InnoDB is een van de meest gebruikte opslagengines in MySQL. Deze opslagengine staat bekend als een zeer betrouwbare en krachtige opslagengine en de belangrijkste voordelen zijn onder meer de ondersteuning van vergrendeling op rijniveau, externe sleutels en het volgen van het ACID-model. InnoDB vervangt MyISAM als de standaard opslagengine sinds MySQL 5.5, dat in 2010 werd uitgebracht.
Deze opslagengine kan ongelooflijk krachtig en krachtig zijn als hij goed wordt geoptimaliseerd. Vandaag bekijken we de dingen die we kunnen doen om hem zo goed mogelijk te laten presteren, maar voordat we gaan duiken in InnoDB moeten we echter begrijpen wat het bovengenoemde ACID-model is.
Wat is ACID en waarom is het belangrijk?
ACID is een set eigenschappen van databasetransacties. Het acroniem vertaalt zich in vier woorden:Atomiciteit, Consistentie, Isolatie en Duurzaamheid. Kortom, deze eigenschappen zorgen ervoor dat databasetransacties betrouwbaar worden verwerkt en garanderen de geldigheid van de gegevens ondanks fouten, stroomuitval of dergelijke problemen. Een databasebeheersysteem dat aan deze principes voldoet, wordt een ACID-compatibel DBMS genoemd. Zo werkt alles in InnoDB:
- Atomiciteit zorgt ervoor dat de verklaringen in een transactie als een ondeelbare eenheid werken en dat hun effecten collectief of helemaal niet worden gezien;
- Consistentie wordt afgehandeld door de logmechanismen van MySQL die alle wijzigingen in de database registreren;
- Isolatie verwijst naar InnoDB's vergrendeling op rijniveau;
- Duurzaamheid wordt ook gehandhaafd omdat InnoDB een logbestand bijhoudt dat alle wijzigingen aan het systeem bijhoudt.
InnoDB begrijpen
Nu we ACID hebben behandeld, moeten we waarschijnlijk kijken hoe InnoDB er onder de motorkap uitziet. Zo ziet InnoDB er van binnen uit (afbeelding met dank aan Percona):
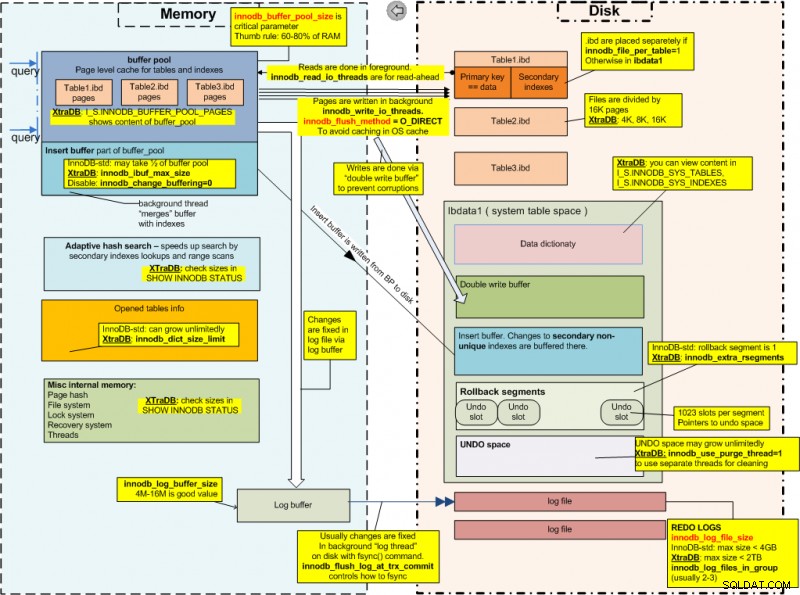 InnoDB Internals
InnoDB InternalsUit de afbeelding hierboven kunnen we duidelijk zien dat InnoDB een paar parameters die cruciaal zijn voor de prestaties en deze zijn als volgt:
- De parameter innodb_data_file_path beschrijft de systeemtabelruimte (de systeemtabelruimte is het opslaggebied voor het InnoDB-datawoordenboek, de dubbele schrijf- en wijzigingsbuffers en ongedaan maken van logbestanden). De parameter geeft het bestand weer waarin gegevens afkomstig van InnoDB-tabellen worden opgeslagen;
- De parameter innodb_buffer_pool_size is een geheugenbuffer die InnoDB gebruikt om gegevens en indexen van zijn tabellen in de cache op te slaan;
- De parameter innodb_log_file_size geeft de grootte van InnoDB-logbestanden weer;
- De parameter innodb_log_buffer_size wordt gebruikt om naar de logbestanden op schijf te schrijven;
- De parameter innodb_flush_log_at_trx_commit regelt de balans tussen strikte ACID-compliance en hogere prestaties;
