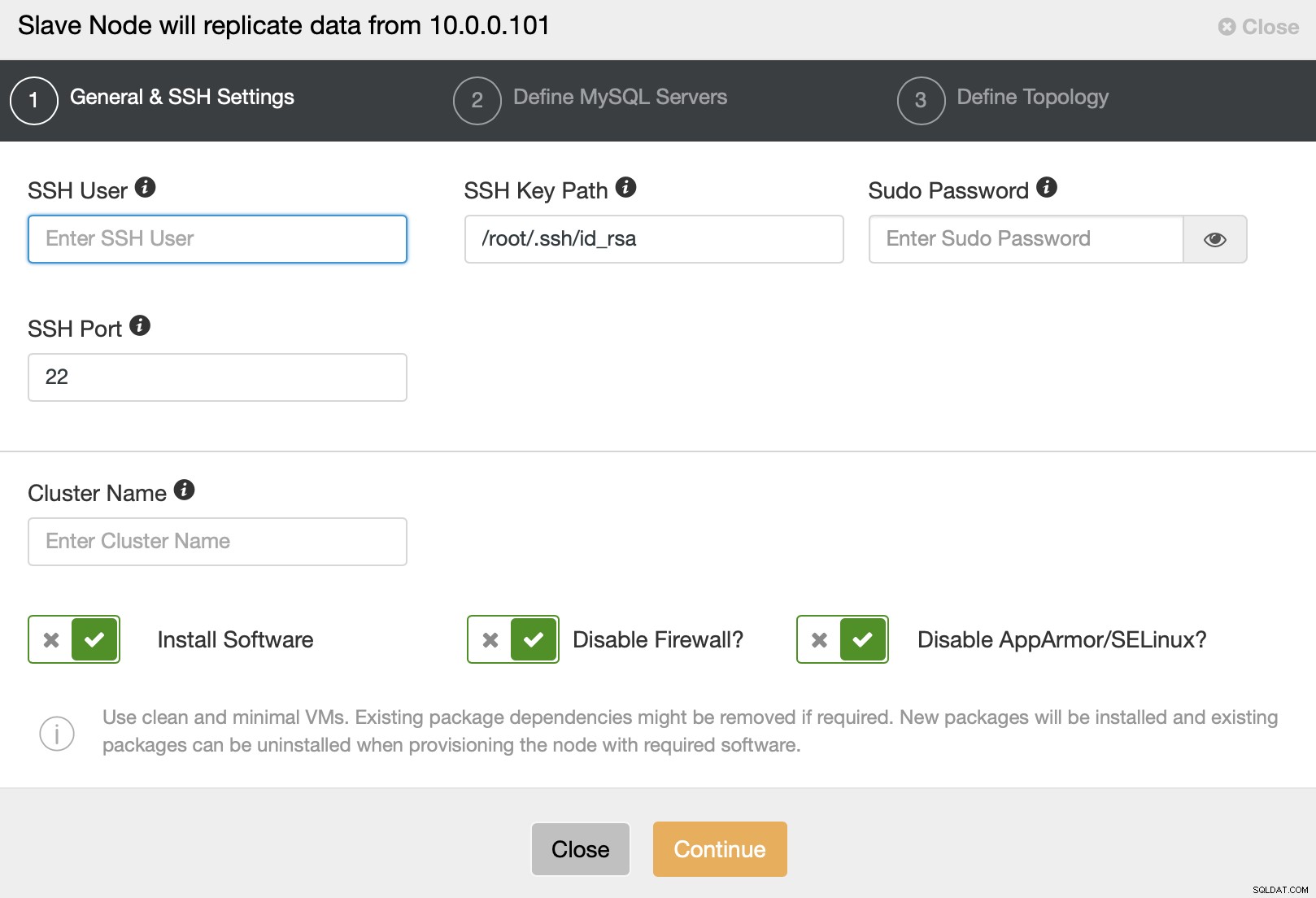
Vervolgens krijgt u een standaard wizard voor clusterimplementatie te zien waar u moet slagen SSH-verbindingsdetails.
