Een single point of failure (SPOF) is een veelvoorkomende reden waarom organisaties ernaar streven de aanwezigheid van hun database-omgevingen geografisch naar een andere locatie te verspreiden. Het maakt deel uit van de strategische plannen voor noodherstel en bedrijfscontinuïteit.
Disaster Recovery (DR)-planning omvat technische procedures die betrekking hebben op de voorbereiding op onverwachte problemen zoals natuurrampen, ongevallen (zoals menselijke fouten) of incidenten (zoals criminele handelingen).
De afgelopen tien jaar was het distribueren van uw database-omgeving over meerdere geografische locaties een vrij gebruikelijke opzet, aangezien openbare clouds veel manieren bieden om hiermee om te gaan. De uitdaging zit hem in het opzetten van database-omgevingen. Het zorgt voor uitdagingen wanneer u de database(s) probeert te beheren, uw gegevens naar een andere geolocatie verplaatst of beveiliging toepast met een hoge mate van waarneembaarheid.
In deze blog laten we zien hoe u dit kunt doen met MySQL-replicatie. We bespreken hoe u uw gegevens kunt kopiëren naar een ander databaseknooppunt in een ander land dat ver verwijderd is van de huidige geografie van het MySQL-cluster. Voor dit voorbeeld is onze doelregio gebaseerd op us-oost, terwijl mijn locatie in Azië in de Filippijnen is.
Waarom heb ik een databasecluster met geografische locaties nodig?
Zelfs Amazon AWS, de grootste openbare cloudprovider, beweert dat ze last hebben van downtime of onbedoelde storingen (zoals die in 2017). Stel dat u AWS gebruikt als uw secundaire datacenter, naast uw on-premises. U heeft geen interne toegang tot de onderliggende hardware of tot de interne netwerken die uw rekenknooppunten beheren. Dit zijn volledig beheerde services waarvoor u hebt betaald, maar u kunt er niet omheen dat er op elk moment een storing kan optreden. Als een dergelijke geografische locatie een storing heeft, kunt u een lange downtime hebben.
Dit soort problemen moet worden voorzien tijdens uw bedrijfscontinuïteitsplanning. Het moet zijn geanalyseerd en geïmplementeerd op basis van wat is gedefinieerd. Bedrijfscontinuïteit voor uw MySQL-databases moet een hoge uptime omvatten. Sommige omgevingen doen benchmarks en leggen een hoge lat voor rigoureuze tests, inclusief de zwakke kant, om eventuele kwetsbaarheden bloot te leggen, hoe veerkrachtig deze kan zijn en hoe schaalbaar uw technologie-architectuur, inclusief uw database-infrastructuur. Voor bedrijven, met name die met hoge transacties, is het absoluut noodzakelijk ervoor te zorgen dat productiedatabases altijd beschikbaar zijn voor de applicaties, zelfs wanneer zich een ramp voordoet. Anders kan er downtime optreden en kan het u veel geld kosten.
Met deze geïdentificeerde scenario's beginnen organisaties hun infrastructuur uit te breiden naar verschillende cloudproviders en knooppunten naar verschillende geolocaties te plaatsen voor een hogere uptime (indien mogelijk bij 99,999999999999), een lagere RPO en geen SPOF.
Om ervoor te zorgen dat productiedatabases een ramp overleven, moet een Disaster Recovery (DR)-site worden geconfigureerd. Productie- en DR-locaties moeten deel uitmaken van twee geografisch ver van elkaar verwijderde datacenters. Dit betekent dat er op de DR-locatie voor elke productiedatabase een standby-database moet worden geconfigureerd, zodat de gegevenswijzigingen die in de productiedatabase plaatsvinden onmiddellijk worden gesynchroniseerd met de standby-database via transactielogboeken. Sommige opstellingen gebruiken hun DR-knooppunten ook om leesbewerkingen af te handelen, zodat de taakverdeling tussen de toepassing en de gegevenslaag mogelijk is.
De gewenste architecturale opstelling
In deze blog is de gewenste setup eenvoudig en toch heel gebruikelijk tegenwoordig. Zie hieronder de gewenste bouwkundige opstelling voor deze blog:
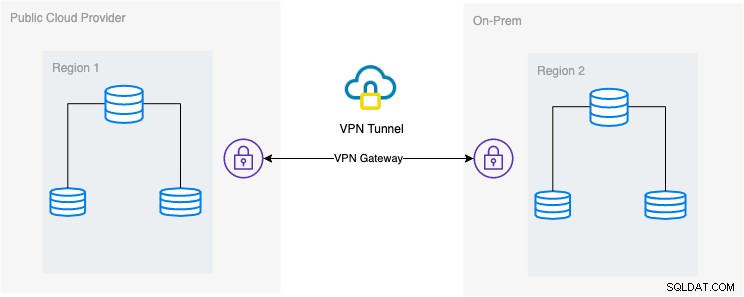
In deze blog kies ik Google Cloud Platform (GCP) als openbare cloudprovider en gebruik mijn lokale netwerk als mijn lokale databaseomgeving.
Het is een must dat wanneer je dit type ontwerp gebruikt, je altijd zowel de omgeving als het platform nodig hebt om op een zeer veilige manier te communiceren. VPN gebruiken of alternatieven zoals AWS Direct Connect gebruiken. Al bieden deze public clouds tegenwoordig managed VPN-diensten aan waar je gebruik van kunt maken. Maar voor deze configuratie gebruiken we OpenVPN omdat ik geen geavanceerde hardware of service nodig heb voor deze blog.
