In eerdere blogposts hebben we onderwerpen behandeld voor het bewaken van uw Galera-cluster, of het nu MySQL of MariaDB is. Hoewel de technologieversies niet veel verschillen, heeft MariaDB Cluster enkele belangrijke wijzigingen ondergaan sinds versie 10.4.2. In deze versie ondersteunt het Galera Cluster 4 en heeft het een aantal geweldige nieuwe functies die we in deze blogpost zullen bekijken.
Voor beginners die nog niet bekend zijn met MariaDB Cluster: is een vrijwel synchrone multi-mastercluster voor MariaDB. Het is alleen beschikbaar op Linux en ondersteunt alleen de XtraDB/InnoDB-opslagengines (hoewel er experimentele ondersteuning is voor MyISAM - zie de systeemvariabele wsrep_replicate_myisam).
De software is een gebundelde technologie die wordt aangedreven door MariaDB Server, MySQL-wsrep-patch voor MySQL Server en MariaDB Server ontwikkeld door Codership (ondersteunt Unix-achtig besturingssysteem), en de Galera wsrep-providerbibliotheek.
U kunt dit product vergelijken met MySQL Group Replication of met de MySQL InnoDB Cluster, die een hoge beschikbaarheid wil bieden. (Hoewel ze verschillen qua principes en benaderingen voor het leveren van HA.)
Nu we de basis hebben behandeld, gaan we in deze blog tips geven die volgens ons nuttig zijn bij het bewaken van uw MariaDB-cluster.
De essentie van MariaDB Cluster
Wanneer u MariaDB Cluster gaat gebruiken, moet u vaststellen wat precies uw doel is en waarom u in de eerste plaats voor MariaDB Cluster hebt gekozen. Eerst moet u begrijpen wat de functies en hun voordelen zijn bij het gebruik van MariaDB Cluster. De reden om deze te identificeren, is omdat dit in wezen is wat moet worden gecontroleerd en gecontroleerd om de prestaties, normale gezondheidstoestanden en of het volgens uw plannen verloopt te bepalen.
In wezen wordt het geïdentificeerd als geen slaafvertraging, geen verloren transacties, leesschaalbaarheid en kleinere clientlatenties. Dan kunnen er vragen rijzen als, hoe maakt het geen slaafvertraging of verloren transacties? Hoe maakt het lezen schaalbaar of met kleinere latenties aan de clientzijde? Deze gebieden zijn een van de belangrijkste gebieden die u moet bekijken en controleren, vooral bij intensief productiegebruik.
Hoewel het MariaDB-cluster zelf dienovereenkomstig kan worden aangepast. Het toepassen van wijzigingen in het standaardgedrag, zoals pc.weight of pc.ignore_quorum, of zelfs het gebruik van multicast met UDP voor een groot aantal knooppunten, kan van invloed zijn op de manier waarop u de aard van uw MariaDB-cluster bewaakt. Maar aan de andere kant zijn de meest essentiële statusvariabelen meestal uw zilveren randje hier, wetende dat de staat en stroom van uw cluster goed gaat of dat de degradatie ervan vooraf een mogelijk probleem aangeeft dat tot een catastrofale storing leidt.
Bewaak altijd uw serveractiviteit (netwerk, schijf, belasting, geheugen en CPU)
Het bewaken van uw serveractiviteit kan ook een complexe taak zijn als u een zeer gecompliceerde stack heeft die verweven is met uw database-architectuur. Voor een MariaDB-cluster is het echter altijd het beste om uw knooppunten altijd zo toegewijd en toch eenvoudig mogelijk in te stellen. Hoewel dat u er niet van weerhoudt om alle reservebronnen te gebruiken, vindt u hieronder de belangrijkste punten waar u op moet letten.