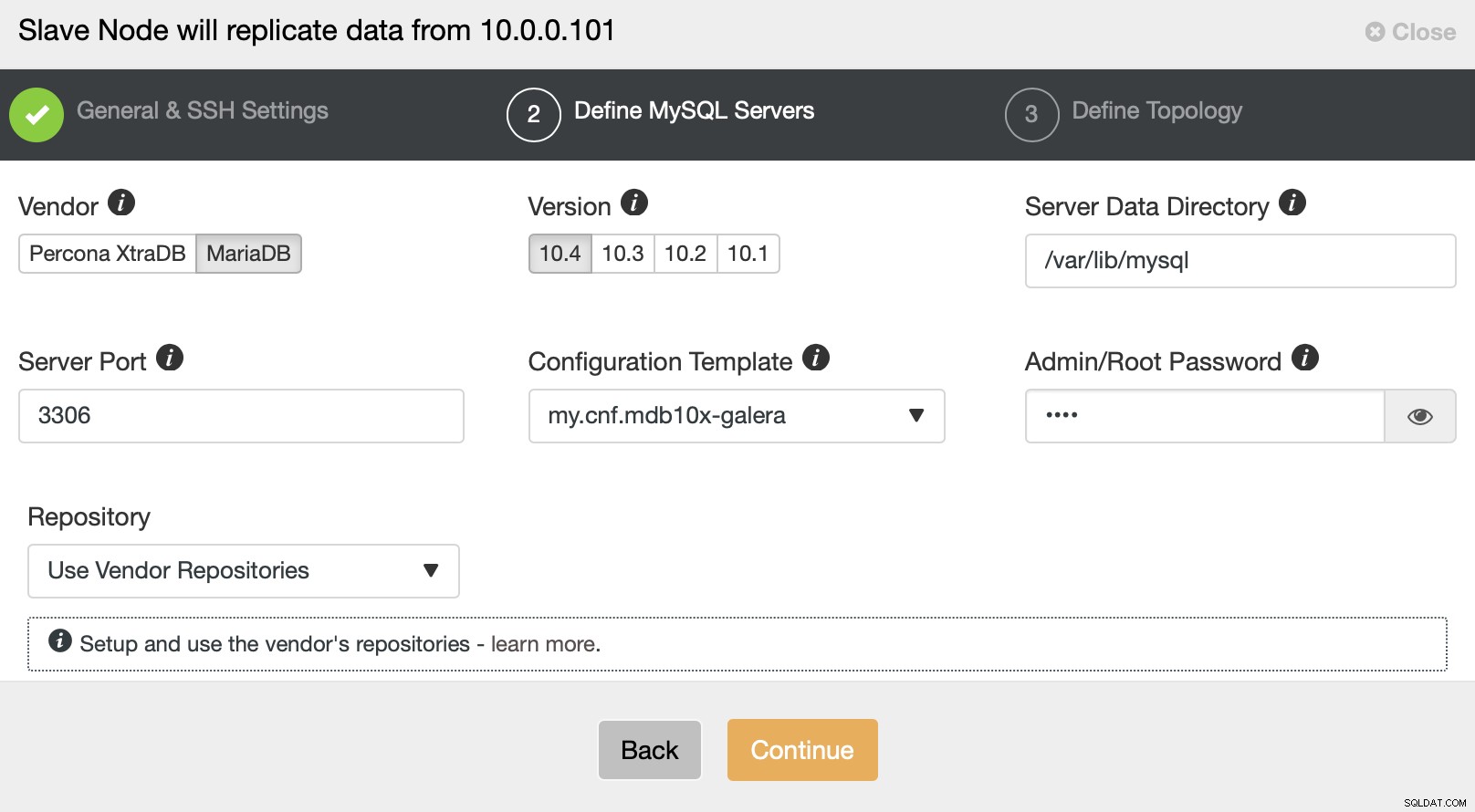
U wordt ook gevraagd om de leverancier en versie van de databases te kiezen zoals gevraagd om het wachtwoord voor de root-gebruiker.