Beste en meest efficiënte manier
Voor MySQL/Percona/MariaDB-databaseomgevingen is de beste en efficiënte manier om een back-up van uw database te maken, naar het doelknooppunt te sturen om te worden geïmplementeerd of geïnstantieerd. Er zijn verschillende manieren om deze benadering te gebruiken. U kunt mysqldump, mydumper, rsync gebruiken of Percona XtraBackup/Mariabackup gebruiken en de gegevens naar uw doelknooppunt streamen.
Mysqldump gebruiken
mysqldump maakt een logische back-up van uw hele database of u kunt selectief een lijst met databases, tabellen of zelfs specifieke records kiezen die u wilde dumpen.
Een eenvoudige opdracht die u kunt gebruiken om een volledige back-up te maken, kan zijn:
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsMet deze eenvoudige opdracht voert het de MySQL-instructies rechtstreeks uit naar het doeldatabaseknooppunt, bijvoorbeeld uw doeldatabaseknooppunt op een Google Compute Engine. Dit kan efficiënt zijn wanneer de gegevens kleiner zijn of u een snelle bandbreedte hebt. Anders kan het uw optie zijn om uw database in een bestand in te pakken en vervolgens naar het doelknooppunt te sturen.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathVoer vervolgens mysqldump uit naar het doeldatabaseknooppunt als zodanig,
zcat mydata.db | mysqlHet nadeel van het gebruik van logische back-ups met mysqldump is dat het langzamer is en schijfruimte in beslag neemt. Het gebruikt ook een enkele thread, dus u kunt dit niet parallel uitvoeren. Optioneel kunt u mydumper gebruiken, vooral wanneer uw gegevens te groot zijn. mydumper kan parallel worden uitgevoerd, maar het is niet zo flexibel in vergelijking met mysqldump.
Xtrabackup gebruiken
xtrabackup is een fysieke back-up waar je de streams of binaire bestanden naar het doelknooppunt kunt sturen. Dit is zeer efficiënt en wordt meestal gebruikt bij het streamen van een back-up via het netwerk, vooral wanneer het doelknooppunt zich in een andere geografie of een andere regio bevindt. ClusterControl gebruikt xtrabackup bij het inrichten of instantiëren van een nieuwe slave, ongeacht waar deze zich bevindt, zolang de toegang en toestemming zijn ingesteld voorafgaand aan de actie.
Als je xtrabackup gebruikt om het handmatig uit te voeren, kun je het commando als zodanig uitvoeren,
## Doelknooppunt
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Bronknooppunt
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Om deze twee commando's uit te werken, moet het eerste commando eerst worden uitgevoerd of uitgevoerd op het doelknooppunt. De opdracht van het doelknooppunt luistert op poort 9999 en schrijft elke stream die wordt ontvangen van poort 9999 naar het doelknooppunt. Het is afhankelijk van de commando's socat en xbstream, wat betekent dat je ervoor moet zorgen dat deze pakketten zijn geïnstalleerd.
Op het bronknooppunt voert het het innobackupex perl-script uit dat xtrabackup op de achtergrond aanroept en gebruikt xbstream om de gegevens te streamen die over het netwerk worden verzonden. Het socat-commando opent poort 9999 en stuurt de gegevens naar de gewenste host, in dit voorbeeld 192.168.10.70. Zorg er echter voor dat u socat en xbstream hebt geïnstalleerd wanneer u deze opdracht gebruikt. Een alternatieve manier om socat te gebruiken is nc, maar socat biedt meer geavanceerde functies in vergelijking met nc, zoals serialisatie, omdat meerdere clients op een poort kunnen luisteren.
ClusterControl gebruikt dit commando bij het herbouwen van een slave of het bouwen van een nieuwe slave. Het is snel en garandeert dat de exacte kopie van uw brongegevens naar uw doelknooppunt wordt gekopieerd. Bij het inrichten van een nieuwe database op een aparte geolocatie, biedt het gebruik van deze aanpak meer efficiëntie en meer snelheid om de klus te klaren. Hoewel er voor- en nadelen kunnen zijn bij het gebruik van logische of binaire back-up wanneer deze via de draad wordt gestreamd. Het gebruik van deze methode is een veelgebruikte benadering bij het opzetten van een nieuw databasecluster met geolocatie naar een andere regio en het maken van een exacte kopie van uw databaseomgeving.