Netwerk
Galera Cluster 4 biedt streaming-replicatie als een van de belangrijkste functies en wijzigingen ten opzichte van de vorige versie. Aangezien streaming-replicatie de nadelen aanpakt die het had in de vorige releases, maar het in staat stelt meer dan 2 GB aan schrijfsets te beheren sinds Galera Cluster 4. Hierdoor kunnen grote transacties worden gefragmenteerd en het wordt ten zeerste aanbevolen om dit alleen op sessieniveau in te schakelen. Dit betekent dat het bewaken van uw netwerkactiviteit erg belangrijk en cruciaal is voor de normale activiteit van uw MariaDB-cluster. Dit zal u helpen te identificeren welk knooppunt het meeste of hoogste netwerkverkeer had op basis van de tijdsperiode.
Dus hoe kan dat je helpen om te verbeteren waar nodes met het meeste netwerkverkeer zijn geïdentificeerd? Welnu, dit biedt u ruimte voor verbetering met uw databasetopologie of de architecturale laag van uw databasecluster. Door load balancers of een databaseproxy te gebruiken, kunt u uw databaseverkeer proactief configureren, vooral bij het bepalen welke specifieke schrijfbewerkingen naar een specifiek knooppunt moeten gaan. Laten we zeggen dat van de 3 knooppunten een van hen beter in staat is om grote en grote vragen te verwerken vanwege verschillen met de hardwarespecificaties. Dit stelt u in staat om meer van uw capex te beheren en uw capaciteitsplanning te verbeteren als er een bepaalde periode verandert.
Schijf
Omdat netwerkactiviteit ook van belang is voor uw schijfprestaties, vooral tijdens de spoeltijd. Het is ook het beste om te bepalen hoe toegewijde tijd en ophaalprestaties presteren wanneer een hoge piekbelasting wordt bereikt. Er zijn tijden dat u uw databasehost invult door niet alleen toegewijd te zijn aan een Galera Cluster-activiteit, maar ook met andere tools zoals docker, SQL-proxy's zoals ProxySQL of MaxScale. Dit geeft u controle met servers met een lage belasting en stelt u in staat de beschikbare bronnen te gebruiken die voor andere nuttige doeleinden kunnen worden gebruikt, met name voor uw database-architectuurstack. Als u eenmaal in staat bent om te bepalen welk knooppunt bij bewaking de laagste belasting heeft, maar nog steeds in staat is om het schijf-IO-gebruik te beheren, kunt u het specifieke knooppunt selecteren terwijl u de tijd in de gaten houdt. Nogmaals, dit geeft u nog steeds een beter beheer van uw capaciteitsplanning.
CPU, geheugen en laadactiviteit
Laat me in het kort deze drie punten noemen waar je op moet letten bij het monitoren. In deze sectie is het altijd het beste dat u de volgende gebieden tegelijk beter kunt observeren. Het is sneller en gemakkelijker te begrijpen, met name het uitsluiten van een prestatieknelpunt of het identificeren van bugs die ervoor zorgen dat uw knooppunten vastlopen en die ook van invloed kunnen zijn op de andere knooppunten en de mogelijkheid om naar beneden te gaan in het cluster.
Dus hoe helpen CPU, geheugen en laadactiviteit bij monitoring je MariaDB-cluster? Welnu, zoals ik hierboven heb vermeld, zijn dit een van de weinige dingen die toch een grote factor zijn voor dagelijkse routinecontroles. Dit helpt u ook te bepalen of dit periodieke of willekeurige gebeurtenissen zijn. Als het periodiek is, kan het te maken hebben met back-ups die in een van uw Galera-knooppunten worden uitgevoerd, of het is een enorme vraag die moet worden geoptimaliseerd. Bijvoorbeeld slechte query's zonder goede indexen, of onevenwichtig gebruik van het ophalen van gegevens, zoals het doen van een tekenreeksvergelijking voor zo'n grote tekenreeks. Dat kan onmiskenbaar niet van toepassing zijn op databases van het OLTP-type zoals MariaDB Cluster, vooral als het echt de aard en vereisten van uw toepassing zijn. Gebruik beter andere analytische tools zoals MariaDB Columnstore of andere analytische verwerkingstools van derden (Apache Spark, Kafka of MongoDB, enz.) voor het ophalen van grote stringgegevens en/of het matchen van strings.
