Het bijhouden van wijzigingen in uw databaseschema in MySQL/MariaDB biedt een enorme hulp omdat het tijd bespaart bij het analyseren van uw databasegroei, wijzigingen in tabeldefinities, gegevensgrootte, indexgrootte of rijgrootte. Voor MySQL/MariaDB levert het uitvoeren van een query die verwijst naar information_schema samen met performance_schema collectieve resultaten op voor verdere analyse. Het sys-schema biedt u weergaven die dienen als collectieve statistieken die erg handig zijn voor het volgen van databasewijzigingen of -activiteit.
Als je veel databaseservers hebt, zou het vervelend zijn om de hele tijd een query uit te voeren. Je moet dat resultaat ook verwerken tot een leesbaarder en gemakkelijker te begrijpen resultaat.
In deze blog zullen we een automatisering maken die nuttig zou kunnen zijn als hulpprogramma voor het bewaken van uw bestaande database en het verzamelen van statistieken met betrekking tot databasewijzigingen of bewerkingen voor schemawijzigingen.
Automatisering maken voor controle van databaseschema-objecten
In deze oefening zullen we de volgende statistieken controleren:
-
Geen primaire sleuteltabellen
-
Dubbele indexen
-
Genereer een grafiek voor het totale aantal rijen in onze databaseschema's
-
Genereer een grafiek voor de totale grootte van onze databaseschema's
Deze oefening geeft je een seintje en kan worden aangepast om meer geavanceerde statistieken te verzamelen uit je MySQL/MariaDB-database.
Puppet gebruiken voor onze IaC en automatisering
Deze oefening gebruikt Puppet om automatisering te bieden en de verwachte resultaten te genereren op basis van de statistieken die we willen controleren. We gaan niet in op de installatie en configuratie van de Puppet, inclusief server en client, dus ik verwacht dat je weet hoe je Puppet moet gebruiken. Misschien wil je onze oude blog Geautomatiseerde implementatie van MySQL Galera Cluster naar Amazon AWS met Puppet bezoeken, waarin de installatie en installatie van Puppet wordt behandeld.
We gebruiken de nieuwste versie van Puppet in deze oefening, maar aangezien onze code uit basissyntaxis bestaat, zou deze ook voor oudere versies van Puppet kunnen worden uitgevoerd.
Voorkeur MySQL-databaseserver
In deze oefening zullen we Percona Server 8.0.22-13 gebruiken, aangezien ik Percona Server vooral prefereer voor testen en enkele kleine implementaties, zowel zakelijk als persoonlijk.
Grafische tool
Er zijn talloze opties om te gebruiken, vooral in de Linux-omgeving. In deze blog gebruik ik de gemakkelijkste die ik heb gevonden en een opensource-tool https://quickchart.io/.
Laten we met marionet spelen
De veronderstelling die ik hier heb gemaakt, is dat je een masterserver hebt ingesteld met een geregistreerde client die klaar is om te communiceren met de masterserver om automatische implementaties te ontvangen.
Voordat we verder gaan, is hier de informatie over mijn server:
Hoofdserver:192.168.40.200
Client/Agent-server:192.168.40.160
In deze blog is onze client/agent-server waar onze databaseserver draait. In een realistisch scenario hoeft dit niet speciaal voor monitoring te zijn. Zolang het in staat is om veilig met het doelknooppunt te communiceren, is dat ook een perfecte opstelling.
De module en de code instellen
-
Ga naar de hoofdserver en in het pad /etc/puppetlabs/code/environments/production/module, laten we de vereiste mappen voor deze oefening maken:
mkdir schema_change_mon/{files,manifests}
-
Maak de bestanden die we nodig hebben
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Vul het init.pp-script met de volgende inhoud:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Vul het bestand graphing_gen.sh in. Dit script wordt uitgevoerd op het doelknooppunt en genereert grafieken voor het totale aantal rijen in onze database en ook voor de totale grootte van onze database. Laten we het voor dit script eenvoudiger maken en alleen MyISAM- of InnoDB-type databases toestaan.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Ga ten slotte naar de modulepadmap of /etc/puppetlabs/code/environments /productie in mijn opstelling. Laten we het bestand manifests/schema_change_mon.pp maken.
touch manifests/schema_change_mon.pp-
Vul vervolgens het bestand manifests/schema_change_mon.pp met de volgende inhoud,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Als je klaar bent, zou je de volgende boomstructuur moeten hebben, net als de mijne,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppWat doet onze module?
Onze module genaamd schema_change_mon verzamelt het volgende,
exec { "mysql-without-primary-key" :...
Die een mysql-opdracht uitvoert en een query uitvoert om tabellen zonder primaire sleutels op te halen. Dan,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :die wel dubbele indexen verzamelt die in de databasetabellen voorkomen.