Efficiëntie, waarneembaarheid en snelheid
Vragen van de meeste mensen die niet bekend zijn met deze aanpak hebben altijd betrekking op de "HOE, WAT, WAAR"-problemen. In deze sectie bespreken we hoe u uw geolocatiedatabase efficiënt kunt opzetten met minder werk en met waarneembaarheid waarom deze niet werkt. Het gebruik van ClusterControl is zeer efficiënt. In deze huidige setup heb ik de volgende omgeving zoals aanvankelijk geïmplementeerd:
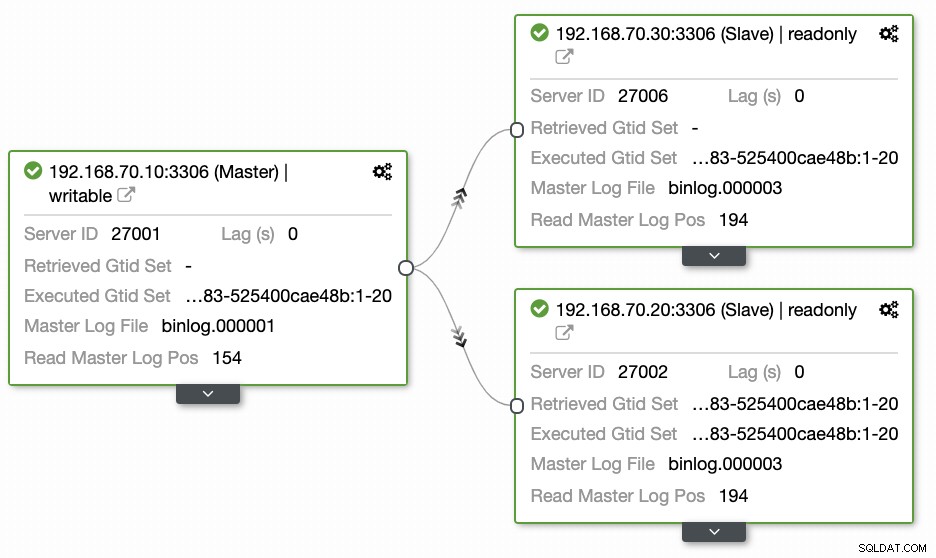
Node uitbreiden naar GCP
Begin met het opzetten van uw geo-Locatie databasecluster, om uw cluster uit te breiden en een snapshotkopie van uw cluster te maken, kunt u een nieuwe slave toevoegen. Zoals eerder vermeld, zal ClusterControl xtrabackup gebruiken (mariabackup voor MariaDB 10.2 en later) en een nieuw knooppunt in uw cluster implementeren. Voordat u uw GCP-rekenknooppunten kunt registreren als uw doelknooppunten, moet u eerst de juiste systeemgebruiker instellen die hetzelfde is als de systeemgebruiker die u in ClusterControl hebt geregistreerd. U kunt dit verifiëren in uw /etc/cmon.d/cmon_X.cnf, waarbij X de cluster_id is. Zie bijvoorbeeld hieronder:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (in dit voorbeeld) moet aanwezig zijn in uw GCP-rekenknooppunten. De gebruiker in uw GCP-knooppunten moet sudo- of superbeheerdersrechten hebben. Het moet ook worden ingesteld met een wachtwoordloze SSH-toegang. Lees onze documentatie meer over de systeemgebruiker en de vereiste rechten.
Laten we een voorbeeldlijst met servers hieronder hebben (van de GCP-console:Compute Engine-dashboard):
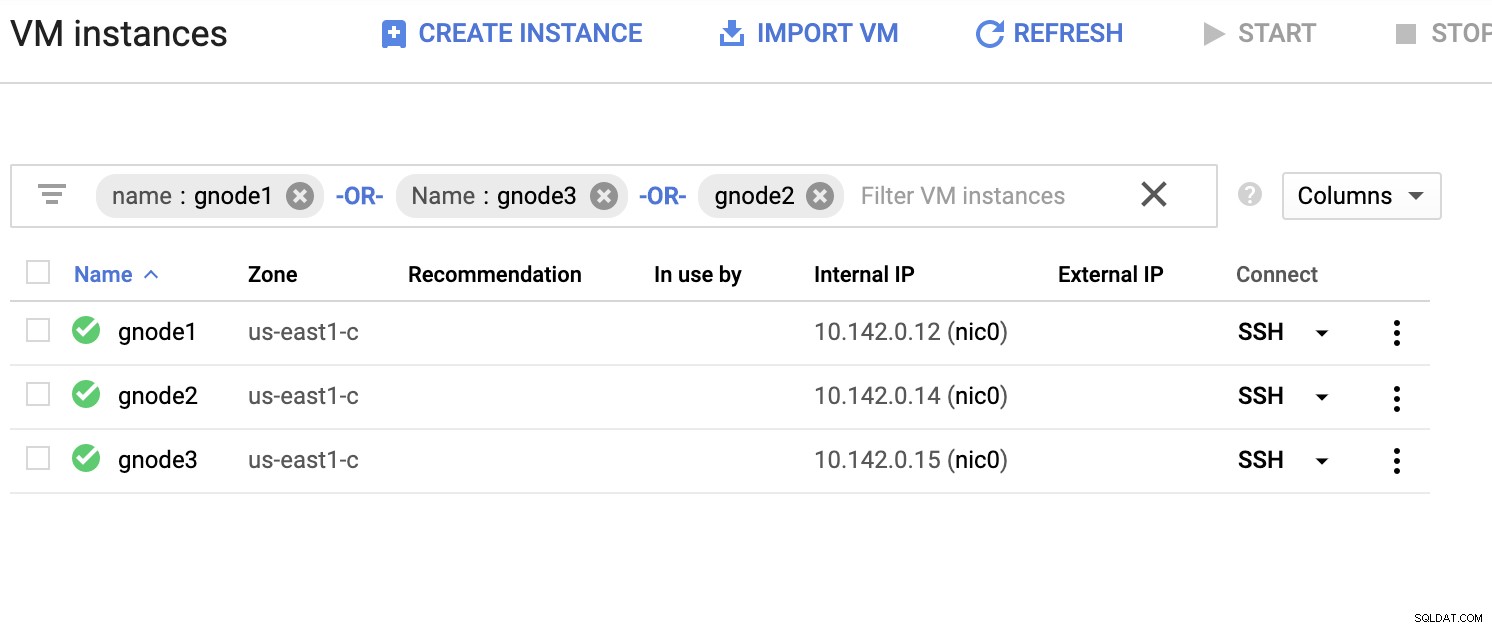
In de bovenstaande schermafbeelding is onze doelregio gebaseerd op het oosten van de VS regio. Zoals eerder opgemerkt, is mijn lokale netwerk ingesteld via een beveiligde laag die door GCP gaat (vice-versa) met behulp van OpenVPN. Dus communicatie van GCP die naar mijn lokale netwerk gaat, wordt ook ingekapseld via de VPN-tunnel.