Dus met al deze belangrijke gebieden die worden bewaakt, is de vraag, hoe dit zal worden gecontroleerd? Het moet minimaal per minuut worden gecontroleerd. Met verfijnde monitoring, d.w.z. per seconde van collectieve statistieken, kan het arbeidsintensief zijn en veel hebzuchtig in termen van uw bronnen. Hoewel een halve minuut collectiviteit acceptabel is, vooral als uw gegevens en RPO (recovery point objective) erg laag zijn, heeft u meer gedetailleerde en realtime gegevensstatistieken nodig. Het is erg belangrijk dat u het hele plaatje van uw databasecluster kunt overzien. Afgezien hiervan is het ook het beste en belangrijk dat je, ongeacht welke statistieken je bewaakt, de juiste tool hebt om je aandacht te trekken wanneer dingen in gevaar zijn of zelfs alleen maar waarschuwingen. Door de juiste tool zoals ClusterControl te gebruiken, kunt u deze belangrijke te bewaken gebieden beheren. Ik gebruik hier een gratis versie of community-editie van ClusterControl en helpt me om met slechts een paar klikken mijn nodes te monitoren, van installatie tot monitoring van nodes. Zie bijvoorbeeld de onderstaande schermafbeeldingen:

De weergave is een meer verfijnd en snel overzicht van wat er momenteel gebeurt. Er kan ook een meer gedetailleerde grafiek worden gebruikt,
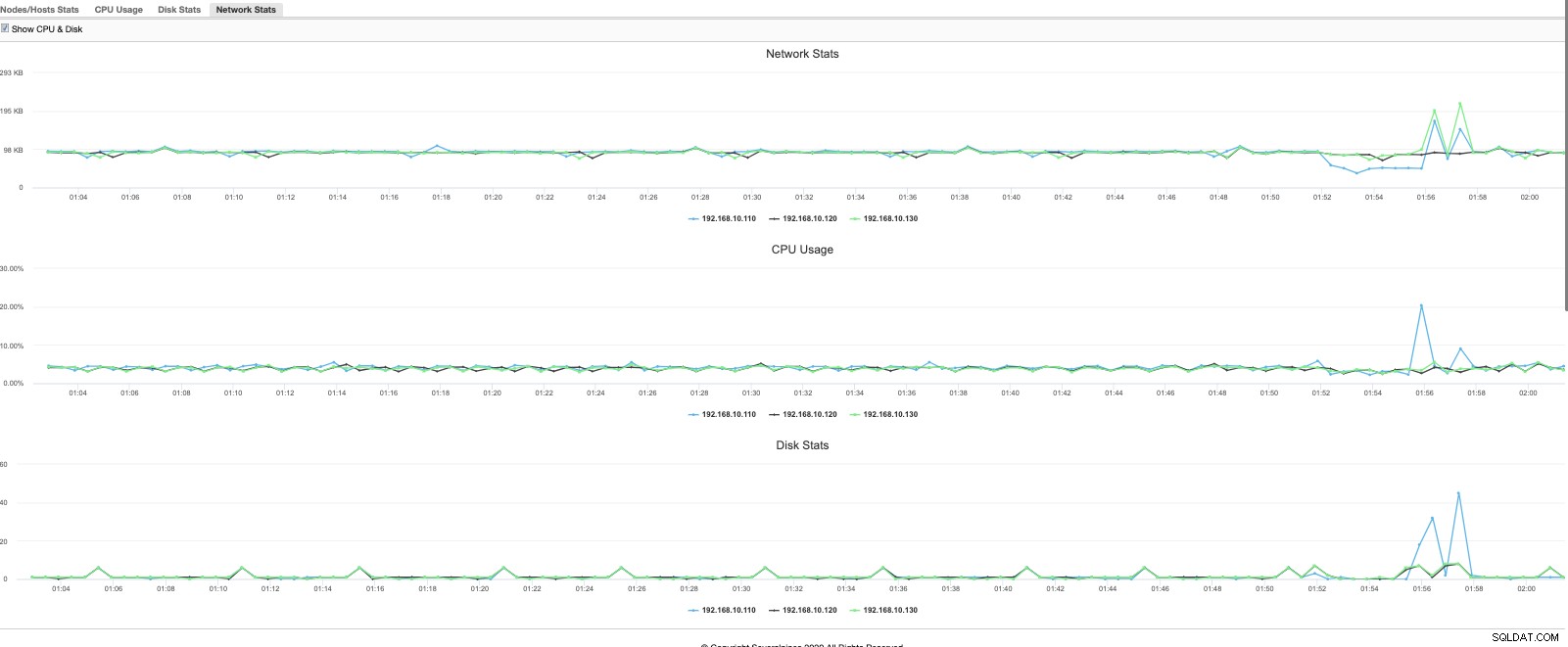
of met een krachtiger en uitgebreider gegevensmodel dat ook querytaal ondersteunt, kan bieden u een analyse van hoe uw MariaDB-cluster presteert op basis van historische gegevens die de prestaties tijdig vergelijken. Bijvoorbeeld,
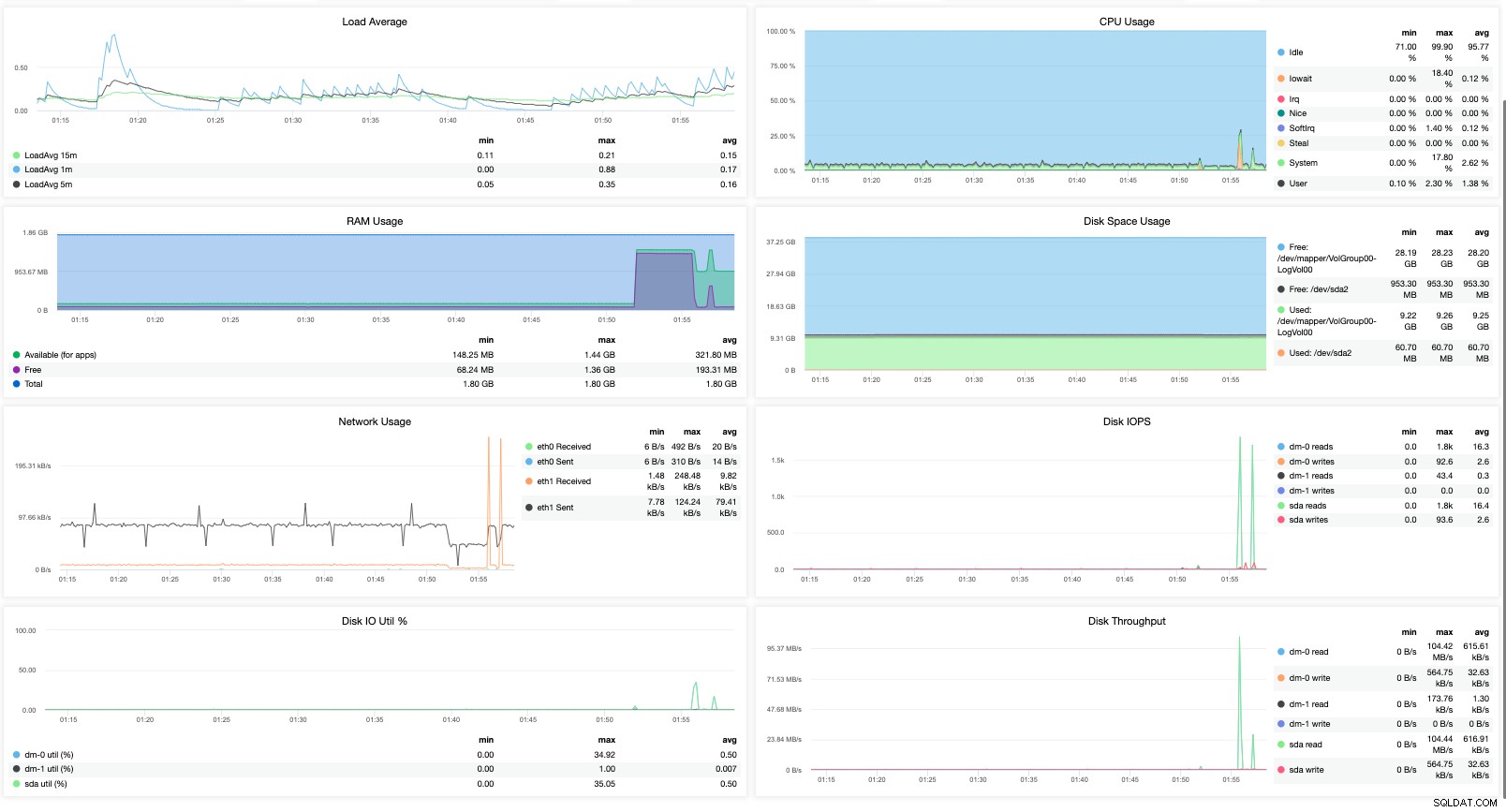
Dat geeft je alleen maar meer zichtbare statistieken. U ziet dus hoe belangrijk het is om de juiste tool te hebben bij het bewaken van uw MariaDB-cluster.