- De parameter innodb_lock_wait_timeout is de tijdsduur in seconden dat een InnoDB-transactie wacht op een rijvergrendeling voordat deze opgeeft;
- De parameter innodb_flush_method definieert de methode die wordt gebruikt om gegevens naar InnoDB-gegevensbestanden en logbestanden te spoelen die de I/O-doorvoer kunnen beïnvloeden.
InnoDB slaat de gegevens van zijn tabellen ook op in een bestand met de naam ibdata1 - de logs worden echter opgeslagen in twee afzonderlijke bestanden genaamd ib_logfile0 en ib_logfile1:al deze drie bestanden bevinden zich in de /var/lib/mysql map.
Om InnoDB zo performant mogelijk te maken, moeten we deze parameters verfijnen en ze zo goed mogelijk optimaliseren door te kijken naar onze beschikbare hardwarebronnen.
InnoDB afstemmen voor hoge prestaties
Volg deze stappen om de prestaties van InnoDB op uw hardware aan te passen:
-
Om innodb_data_file_path automatisch uit te breiden, specificeert u het autoextend attribuut in de instelling en start u de server opnieuw op. Bijvoorbeeld:
innodb_data_file_path=ibdata1:10M:autoextendAls de parameter autoextend wordt gebruikt, wordt het gegevensbestand automatisch groter met stappen van 8 MB telkens wanneer er ruimte nodig is. Een nieuw automatisch uitbreidend gegevensbestand kan ook als volgt worden gespecificeerd (in dit geval wordt het nieuwe gegevensbestand ibdata2 genoemd):
innodb_data_file_path=ibdata1:10M;ibdata2:10M:autoextend-
Bij gebruik van InnoDB is het belangrijkste mechanisme dat wordt gebruikt de bufferpool. InnoDB is sterk afhankelijk van de bufferpool en als vuistregel moet de parameter innodb_buffer_pool_size ongeveer 60% tot 80% van het totale beschikbare RAM-geheugen op de server zijn. Houd er rekening mee dat u ook wat RAM moet overlaten voor de processen die in het besturingssysteem worden uitgevoerd;
-
Innodb's innodb_log_file_size moet zo groot mogelijk worden ingesteld, maar niet groter dan nodig. Houd er in dit geval rekening mee dat een groter logbestand beter is voor de prestaties, maar hoe groter het is, hoe meer hersteltijd na een crash nodig is. Als zodanig is er geen "one size fits all" -oplossing, maar er wordt gezegd dat de gecombineerde grootte van de logbestanden groot genoeg moet zijn. Dit helpt de MySQL-server om regelmatig te werken aan controlepunten en schijfopruimingsactiviteiten. Dit bespaart te veel CPU- en schijf-IO en kan soepel werken tijdens piekuren of hoge werkbelasting. Hoewel de aanbevolen aanpak is om het zelf te testen en te experimenteren en zelf de optimale waarde te vinden;
-
De innodb_log_buffer_size waarde moet worden ingesteld op ten minste 16 miljoen. Met een grote logbuffer kunnen grote transacties worden uitgevoerd zonder dat het log naar schijf hoeft te worden geschreven voordat de transacties worden vastgelegd, waardoor schijf-I/O wordt bespaard;
-