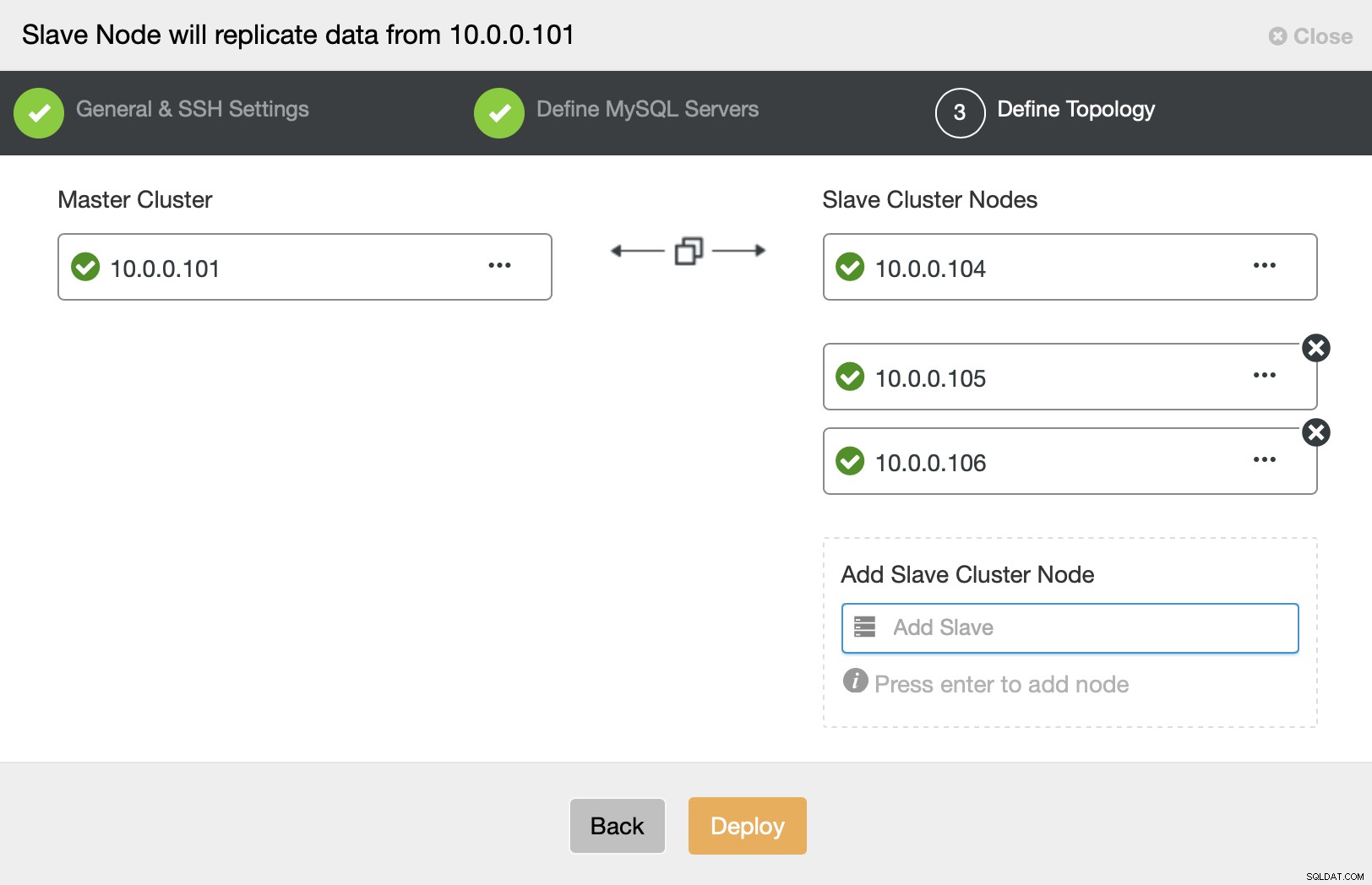
Ten slotte wordt u gevraagd om knooppunten te definiëren die u aan de cluster en je bent helemaal klaar.
