In onze vorige blogs hebben we uitgelegd waarom je een database-failover nodig hebt en hebben we uitgelegd hoe een failover-mechanisme werkt. Ik deel dit voor het geval je vragen hebt over waarom je een failover-mechanisme zou moeten opzetten voor je MySQL-database. Als je dat doet, lees dan onze eerdere blogposts.
Automatische failover instellen
Het voordeel van het gebruik van MySQL of MariaDB voor het automatisch beheren van uw failover is dat er tools beschikbaar zijn die u kunt gebruiken en implementeren in uw omgeving. Van open source-oplossingen tot enterprise-grade oplossingen. De meeste tools zijn niet alleen geschikt voor failover, er zijn ook andere functies zoals omschakeling, monitoring en geavanceerde functies die meer beheermogelijkheden kunnen bieden voor uw MySQL-databasecluster. Hieronder bespreken we de meest voorkomende die u kunt gebruiken.
MHA (Master High Availability) gebruiken
We hebben dit onderwerp besproken met MHA met de meest voorkomende problemen en hoe deze op te lossen. We hebben MHA ook vergeleken met MRM of met MaxScale.
Instellen met MHA voor hoge beschikbaarheid is misschien niet eenvoudig, maar het is efficiënt in gebruik en flexibel omdat er instelbare parameters zijn die u kunt definiëren om uw failover aan te passen. MHA is getest en gebruikt. Maar naarmate de technologie vordert, loopt MHA achterop omdat het GTID voor MariaDB niet ondersteunt en de afgelopen 2 of 3 jaar geen updates heeft gepusht.
Door het masterha_manager-script uit te voeren,
masterha_manager --conf=/etc/app1.cnfWaar een voorbeeld /etc/app1.cnf er als volgt uit zal zien,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parameters zoals no_master en candidate_master zijn cruciaal als u de gewenste knooppunten op de witte lijst instelt als uw doelmaster en knooppunten die u geen master wilt zijn.
Eenmaal ingesteld, bent u klaar voor een failover voor uw MySQL-database voor het geval er een storing op de primaire of master optreedt. Het script masterha_manager beheert de failover (automatisch of handmatig), neemt beslissingen over wanneer en waar de failover moet worden uitgevoerd en beheert slave-herstel tijdens de promotie van de kandidaat-master voor het toepassen van differentiële relaislogboeken. Als de masterdatabase uitvalt, coördineert MHA Manager met de MHA Node-agent, aangezien het differentiële relaislogboeken toepast op de slaves die niet de nieuwste binloggebeurtenissen van de master hebben.
Bekijk wat de MHA Node-agent doet en de bijbehorende scripts. Kortom, het is het script dat de MHA Manager zal aanroepen wanneer een failover optreedt. Het zal wachten op zijn mandaat van MHA Manager terwijl het zoekt naar de laatste slave die de binlog-gebeurtenissen bevat en ontbrekende gebeurtenissen van de slaaf kopieert met scp en deze op zichzelf toepast. Zoals vermeld, past het relaislogboeken toe, worden relaislogboeken gewist of binaire logboeken opgeslagen.
Als je meer wilt weten over afstembare parameters en hoe je je failover-beheer kunt aanpassen, ga dan naar de Parameters-wiki-pagina voor MHA.
Orchestrator gebruiken
Orchestrator is een MySQL- en MariaDB-tool voor hoge beschikbaarheid en replicatiebeheer. Het is uitgegeven door Shlomi Noach onder de voorwaarden van de Apache-licentie, versie 2.0. Dit is open source software en zorgt voor automatische failover, maar er zijn talloze dingen die u kunt aanpassen of doen om uw MySQL/MariaDB-database te beheren, afgezien van herstel of automatische failover.