Een slave-knooppunt toevoegen aan GCP
De onderstaande schermafbeelding laat zien hoe je dit kunt doen. Zie onderstaande afbeeldingen:
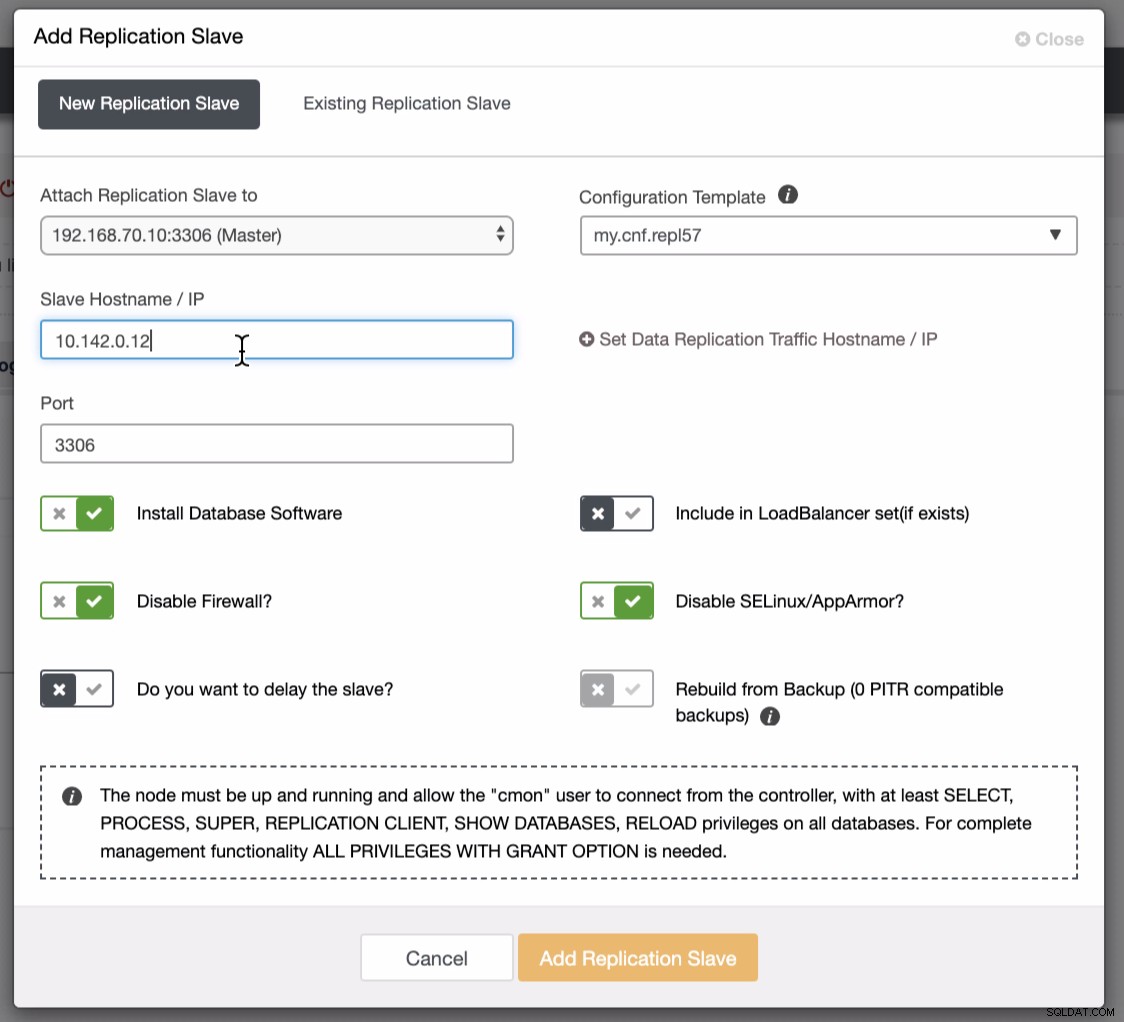
Zoals te zien is in de tweede schermafbeelding, richten we ons op knooppunt 10.142.0.12 en de bronmaster is 192.168.70.10. ClusterControl