Zorg voor collectieve bewaking van uw statistische variabelen van het MariaDB-cluster
Van tijd tot tijd kan het niet onvermijdelijk zijn dat MariaDB Cluster-versies nieuwe statistieken zullen produceren om de aard van het monitoren van de database te bewaken of te verbeteren door meer statusvariabelen te bieden en waarden te verfijnen om naar te kijken. Zoals ik hierboven heb vermeld, gebruik ik ClusterControl om mijn knooppunten in dit voorbeeldblog te controleren. Dat betekent echter niet dat het de beste tool is die er is. Ik bedoel, PMM van Percona is erg rijk als het gaat om collectieve monitoring voor elke statistische variabele. Wanneer MariaDB Cluster nieuwere statistische variabelen te bieden heeft, kun je dit gebruiken en ook wijzigen, aangezien PMM een open-source tool is. Het is een groot voordeel dat u ook alle zichtbaarheid van uw MariaDB-cluster hebt, aangezien elk aspect telt, vooral in een op productie gebaseerde database die honderdduizenden verzoeken per minuut kan verwerken.
Maar laten we hier wat specifieker ingaan op het probleem. Wat zijn deze statistische variabelen om naar te kijken? Er zijn er veel om op te rekenen voor een MariaDB-cluster, maar als we ons opnieuw concentreren op de functies en voordelen waarvan we denken dat u de MariaDB-cluster gebruikt wat het te bieden heeft, dan zullen we ons daarop concentreren.
Galera-cluster - stroomregeling
Het stroombeheer van uw MariaDB-cluster biedt u het overzicht van hoe de replicatiestatus op het hele cluster presteert. Het replicatieproces in Galera Cluster maakt gebruik van een feedbackmechanisme, wat betekent dat het alle knooppunten binnen dat cluster signaleert en aangeeft of het knooppunt de replicatie moet pauzeren of hervatten, afhankelijk van de behoeften. Dit voorkomt ook dat een knooppunt te ver achterblijft terwijl de anderen de inkomende transacties toepassen. Zo vervult de flow control zijn functie binnen Galera. Dit moet worden gezien en niet over het hoofd worden gezien bij het bewaken van uw MariaDB-cluster. Dit, zoals vermeld in een van de voordelen van het gebruik van MariaDB Cluster, is dat het vermijden van slaafvertragingen is. Hoewel dat te naïef is om de flow control en de slave-lag te begrijpen, maar met flow control zal het de prestaties van uw Galera-cluster beïnvloeden wanneer er veel wachtrijen zijn en commits of het wegspoelen van pagina's naar de schijf erg laag is voor dergelijke schijfproblemen of het is gewoon dat de query die wordt uitgevoerd een slechte query is. Als je een beginner bent met hoe Galera werkt, is het misschien interessant om dit externe bericht te lezen over wat flow control is in Galera.