Het installeren van Orchestrator kan eenvoudig of ongecompliceerd zijn. Nadat u de specifieke pakketten hebt gedownload die nodig zijn voor uw doelomgeving, bent u klaar om uw cluster en knooppunten te registreren om te worden gecontroleerd door Orchestrator. Het biedt een gebruikersinterface waarvoor dit zeer eenvoudig te beheren is, maar met veel instelbare parameters of een reeks opdrachten die u kunt gebruiken om uw failoverbeheer te realiseren.
Laten we er rekening mee houden dat u eindelijk het cluster hebt ingesteld en geregistreerd door ons primaire of hoofdknooppunt toe te voegen, kan worden gedaan met de onderstaande opdracht,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Nu hebben we ons cluster toegevoegd.
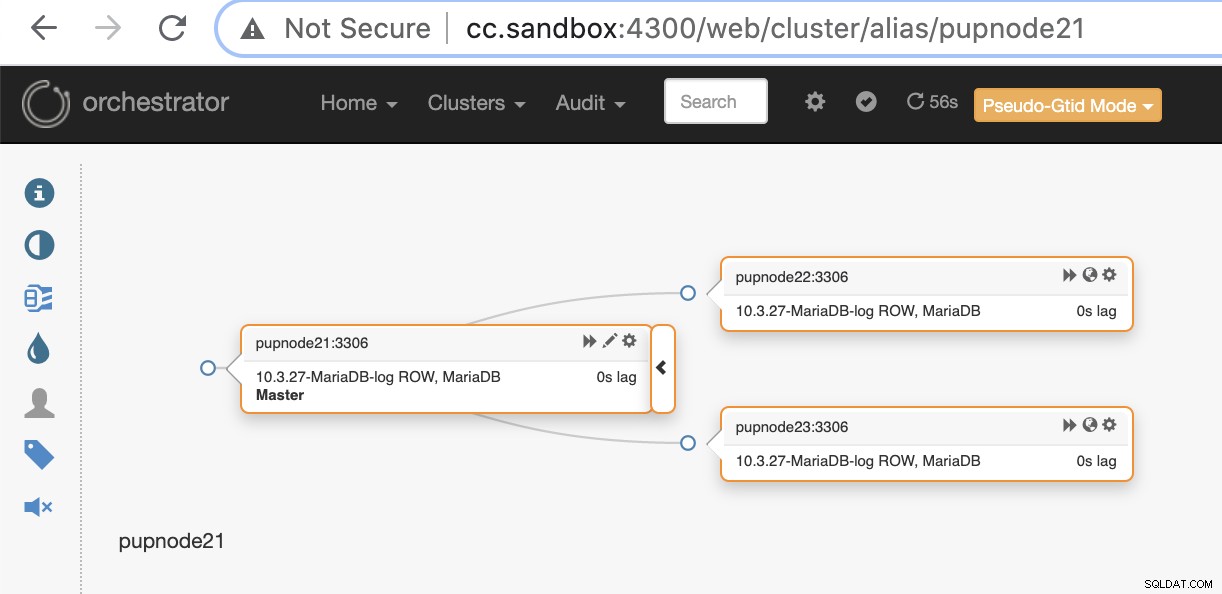
Als een primair knooppunt faalt (hardwarefout of vastgelopen), zal Orchestrator detecteer en vind het meest geavanceerde knooppunt dat moet worden gepromoot als het primaire of hoofdknooppunt.