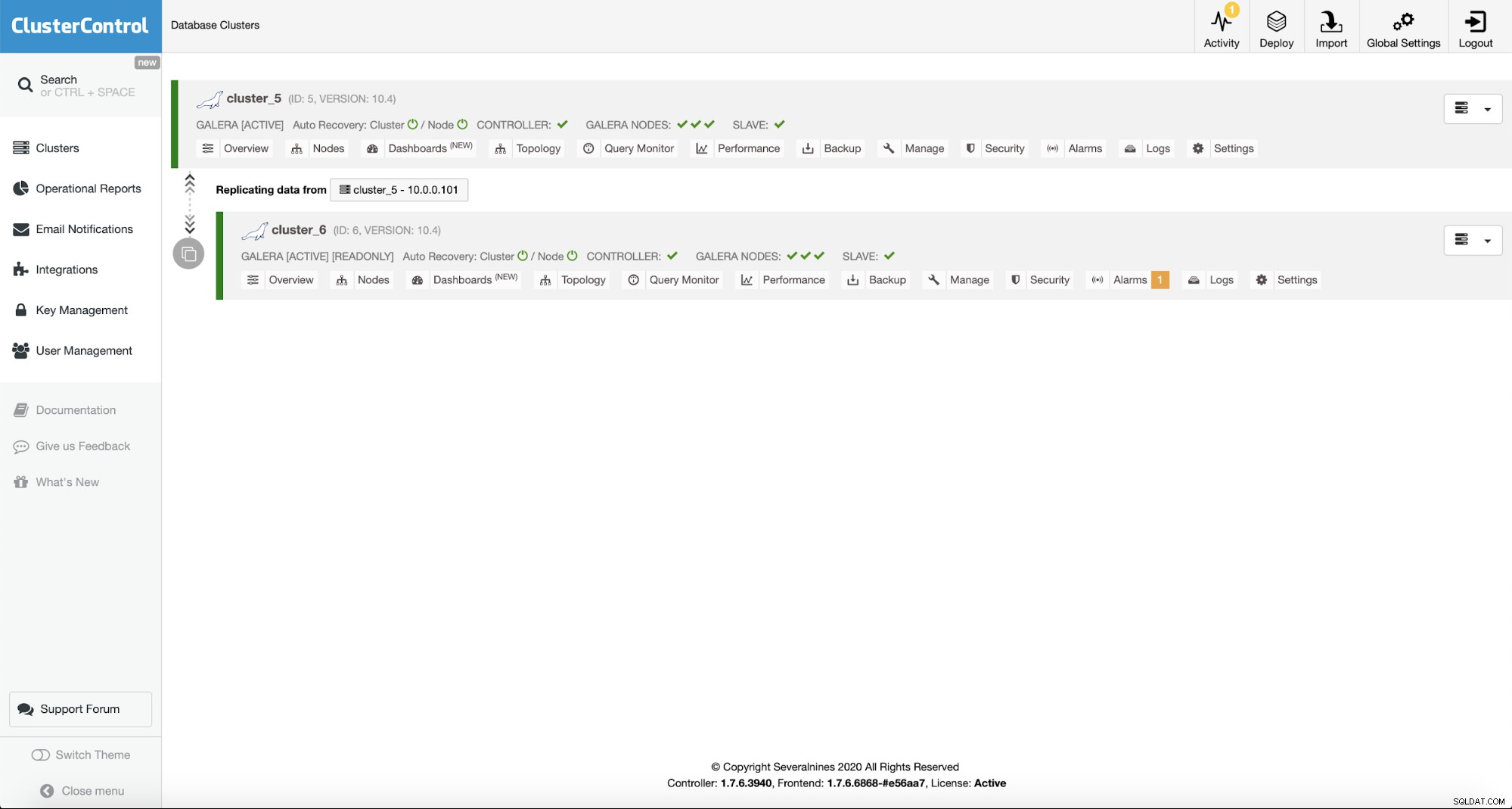
Als het is geïmplementeerd, ziet u het in de lijst met clusters in de ClusterControl-gebruikersinterface.