Bytes verzonden/ontvangen
De verzonden of ontvangen bytes correleren met de netwerkactiviteit en is zelfs een van de belangrijkste gebieden om naast flow control te kijken. Hiermee kunt u bepalen welk knooppunt het meest wordt beïnvloed of wordt toegeschreven aan de prestatieproblemen die binnen uw Galera-cluster te lijden hebben. Het is erg belangrijk omdat u kunt controleren of er sprake kan zijn van degradatie in termen van hardware, zoals uw netwerkapparaat of het onderliggende opslagapparaat waarvoor het synchroniseren van vuile pagina's te veel tijd in beslag kan nemen.
Clusterbelasting
Nou, dit is meer de database-activiteit van hoeveel wijzigingen of het ophalen van gegevens er tot nu toe zijn opgevraagd of gedaan sinds de uptime van de server. Het helpt u uit te sluiten wat voor soort query's het meest van invloed zijn op de prestaties van uw databasecluster. Dit stelt u in staat om ruimte voor verbetering te bieden, met name bij het balanceren van de belasting van uw databaseverzoeken. Het gebruik van ProxySQL helpt u hier met een meer verfijnde en gedetailleerde benadering voor het routeren van query's. Hoewel MaxScale deze functie ook biedt, heeft ProxySQL meer granulariteit, hoewel het ook enige prestatie-impact of kosten heeft. Impact komt wanneer u slechts één ProxySQL als de SQL-proxy hebt om de queryrouting uit te werken en het kan moeite hebben wanneer er veel verkeer is. Met kosten, als u meer ProxySQL-knooppunten toevoegt om meer van het verkeer in evenwicht te brengen dat een onderliggend KeepAlived. Hoewel, dit is een