is slim genoeg om firewalls, beveiligingsmodules, pakketten, configuratie en setup te bepalen die moeten worden gedaan. Zie hieronder een voorbeeld van een taakactiviteitenlogboek:
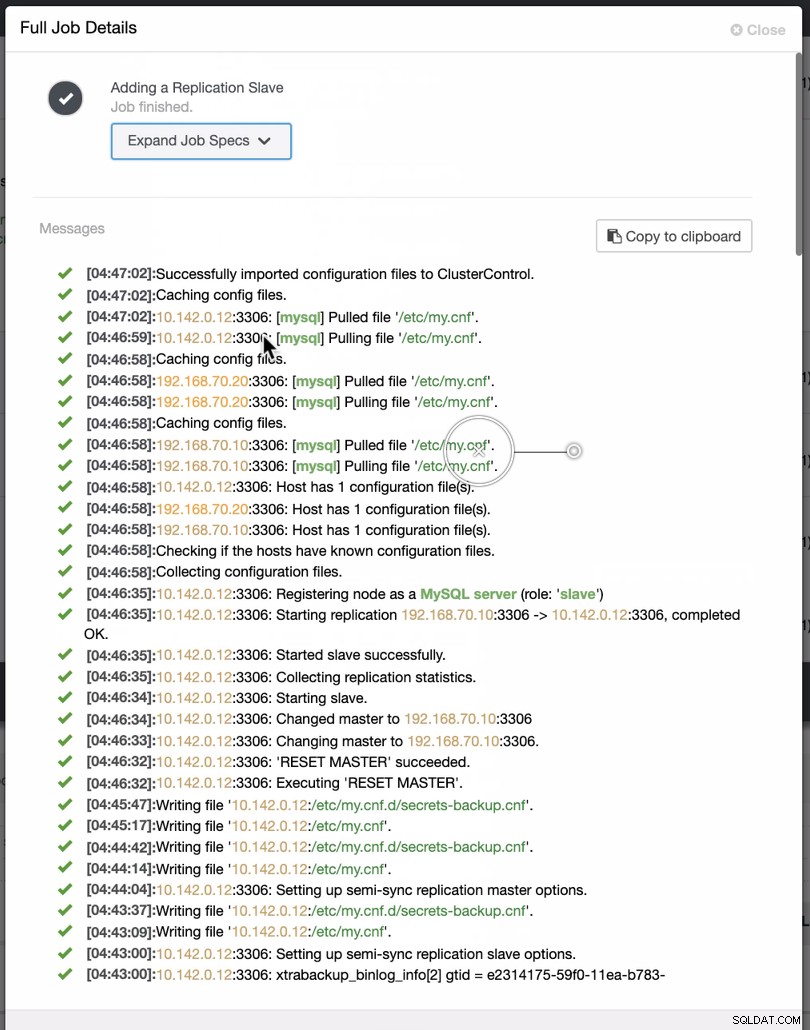
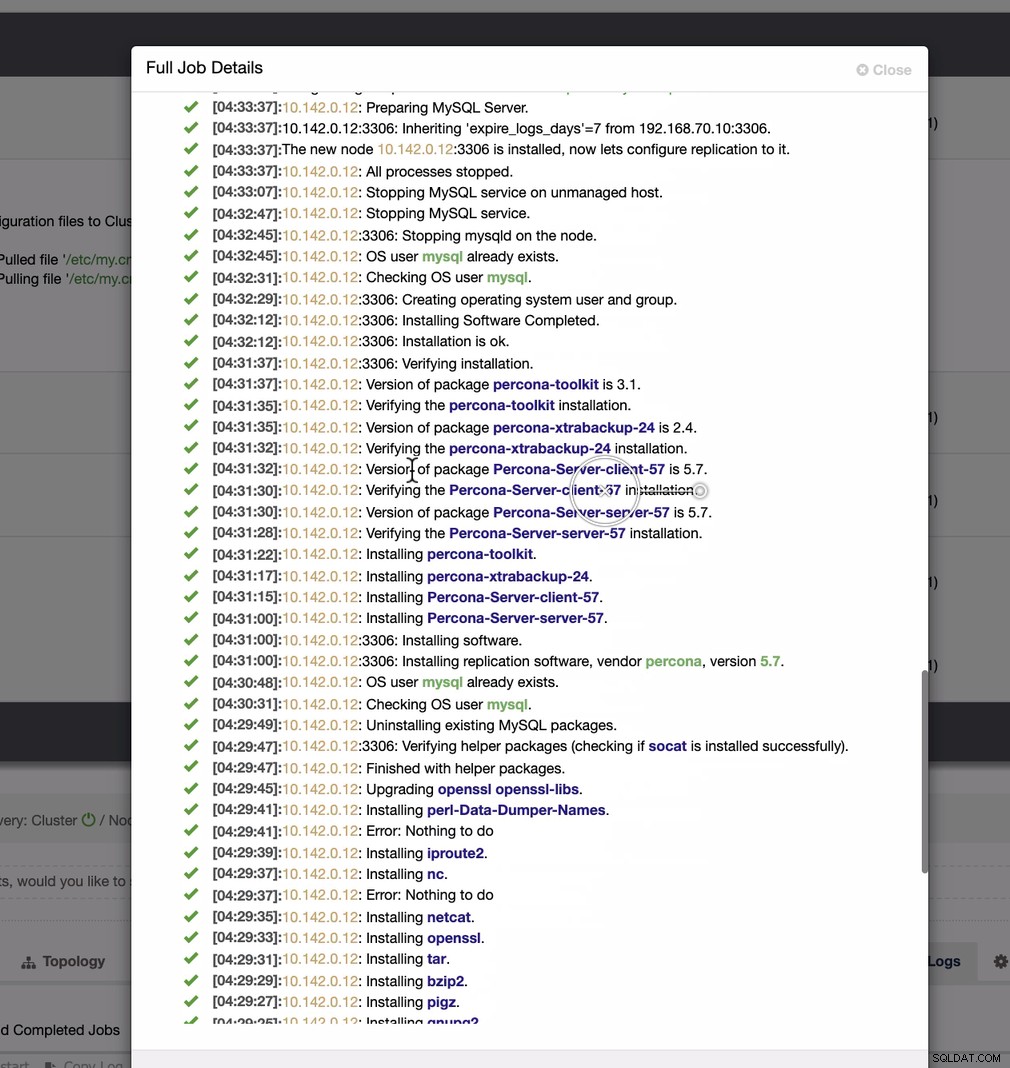
Een vrij eenvoudige taak, nietwaar?