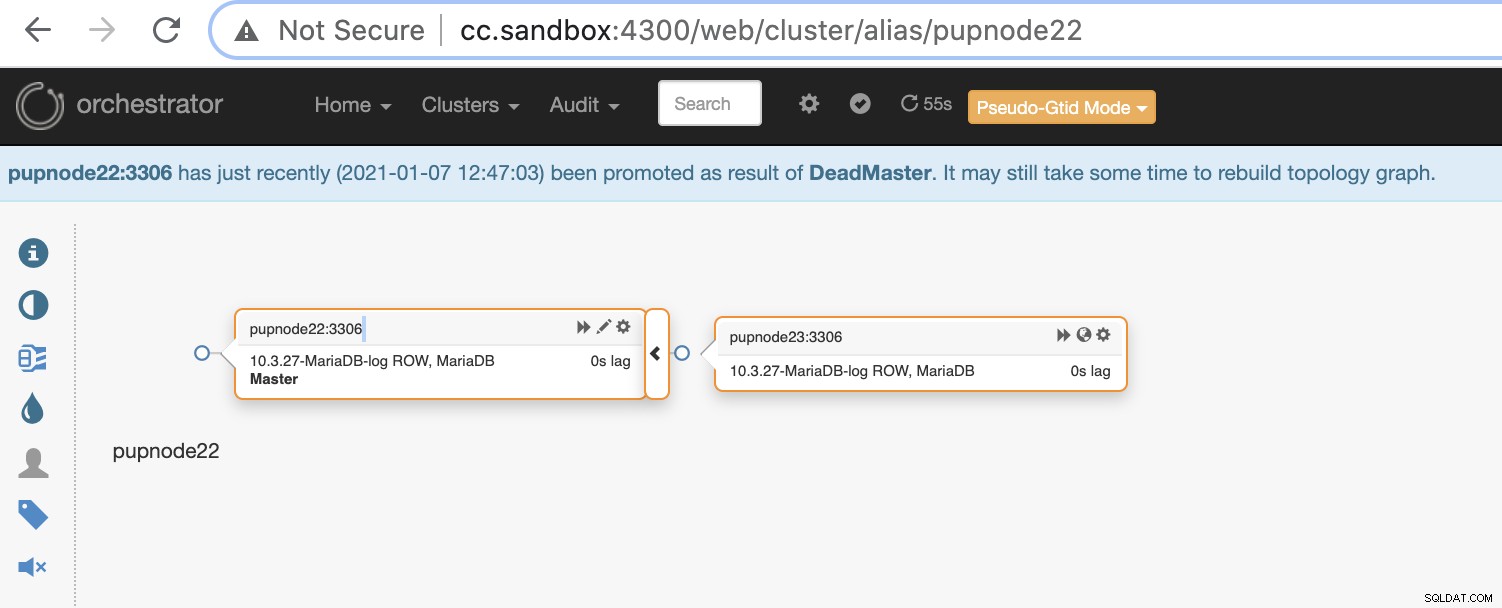
Nu hebben we nog twee nodes in het cluster terwijl de primaire niet beschikbaar is .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]MaxScale gebruiken
MariaDB MaxScale is ondersteund als load balancer voor databases. In de loop der jaren is MaxScale gegroeid en volwassener geworden, uitgebreid met verschillende rijke functies en dat omvat automatische failover. Sinds MariaDB MaxScale 2.2 is uitgebracht, introduceert het verschillende nieuwe functies, waaronder failoverbeheer van replicatieclusters. U kunt onze vorige blog over het MaxScale-failovermechanisme lezen.
Het gebruik van MaxScale valt onder BSL, hoewel de software vrij beschikbaar is, maar vereist dat je op zijn minst service koopt bij MariaDB. Het is misschien niet geschikt, maar als u MariaDB-bedrijfsservices hebt aangeschaft, kan dit een groot voordeel zijn als u failoverbeheer en de andere functies ervan nodig heeft.
De installatie van MaxScale is eenvoudig, maar het instellen van de vereiste configuratie en het definiëren van de parameters is dat niet, en het vereist dat u de software begrijpt. U kunt hun configuratiegids raadplegen.
Voor een snelle en snelle implementatie kunt u ClusterControl gebruiken om MaxScale voor u te installeren in uw bestaande MySQL/MariaDB-omgeving.