perfecte combinatie, maar het kan tegen lage kosten worden uitgevoerd totdat het nodig is. Maar hoe kunt u bepalen of dat nodig is, toch? Dat is de vraag die hier blijft, dus een scherp oog voor het bewaken van deze belangrijke gebieden is erg belangrijk, niet alleen voor de waarneembaarheid, maar ook voor het verbeteren van de prestaties van uw databasecluster in de loop van de tijd.
Als zodanig zijn er talloze variabelen om naar te kijken in een MariaDB-cluster. Het belangrijkste waar je hier rekening mee moet houden is de tool die je gebruikt voor het monitoren van je databasecluster. Zoals eerder vermeld, gebruik ik liever de gratis versielicentie van ClusterControl (Community Edition) hier in deze blog, omdat het me meer manieren biedt om naar een Galera-cluster te kijken. Zie onderstaand voorbeeld,
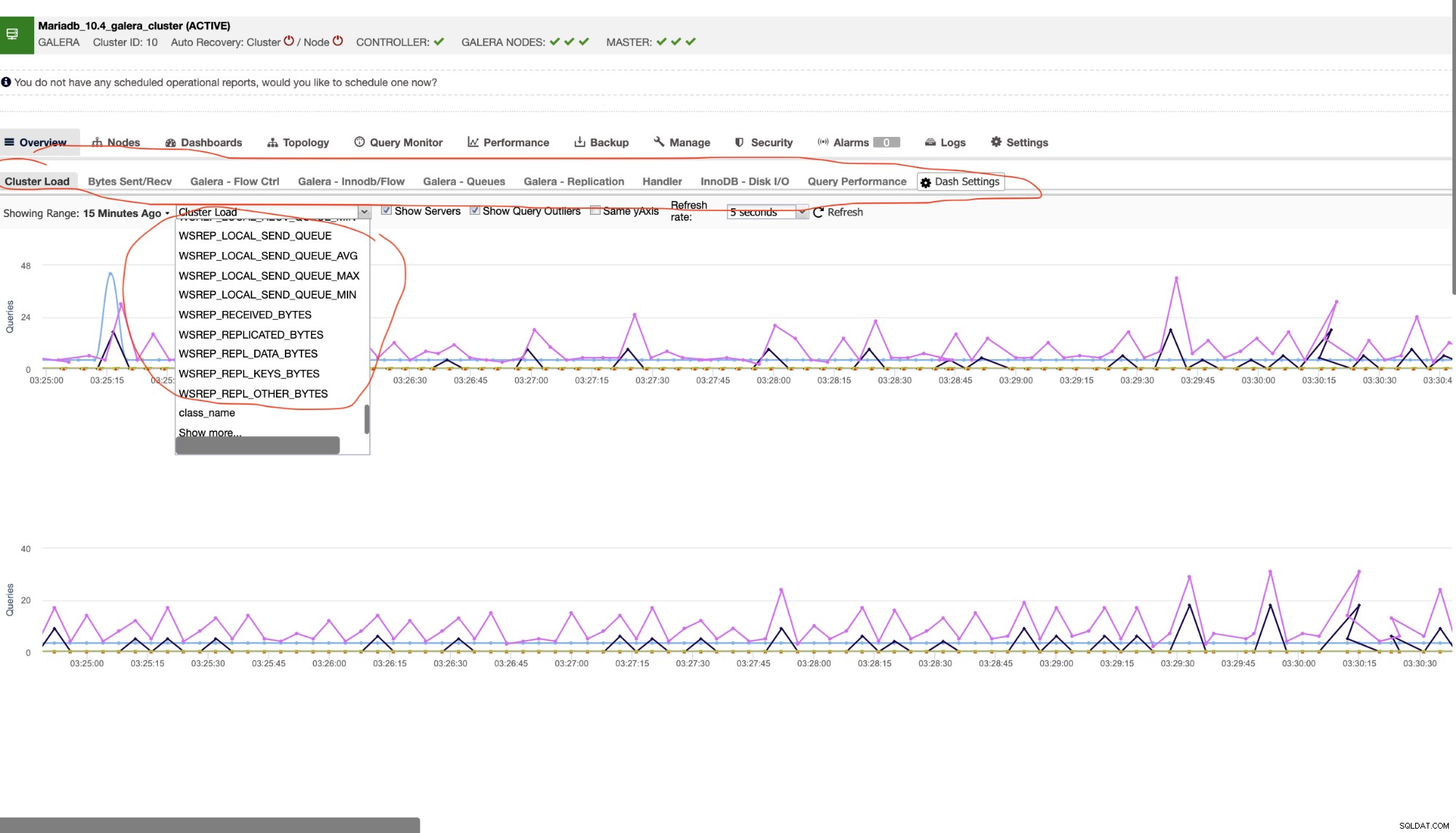
Ik heb die tabbladen rood gemarkeerd of omcirkeld waarmee ik visueel kan overzien de gezondheid van mijn MariaDB-cluster. Laten we zeggen dat als uw toepassing gretig is om van tijd tot tijd streaming-replicatie te gebruiken en een groot aantal fragmenten (grote netwerkoverdracht) verzendt voor clusterinteractiviteit, het het beste is om te bepalen hoe goed uw knooppunten de stress aankunnen. Vooral tijdens stresstests voordat specifieke wijzigingen in uw applicatie worden doorgevoerd, is het altijd het beste om te proberen en te testen om het capaciteitsbeheer van uw applicatieproduct te bepalen en te bepalen of uw huidige databaseknooppunten en ontwerp de belasting van uw applicatievereisten aankunnen.