Vervolgens genereren de lijnen grafieken op basis van de verzamelde statistieken. Dit zijn de volgende regels,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Zodra de query met succes is uitgevoerd, wordt de grafiek gegenereerd, die afhankelijk is van de API die wordt geleverd door https://quickchart.io/.
Hier zijn de volgende resultaten van de grafiek:
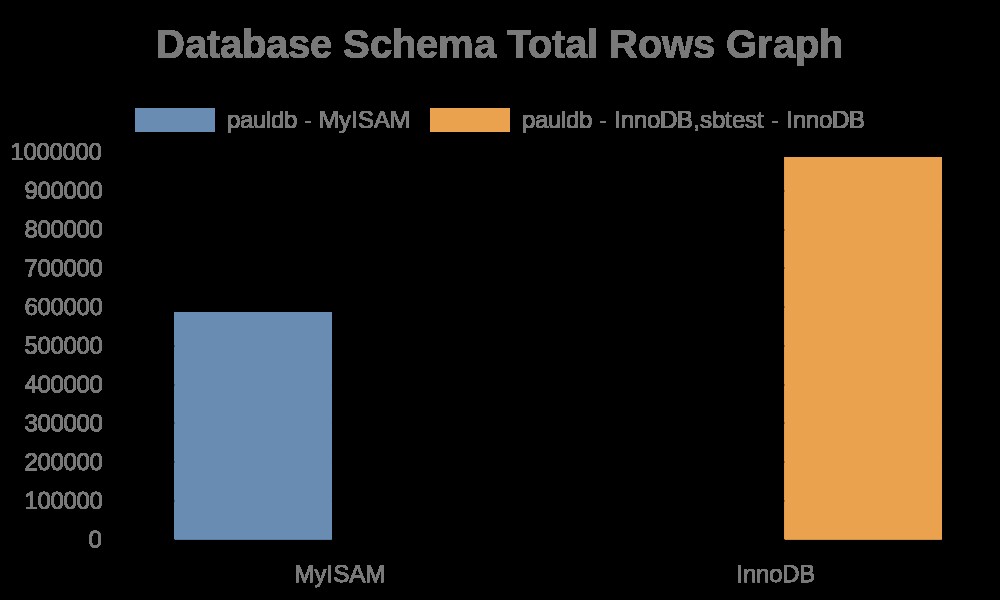
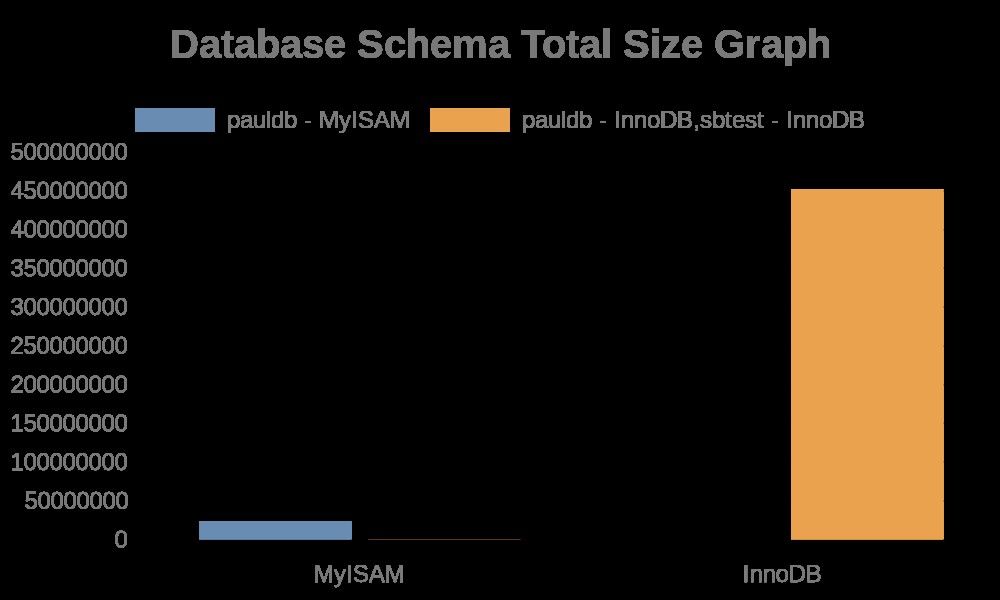
Terwijl de bestandslogboeken gewoon strings bevatten met de tabelnamen, indexnamen. Zie het resultaat hieronder,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBWaarom ClusterControl niet gebruiken?