Het GCP MySQL-cluster voltooien
We moeten nog twee knooppunten toevoegen aan het GCP-cluster om een balanstopologie te hebben zoals we die hadden in het lokale netwerk. Zorg er voor het tweede en derde knooppunt voor dat de master naar uw GCP-knooppunt moet wijzen. In dit voorbeeld is de master 10.142.0.12. Zie hieronder hoe u dit doet,
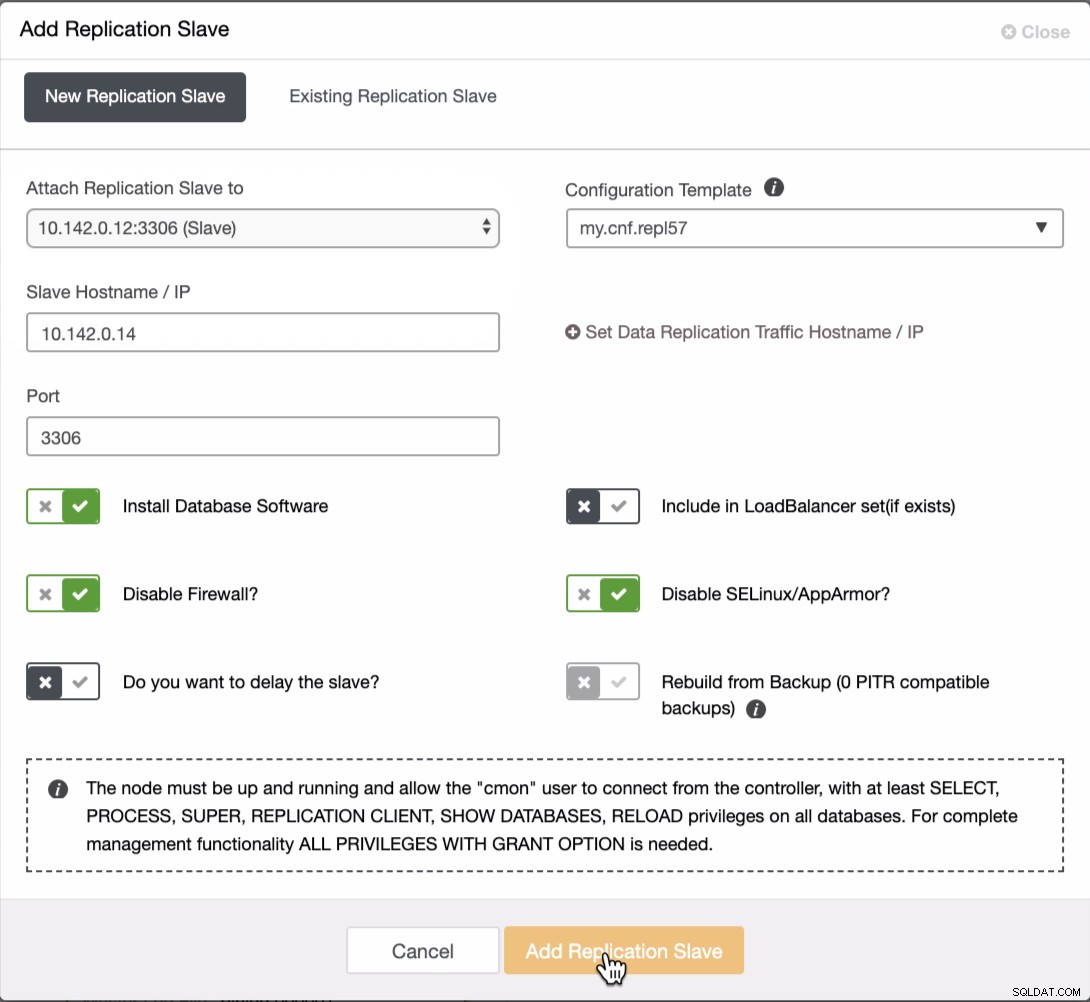
Zoals te zien is in de bovenstaande schermafbeelding, heb ik de 10.142.0.12 (slave ), wat het eerste knooppunt is dat we aan het cluster hebben toegevoegd. Het volledige resultaat ziet er als volgt uit,
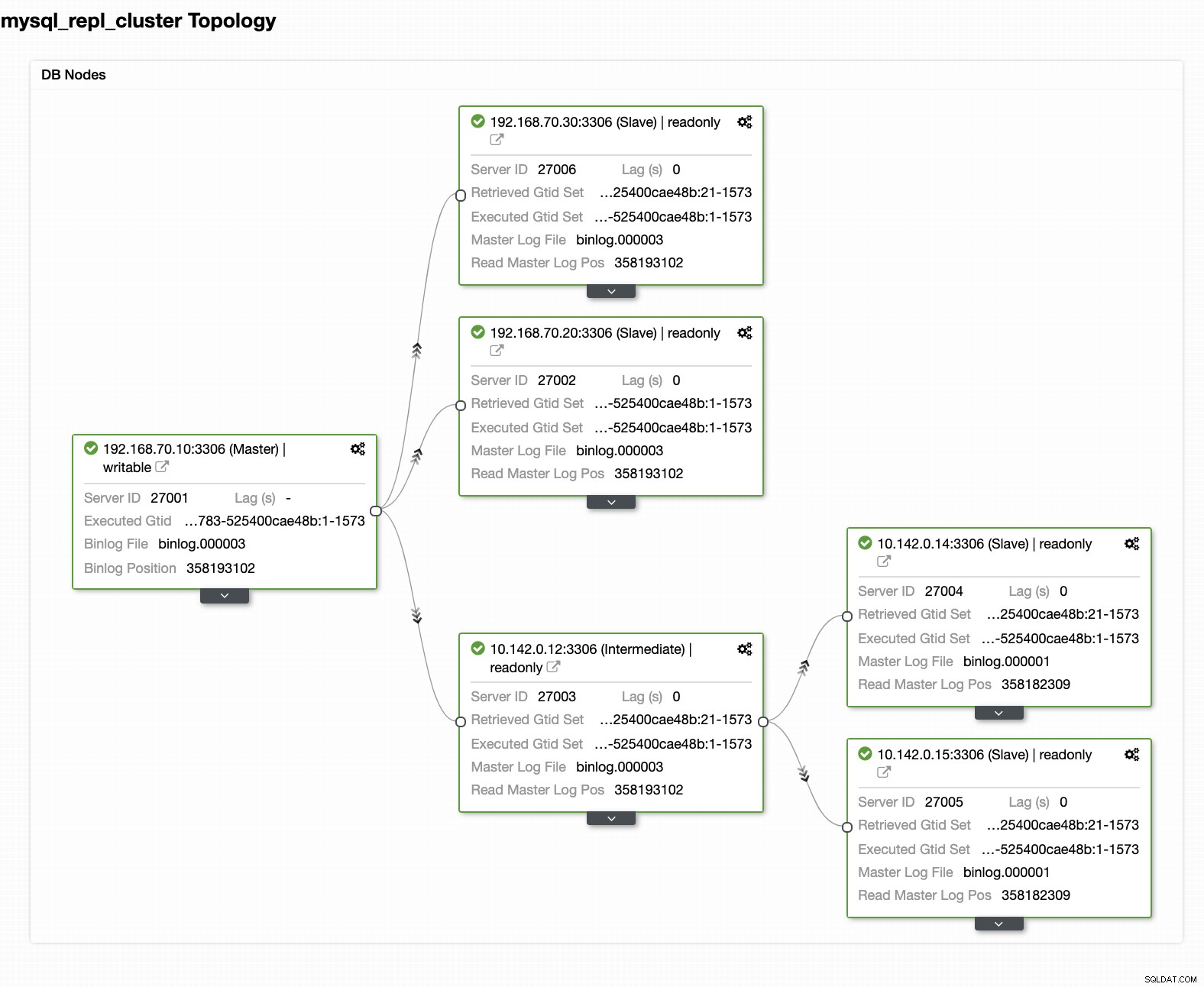
Uw definitieve configuratie van databasecluster met geolocatie
