Weten op welke van de kolommen u wilt groeperen en hoe u ze wilt groeperen, is allereerst belangrijk. U moet dat weten om de CASE STATEMENT in te stellen we gaan schrijven als een kolom in een onze select-verklaring. In ons geval, in een groep e-mails die onze site bezoeken, willen we weten hoeveel klikken elke e-mailprovider heeft sinds begin augustus. We willen ook een individuele e-mailserviceprovider vergelijken met de rest. Voor dit voorbeeld gaan we Gmail gebruiken als onze serviceprovider.
In onze SELECT statement, hebben we de DATE . nodig , de AANBIEDER en de SOM van de KLIKKEN naar onze site. We kunnen deze krijgen van de TEST E MAILS tabel in onze gegevensbron.
De DATUM kolom is vrij eenvoudig:
"Test E Mails"."Created_Date" AS "DATE
En aangezien we op zoek zijn naar de SUM van de KLIKKEN , moeten we een SUM casten functie via de KLIKKEN kolom.
SUM("Test E Mails"."Clicks") AS "CLICKS"
Dat brengt ons bij onze CASE STATEMENT . We weten uit de PostgreSQL-documentatie dat een CASE STATEMENT, of een voorwaardelijke verklaring, op de volgende manier moet worden gerangschikt:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Onze eerste en in dit geval enige voorwaarde is dat we willen weten dat alle e-mailadressen die door Gmail worden verstrekt, gescheiden zijn van elke andere e-mailprovider. Dus de enige WHEN is:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
En de else-verklaring zou 'Overig' zijn voor elke andere e-mailadresprovider. De resulterende tabel van deze CASE STATEMENT alleen met bijbehorende e-mails. Zou er zo uitzien:
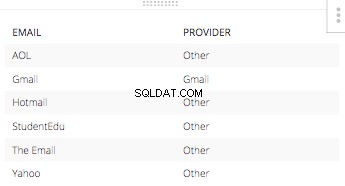
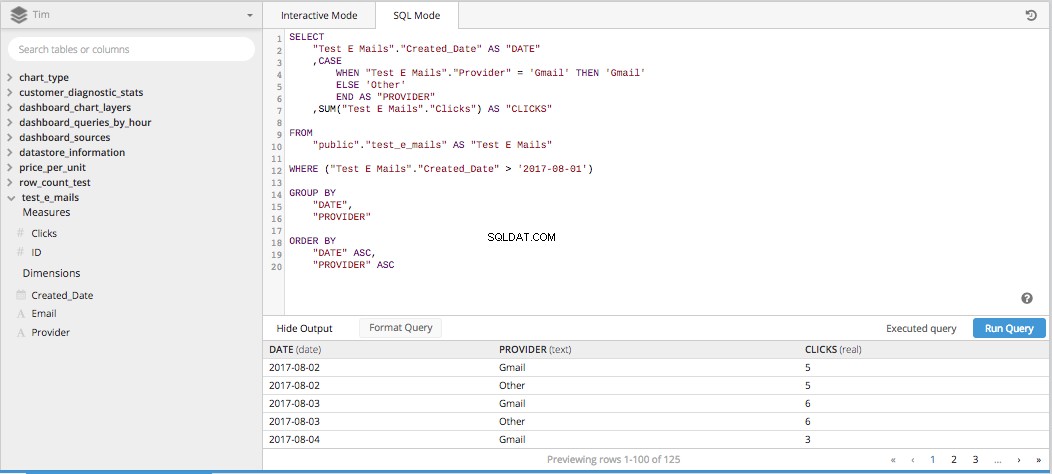
Als je alle drie die kolommen samenvoegt voor één SELECTEER STATEMENT en gooi de rest van de benodigde stukjes erin om een SQL-query te bouwen, het krijgt allemaal hieronder vorm.
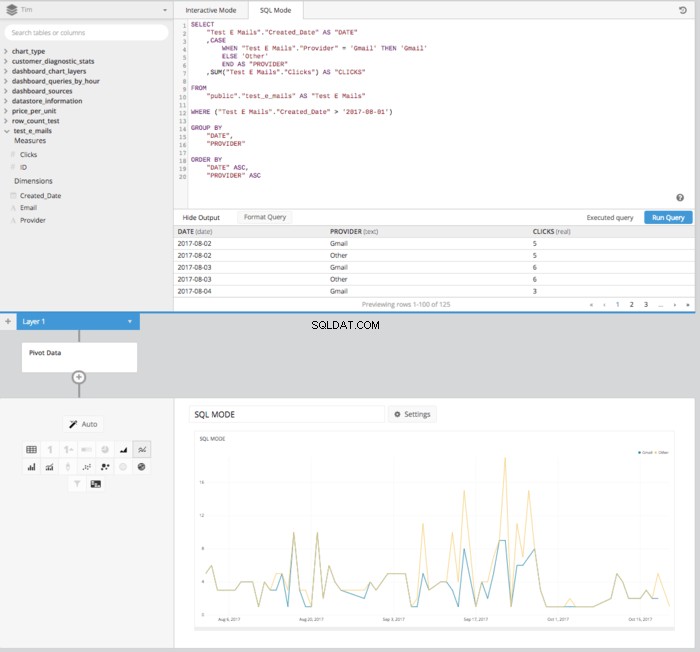
Na het toevoegen van een PIVOT DATA stap in de gegevenspijplijn, we krijgen een tabel die goed is gerangschikt in de juiste indeling om een lijndiagram op te zetten dat laat zien hoe klikken in de loop van de tijd worden vergeleken.