Na installatie kun je je Moodle-database instellen door je host naar het MaxScale IP-adres of de hostnaam en de lees-schrijfpoort te wijzen. Bijvoorbeeld,
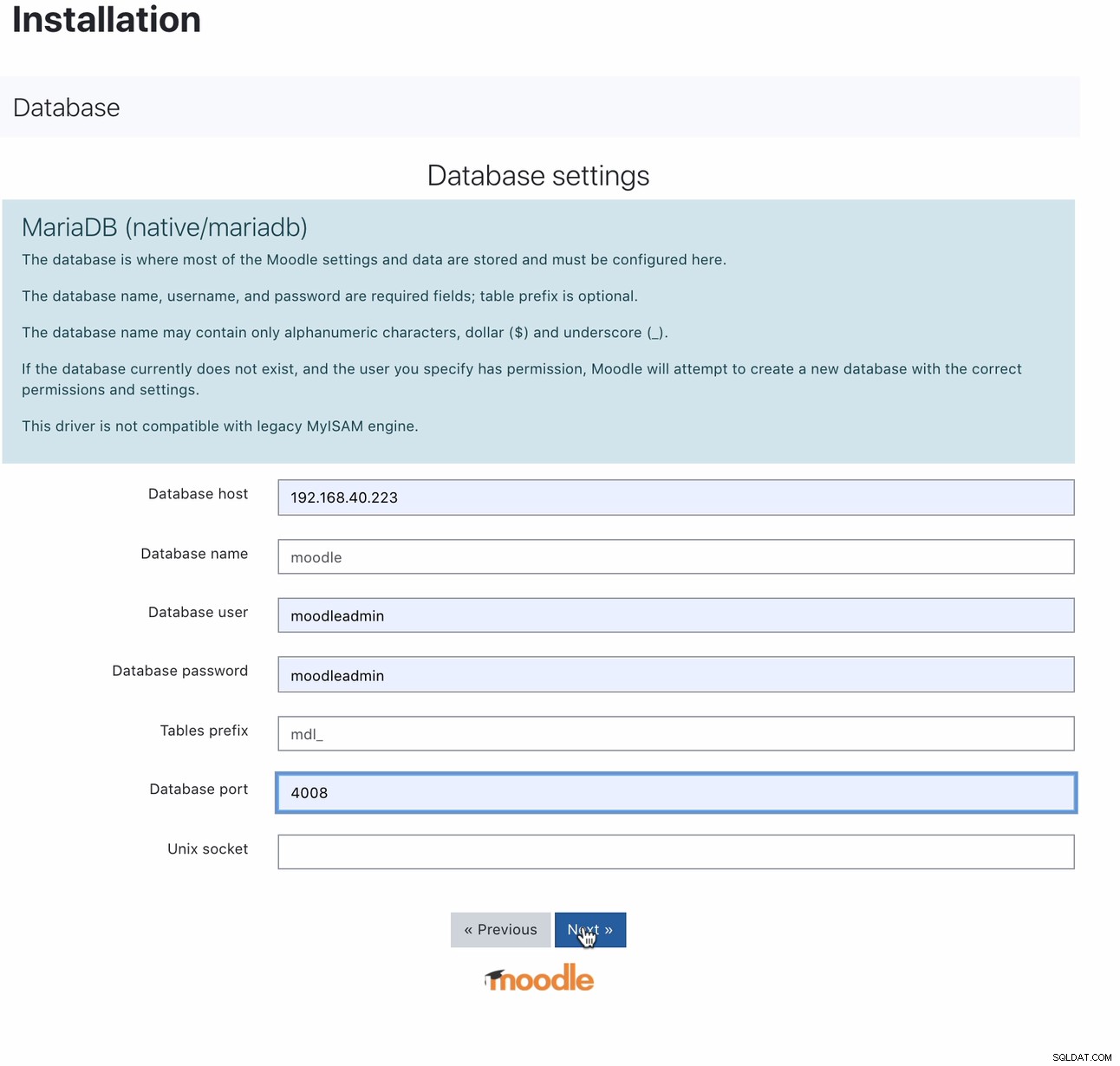
Voor welke poort 4008 uw lees-schrijffunctie is voor uw servicelistener. Hier is bijvoorbeeld de volgende service- en listenerconfiguratie voor mijn MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseTijdens je monitorconfiguratie moet je niet vergeten om de automatische failover in te schakelen of ook automatisch opnieuw deelnemen in te schakelen als je wilt dat de vorige master niet automatisch opnieuw deelneemt wanneer je weer online gaat. Het gaat als volgt,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Houd er rekening mee dat de variabelen die ik heb vermeld niet bedoeld zijn voor productiegebruik, maar alleen voor deze blogpost en testdoeleinden. Het goede van MaxScale is dat zodra de primary of master uitvalt, MaxScale slim genoeg is om de ideale of beste kandidaat te promoten om de rol van master op zich te nemen. Het is dus niet nodig om uw IP en poort te wijzigen, aangezien we de host/IP van ons MaxScale-knooppunt en zijn poort als ons eindpunt hebben gebruikt zodra de master uitvalt. Bijvoorbeeld,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Knooppunt DB_123 dat verwijst naar 192.168.40.221 is de huidige master. Het beëindigen van het knooppunt DB_123 zal MaxScale activeren om een failover uit te voeren en het zal er als volgt uitzien,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Terwijl onze Moodle-database nog steeds actief is, omdat onze MaxScale verwijst naar de nieuwste master die is gepromoot.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)ClusterControl gebruiken
ClusterControl kan gratis worden gedownload en biedt licenties voor Community, Advance en Enterprise. De automatische failover is alleen beschikbaar op Advance en Enterprise. Automatische failover valt onder onze Auto-Recovery-functie die probeert een mislukt cluster of een mislukt knooppunt te herstellen. Als u meer informatie wilt over hoe u dit kunt doen, bekijk dan ons vorige bericht Hoe ClusterControl automatisch databaseherstel en failover uitvoert. Het biedt afstembare parameters die erg handig en gebruiksvriendelijk zijn. Lees ook ons vorige bericht over het automatiseren van databasefailover met ClusterControl.