Multi-Cloud MariaDB-cluster implementeren
Zoals we eerder vermeldden, is een andere optie om MariaDB Cluster in te zetten het gebruik van afzonderlijke segmenten bij het toevoegen van knooppunten aan het cluster. In de gebruikersinterface van ClusterControl vindt u een optie om "Node toevoegen":
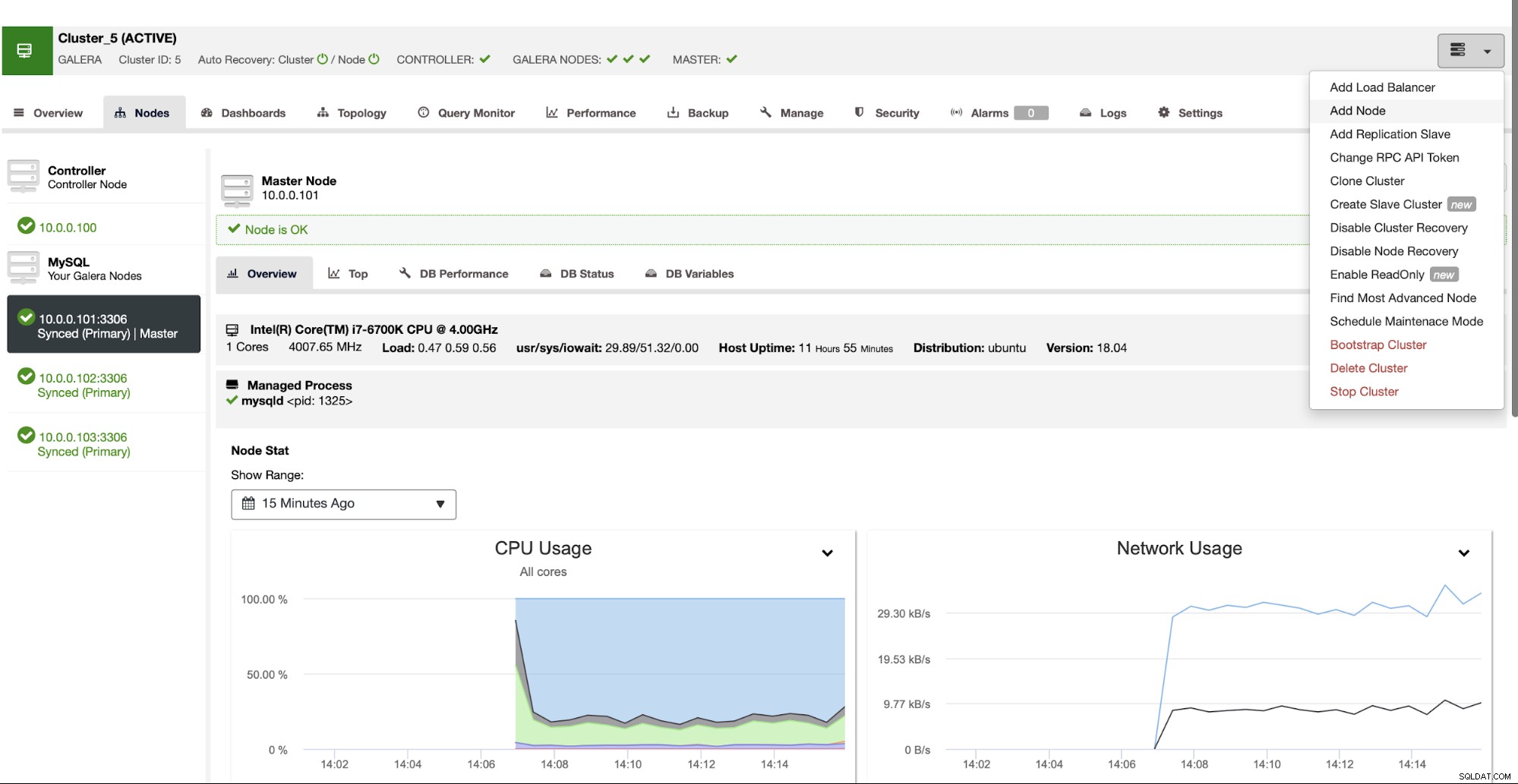
Als je het gebruikt, krijg je het volgende scherm te zien:
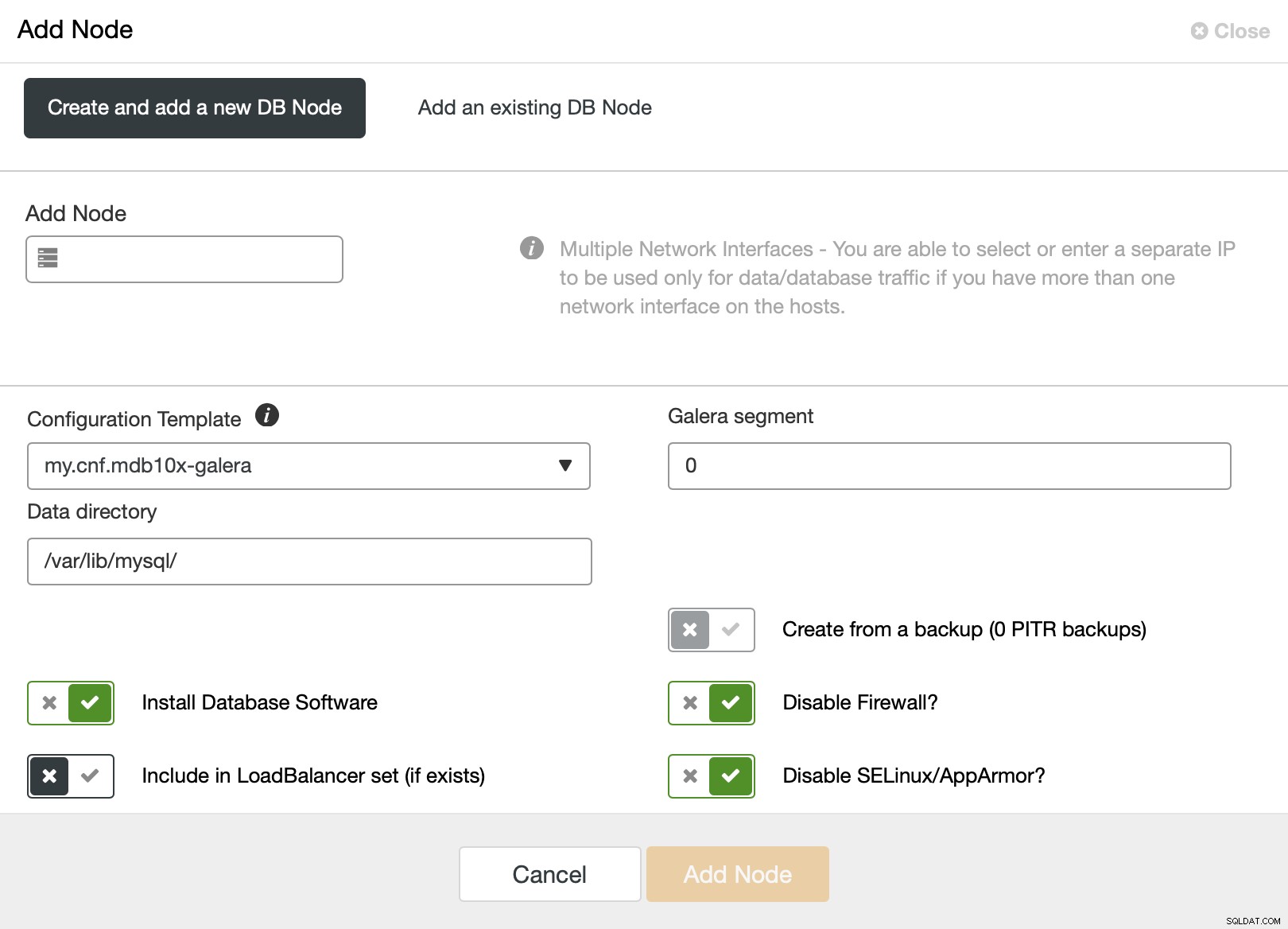
Het standaardsegment is 0, dus u wilt het naar een andere waarde wijzigen .