Zelfs op een community-editie van de ClusterControl kan ik gedetailleerde en meer verfijnde resultaten verzamelen van de gezondheid van mijn MariaDB-cluster. Zie hieronder,
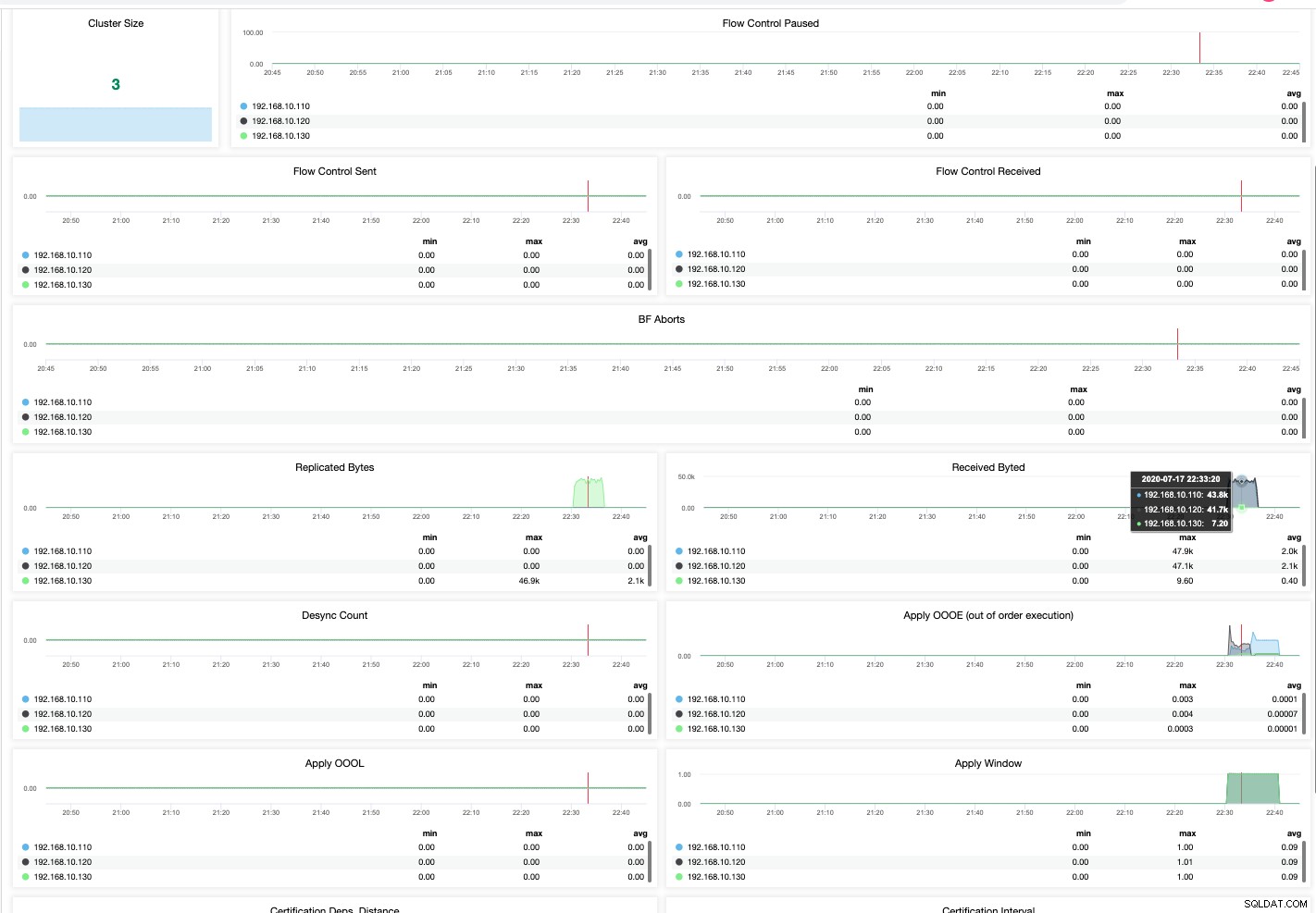
Dit is hoe u de monitoring van uw MariaDB-cluster aanpakt. Een perfecte visualisatie is altijd makkelijker en sneller te beheren. Als het mis gaat, kunt u het zich niet veroorloven uw productiviteit te verliezen en ook de uitvaltijd kan gevolgen hebben voor uw bedrijf. Hoewel gratis hebben u niet de luxe en het comfort biedt bij het beheren van databases met veel verkeer, is het hebben van alarmen, meldingen en databasebeheer in één gebied de add-ons die ClusterControl kan doen.
Conclusie
MariaDB Cluster is niet zo eenvoudig te controleren in vergelijking met de traditionele asynchrone MySQL/MariaDB master-slave-setups. Het werkt anders en je moet de juiste tools hebben om te bepalen wat er aan de hand is en wat er in je databasecluster gaat. Bereid altijd uw capaciteitsplanning voor voordat u uw MariaDB-cluster uitvoert zonder vooraf goede monitoring. Het is altijd het beste dat de belasting en activiteit van uw database bekend is voorafgaand aan een catastrofale gebeurtenis.