Houd er bij het afstemmen van innodb_flush_log_at_trx_commit rekening mee dat deze parameter drie waarden accepteert - 0, 1 en 2. Met een waarde van 1 krijgt u ACID-conformiteit en met waarden 0 of 2 krijg je meer performance, maar minder betrouwbaarheid omdat in dat geval transacties waarvan de logs nog niet naar schijf zijn geflusht bij een crash verloren kunnen gaan;
-
Om innodb_lock_wait_timeout op een juiste waarde in te stellen, moet u er rekening mee houden dat deze parameter de tijd in seconden definieert (de standaardwaarde is 50) voordat het geven van de volgende fout en het terugdraaien van de huidige verklaring:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction-
In InnoDB zijn meerdere spoelmethoden beschikbaar. Standaard is deze instelling ingesteld op "async_unbuffered" op Windows-machines als de waarde is ingesteld op NULL en op "fsync" op Linux-machines. Dit zijn de methoden en wat ze doen:
InnoDB-spoelmethode
Doel
normaal
InnoDB gebruikt gesimuleerde asynchrone I/O en gebufferde I/O.
niet gebufferd
InnoDB gebruikt gesimuleerde asynchrone I/O en niet-gebufferde I/O.
async_unbuffered
InnoDB zal Windows asynchrone I/O en niet-gebufferde I/O gebruiken. Standaardinstellingen op Windows-machines.
fsync
InnoDB zal de functie fsync() gebruiken om de gegevens en de logbestanden te wissen. Standaardinstelling op Linux-machines.
O_DSYNC
InnoDB gebruikt O_SYNC om de logbestanden te openen en te wissen en de functie fsync() om de gegevensbestanden te wissen. O_DSYNC is sneller dan O_DIRECT, maar gegevens kunnen al dan niet consistent zijn vanwege latentie of een regelrechte crash.
nosync
Gebruikt voor interne prestatietests - niet ondersteund.
littlesync
Gebruikt voor interne prestatietests - niet ondersteund.
O_DIRECT
InnoDB gebruikt O_DIRECT om de gegevensbestanden te openen en de functie fsync() om zowel de gegevens als de logbestanden te wissen. In vergelijking met O_DSYNC is O_DIRECT stabieler en consistenter met gegevens, maar langzamer. De OS-cache wordt vermeden met deze instelling - deze instelling is de aanbevolen instelling op Linux-machines.
O_DIRECT_NO_FSYNC
InnoDB zal O_DIRECT gebruiken tijdens het leegmaken van I/O - het gedeelte "NO_FSYNC" definieert dat de functie fsync() wordt overgeslagen.
- Overweeg ook om de instelling innodb_file_per_table in te schakelen. Deze parameter is standaard AAN in MySQL 5.6 en hoger. Deze parameter verlost u van beheersproblemen met betrekking tot InnoDB-tabellen door ze in afzonderlijke bestanden op te slaan en opgeblazen hoofdwoordenboeken en systeemtabellen te vermijden. Door deze variabele in te schakelen, wordt ook voorkomen dat u te maken krijgt met complexiteit van gegevensherstel wanneer een bepaalde tabel beschadigd is
- Nu je deze instellingen hebt gewijzigd volgens de hierboven beschreven instructies, zou je bijna klaar moeten zijn om te gaan! Voordat je echter van start gaat, moet je waarschijnlijk het drukste bestand in de hele InnoDB-infrastructuur in de gaten houden - de ibdata1.