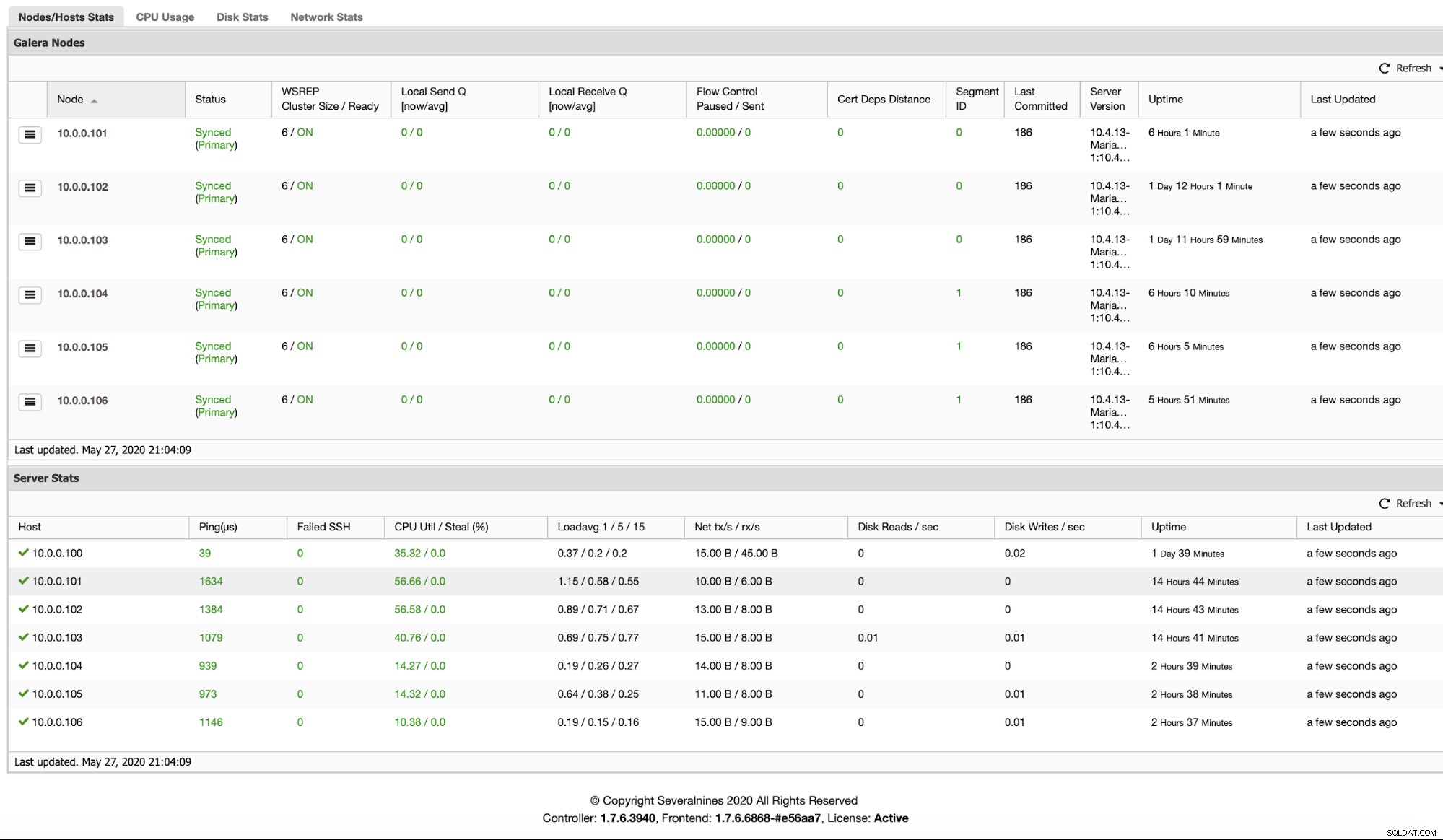
Nadat knooppunten zijn toegevoegd, kunt u controleren in welk segment ze zich bevinden door naar het tabblad Overzicht te kijken:
Conclusie
We hopen dat deze korte blog je een beter begrip heeft gegeven van de opties die je hebt voor multi-cloud MariaDB Cluster-implementaties en hoe deze kunnen worden gebruikt om een hoge beschikbaarheid van je database-infrastructuur te garanderen.