Vanaf de laatste schermafbeelding is dit soort topologie misschien niet je ideale opstelling. Meestal moet het een multi-masterconfiguratie zijn, waarbij uw DR-cluster fungeert als het standby-cluster, terwijl uw on-premises als het primaire actieve cluster dient. Om dit te doen, is het vrij eenvoudig in ClusterControl. Bekijk de volgende schermafbeeldingen om dit doel te bereiken.
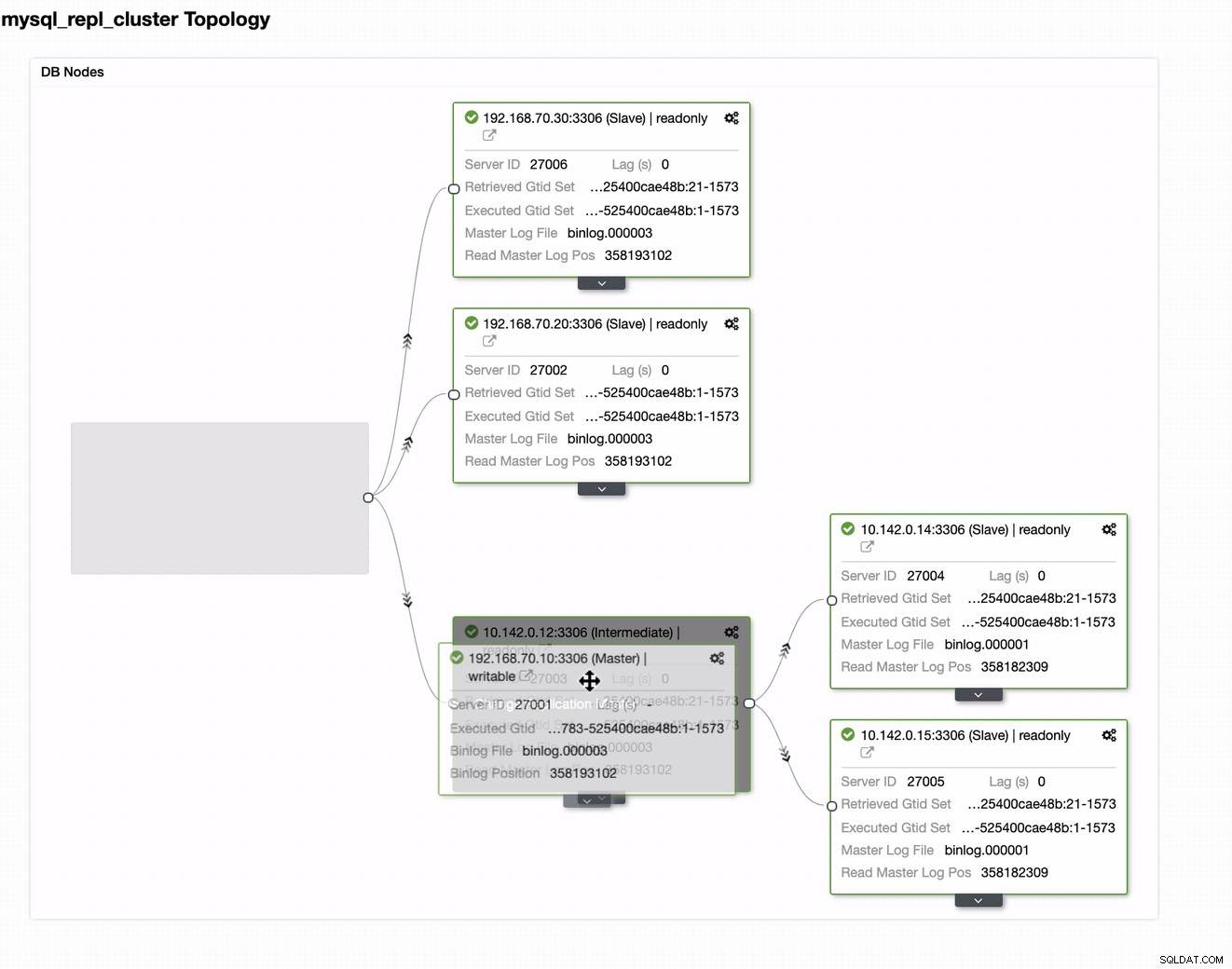
U kunt uw huidige master gewoon naar de doelmaster slepen die instellen als een primaire standby-schrijver voor het geval uw on-premises in gevaar komt. In dit voorbeeld slepen we targetinghost 10.142.0.12 (GCP-rekenknooppunt). Het eindresultaat wordt hieronder getoond:
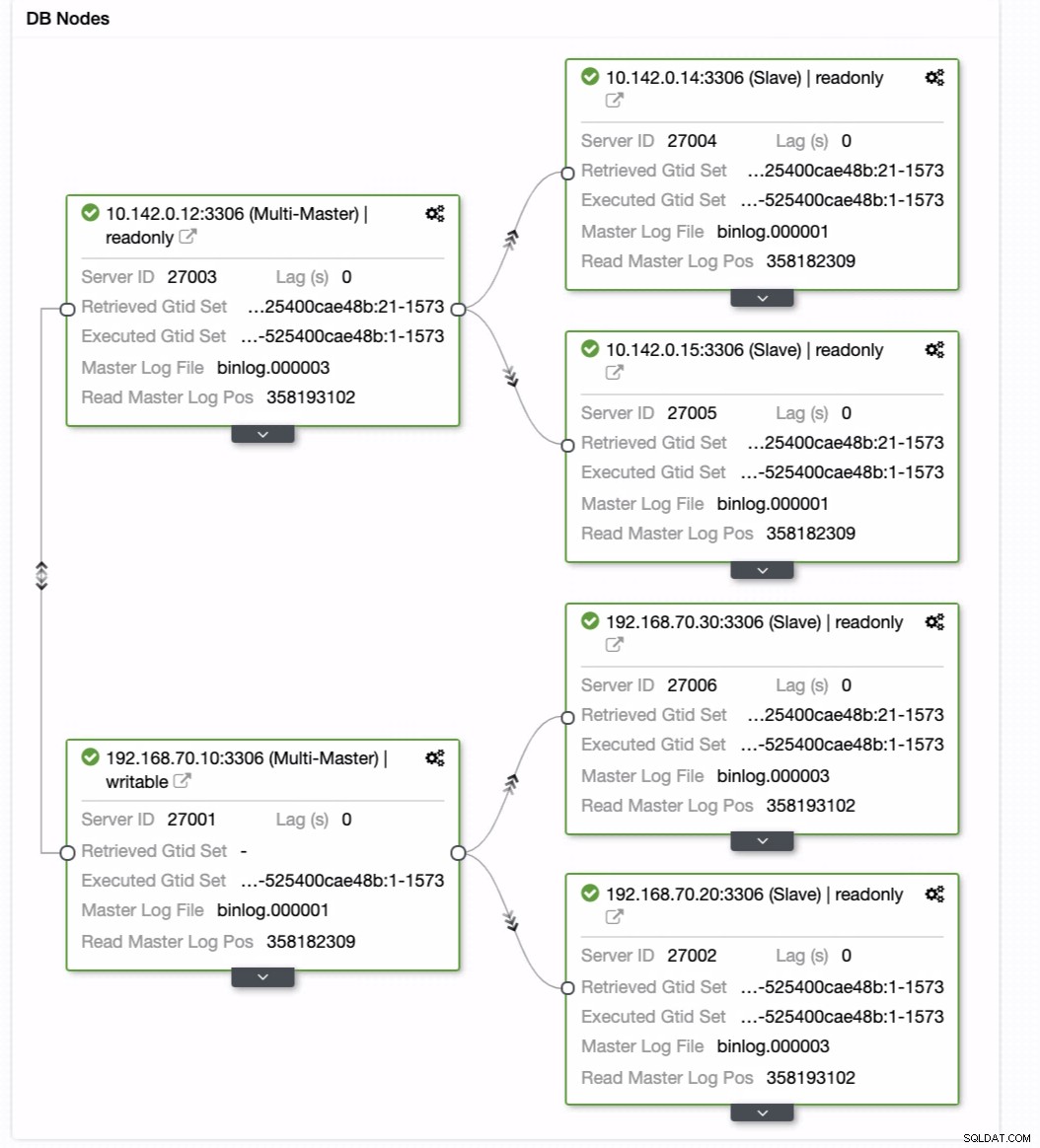
Dan bereikt het het gewenste resultaat. Gemakkelijk en zeer snel om uw Geo-Location Database-cluster te spawnen met MySQL-replicatie.
Conclusie
Het hebben van een Geo-Location Database Cluster is niet nieuw. Het was een gewenste opzet voor bedrijven en organisaties die SPOF vermijden en die veerkracht en een lagere RPO willen.
De belangrijkste aandachtspunten voor deze opstelling zijn beveiliging, redundantie en veerkracht. Het behandelt ook hoe haalbaar en efficiënt u uw nieuwe cluster in een andere geografische regio kunt implementeren. Hoewel ClusterControl dit kan bieden, verwachten we dat we hier eerder meer verbetering in kunnen brengen, waar je efficiënt kunt creëren vanuit een back-up en je nieuwe andere cluster in ClusterControl kunt spawnen, dus houd ons in de gaten.