Omgaan met ibdata1
Er zijn verschillende soorten informatie die zijn opgeslagen in ibdata1:
- De gegevens van InnoDB-tabellen;
- De indexen van InnoDB-tabellen;
- InnoDB-tabelmetadata;
- Multiversion Concurrency Control (MVCC)-gegevens;
- De dubbele schrijfbuffer - zo'n buffer stelt InnoDB in staat om te herstellen van halfgeschreven pagina's. Het doel van zo'n buffer is om datacorruptie te voorkomen;
- De invoegbuffer - een dergelijke buffer wordt door InnoDB gebruikt om updates naar dezelfde pagina te bufferen, zodat ze in één keer kunnen worden uitgevoerd en niet achter elkaar.
Bij het omgaan met grote datasets kan het ibdata1-bestand extreem groot worden en dit kan de kern zijn van een zeer frustrerend probleem - het bestand kan alleen maar groeien en standaard kan het niet krimpen. U kunt MySQL afsluiten en dit bestand verwijderen, maar dit wordt niet aanbevolen, tenzij u weet wat u doet. Na verwijdering zal MySQL niet goed werken omdat het woordenboek en de systeemtabellen zijn verdwenen, waardoor de hoofdsysteemtabel beschadigd is.
Volg deze stappen om ibdata1 voor eens en altijd te verkleinen:
- Dump alle gegevens uit InnoDB-databases. U kunt voor deze actie mysqldump of mysqlpump gebruiken;
- Alle databases verwijderen behalve de databases mysql, performance_schema en information_schema;
- Stop MySQL;
- Voeg het volgende toe aan je my.cnf-bestand:
[mysqld] innodb_file_per_table = 1 innodb_flush_method = O_DIRECT innodb_log_file_size = 25% of innodb_buffer_pool_size innodb_buffer_pool_size = up to 60-80% of available RAM. - Verwijder de bestanden ibdata1 en ib_logfile* (deze worden opnieuw gemaakt bij de volgende herstart van MySQL);
- Start MySQL en herstel de gegevens van de eerder gemaakte dump. Na het uitvoeren van de hierboven beschreven stappen, zal het ibdata1-bestand nog steeds groeien, maar het zal niet langer de gegevens van InnoDB-tabellen bevatten - het bestand zal alleen metagegevens bevatten en elke InnoDB-tabel zal buiten ibdata1 bestaan. Als u nu naar de map /var/lib/mysql gaat, ziet u twee bestanden die elke tabel vertegenwoordigen die u met de InnoDB-engine hebt. De bestanden zullen er als volgt uitzien:
- demotable.frm
- demotable.ibd
Het .frm-bestand bevat de header van de storage-engine en het .ibd-bestand bevat de tabelgegevens en indexen van uw tabel.
Zorg er echter voor dat u de parameters afstemt op uw infrastructuur voordat u de wijzigingen implementeert. Deze parameters kunnen de prestaties van InnoDB maken of breken, dus houd ze altijd in de gaten. Nu zou je goed moeten zijn om te gaan!
Samenvatting
Samenvattend:het optimaliseren van de prestaties van InnoDB kan een groot voordeel zijn als u toepassingen ontwikkelt die tegelijkertijd gegevensintegriteit en hoge prestaties vereisen - Met InnoDB kunt u wijzigen hoeveel geheugen de engine mag gebruiken verbruiken, om de grootte van het logbestand, de spoelmethode die de engine gebruikt enzovoort te wijzigen - deze wijzigingen kunnen ervoor zorgen dat InnoDB buitengewoon goed presteert als ze goed zijn afgesteld. Pas echter op voor de gevolgen van uw acties voor zowel uw server als MySQL voordat u verbeteringen doorvoert.
Zoals altijd, voordat u iets voor prestaties optimaliseert, moet u altijd back-ups maken (en testen!) zodat u uw gegevens indien nodig kunt herstellen en eventuele wijzigingen altijd op een lokale server testen voordat u de wijzigingen naar productie implementeert.
/P>