Door Chartio te gebruiken, kunnen we al het bovenstaande doen zonder enige SQL te schrijven, maar door gebruik te maken van de Data Explorer en de Data Pipeline-functies. Nadat we onze onderliggende query hebben gemaakt om alle kolommen op te halen, hebben we SUM OF CLICKS nodig , DATUM en EMAILADRES we kunnen de gegevenspijplijn gebruiken om deze gegevens na SQL te manipuleren. Laten we eerst de query maken.
Sleep de 'Klikkolom' naar het meetvenster en aggregeer het met TOTAL SUM van de kolomklikken en hernoem het vervolgens 'KLIKKEN'.
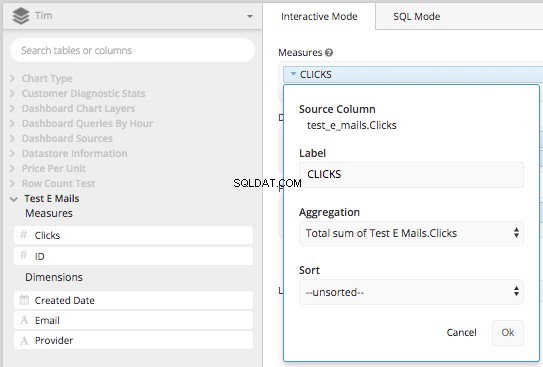
Sleep vervolgens 'Datum gemaakt' en 'Provider' naar het dimensievak en label ze opnieuw 'Datum' en 'E-mailprovider'. Daarna kunt u met behulp van de kolom 'Aangemaakte datum' de periode instellen (of uw WAAR clausule) om alles te zijn na 01-08-2017. Dit zal effectief alles bouwen wat we nodig hebben in een onderliggende query om de CASE STATEMENT te maken we hebben het hierboven gedaan, in Chartio's Data Pipeline.
Een CASE STATEMENT toevoegen pijplijnstap stelt ons in staat om de voorwaarden in te stellen voor de WHEN en de ELSE net zoals we eerder deden, zonder de hele SQL-syntaxis in te hoeven typen.
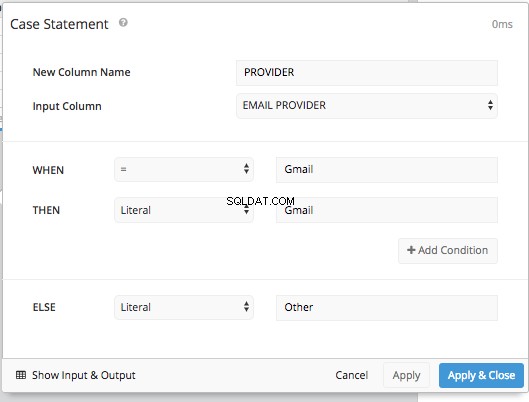
Na het verbergen van de originele kolom 'Provider' en het gebruik van een HERORDER KOLOMMEN stap en een PIVOT DATA stap krijgen we dezelfde tabelindeling als in SQL-modus en kunnen we dezelfde tabel presenteren als in SQL-modus.
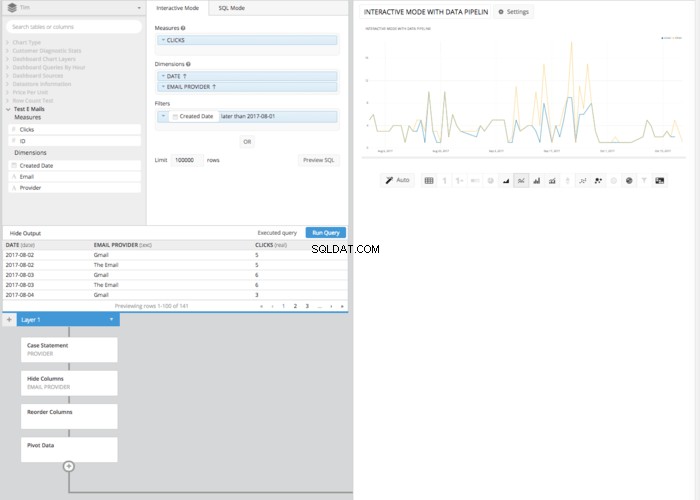
Hoewel het wat meer klikken en stappen kan vergen dan in de SQL-modus, vereist het resulterende lijndiagram in de interactieve modus geen kennis van SQL-syntaxis. In plaats daarvan is alleen een basiskennis van de betrokken principes nodig. Dit is weer een voorbeeld van hoe Chartio helpt om de kracht van data in ieders handen te krijgen, ongeacht SQL-kennis.