Het beheren van uw automatische failover voor uw Moodle-database moet ten minste een virtueel IP-adres (VIP) vereisen als uw eindpunt voor uw Moodle-toepassingsclient die uw database-backend verbindt. Om dit te doen, kunt u Keepalive implementeren met HAProxy (of ProxySQL - afhankelijk van uw keuze voor load balancer) er bovenop. In dit geval zal het eindpunt van je Moodle-database verwijzen naar het virtuele IP-adres, dat in feite wordt toegewezen door Keepalive nadat je het hebt geïmplementeerd, net zoals we je eerder hebben laten zien bij het instellen van MaxScale. Je kunt ook op deze blog lezen hoe je dit moet doen.
Zoals hierboven vermeld, zijn er afstembare parameters beschikbaar die u kunt instellen via uw /etc/cmon.d/cmon_
- replication_check_binlog_filtratie_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replicatie_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl is zeer flexibel bij het beheren van de failover, zodat u enkele pre-failover- of post-failover-taken kunt uitvoeren.
Conclusie
Er zijn andere geweldige keuzes bij het instellen en automatisch beheren van uw failover voor uw MySQL-database voor Moodle. Het hangt af van uw budget en waar u waarschijnlijk geld aan uitgeeft. Het gebruik van open source vereist expertise en vereist meerdere tests om vertrouwd te raken, aangezien er geen ondersteuning is die u kunt uitvoeren wanneer u andere hulp nodig heeft dan de community. Met enterprise-oplossingen heeft het een prijs, maar biedt u ondersteuning en gemak omdat het tijdrovende werk kan worden verminderd. Houd er rekening mee dat als failover per ongeluk wordt gebruikt, dit schade aan uw database kan kosten als deze niet op de juiste manier wordt behandeld en beheerd. Concentreer u op wat belangrijker is en hoe u in staat bent tot de oplossingen die u gebruikt voor het beheren van uw Moodle-database-failover.