Omdat onze oefening de automatisering en het verkrijgen van de databaseschemastatistieken zoals wijzigingen of bewerkingen laat zien, biedt ClusterControl dit ook. Afgezien hiervan zijn er nog andere functies en u hoeft het wiel niet opnieuw uit te vinden. ClusterControl kan de transactielogboeken leveren, zoals deadlocks zoals hierboven weergegeven, of langlopende zoekopdrachten zoals hieronder weergegeven:
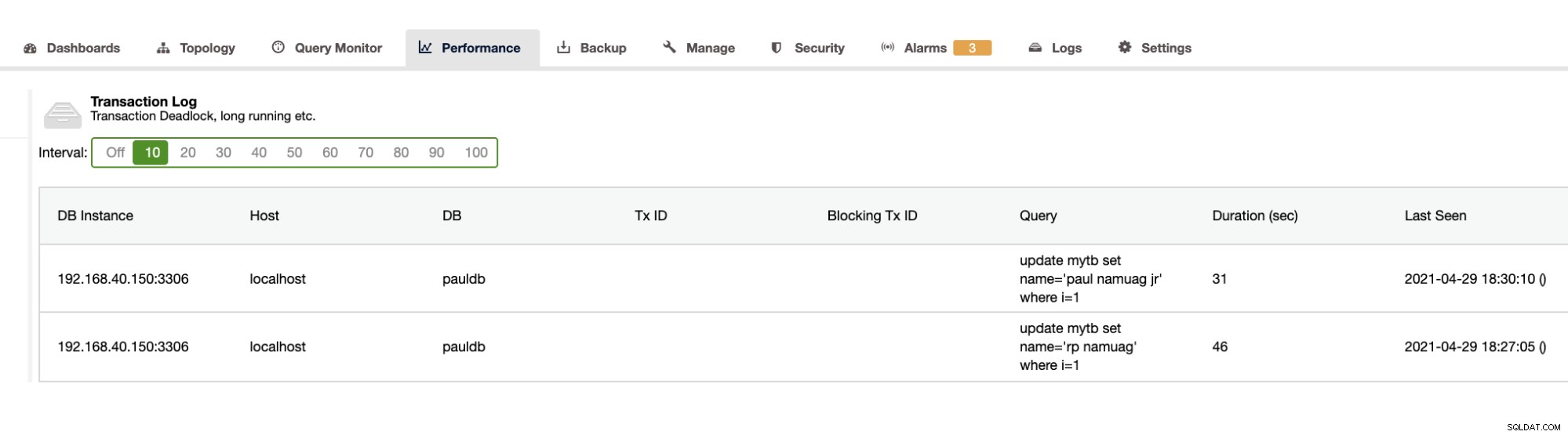
ClusterControl toont ook de DB-groei zoals hieronder getoond,
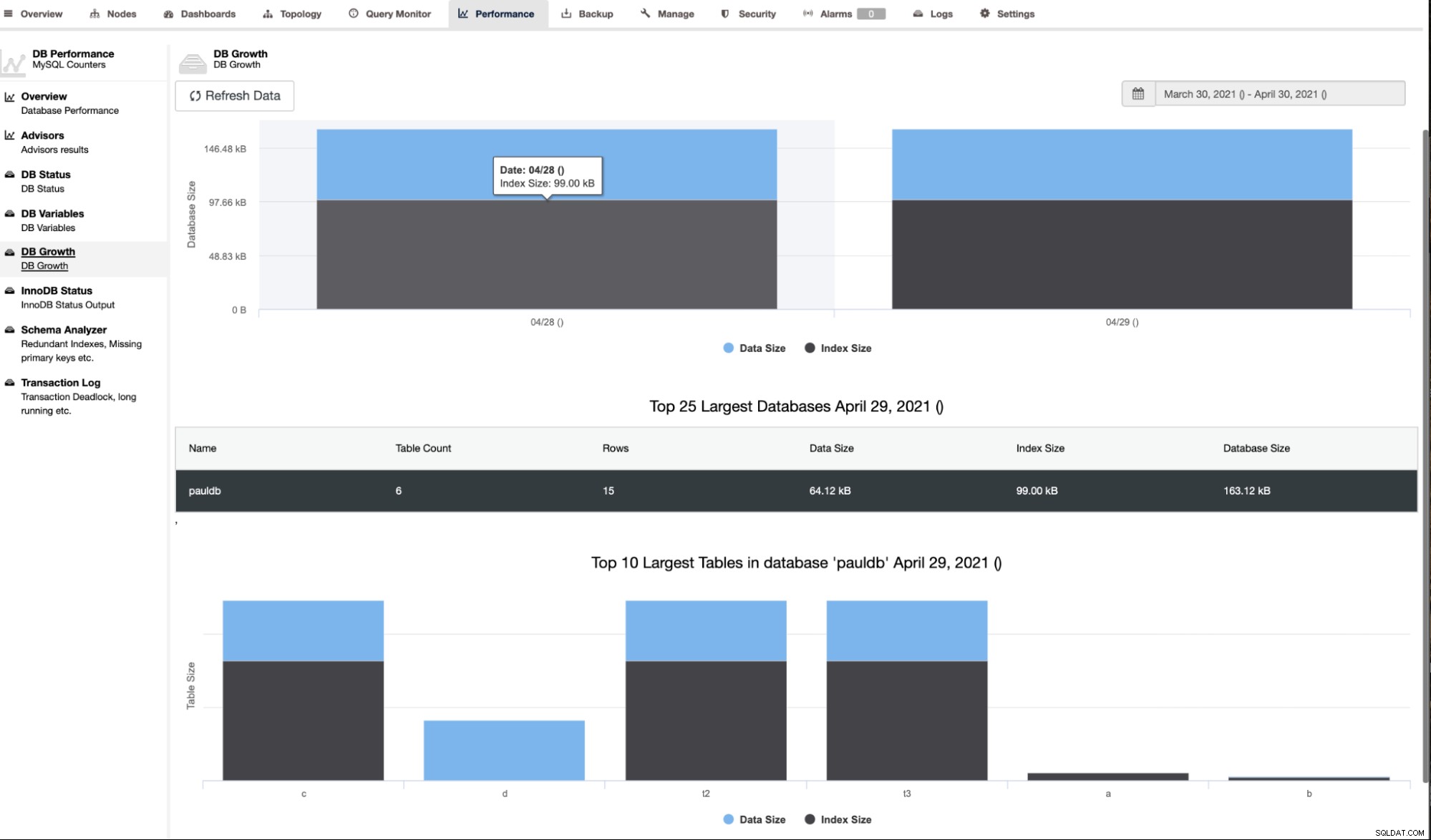
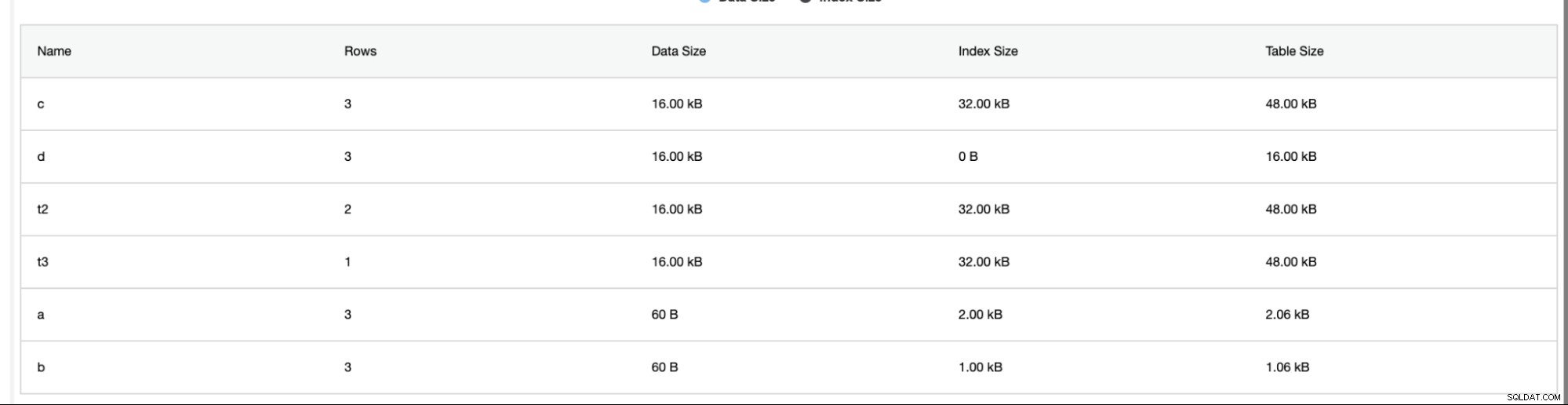
ClusterControl geeft ook aanvullende informatie zoals het aantal rijen, schijfgrootte, indexgrootte en totale grootte.
De schema-analysator onder het tabblad Prestaties -> Schema-analysator is erg handig. Het biedt tabellen zonder primaire sleutels, MyISAM-tabellen en dubbele indexen,

Het biedt ook alarmen voor het geval er dubbele indexen of tabellen worden gedetecteerd zonder primaire toetsen zoals hieronder,

U kunt meer informatie over ClusterControl en de andere functies bekijken op onze productpagina.
Conclusie
Automatisering bieden voor het bewaken van uw databasewijzigingen of schemastatistieken zoals schrijven, dubbele indexen, bewerkingsupdates zoals DDL-wijzigingen en veel database-activiteiten is zeer gunstig voor de DBA's. Het helpt om snel de zwakke links en problematische zoekopdrachten te identificeren die u een overzicht zouden geven van een mogelijke oorzaak van slechte zoekopdrachten die uw database zouden blokkeren of uw database zouden verouderen.