U weet waarschijnlijk hoe u records in een tabel moet invoegen met behulp van enkele of meerdere VALUES-clausules. Je weet ook hoe je bulk-inserts moet doen met SQL INSERT INTO SELECT. Maar je klikte toch op het artikel. Gaat het om het omgaan met duplicaten?
Veel artikelen hebben betrekking op SQL INSERT INTO SELECT. Google of Bing het en kies de kop die je het leukst vindt - het is voldoende. Ik zal ook geen basisvoorbeelden behandelen van hoe het wordt gedaan. In plaats daarvan zul je voorbeelden zien van hoe je het kunt gebruiken EN tegelijkertijd duplicaten kunt verwerken . U kunt dus deze bekende boodschap maken van uw INSERT-inspanningen:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Maar eerst.

[sendpulse-form id=”12989″]
Bereid testgegevens voor SQL INSERT INTO SELECT Code Samples
Ik denk deze keer een beetje aan pasta. Dus ik gebruik gegevens over pastagerechten. Ik vond een goede lijst met pastagerechten op Wikipedia die we kunnen gebruiken en extraheren in Power BI met behulp van een webgegevensbron. Ik heb de Wikipedia-URL ingevoerd. Vervolgens heb ik de 2-tabelgegevens van de pagina gespecificeerd. Heb het een beetje opgeschoond en gegevens naar Excel gekopieerd.
Nu hebben we de gegevens - u kunt deze hier downloaden. Het is rauw omdat we er 2 relationele tabellen van gaan maken. Het gebruik van INSERT INTO SELECT zal ons helpen deze taak uit te voeren,
De gegevens importeren in SQL Server
U kunt SQL Server Management Studio of dbForge Studio voor SQL Server gebruiken om 2 bladen in het Excel-bestand te importeren.
Maak een lege database voordat u de gegevens importeert. Ik noemde de tabellen dbo.ItalianPastaDishes en dbo.NonItalianPastaDishes .
Maak nog 2 tabellen
Laten we de twee uitvoertabellen definiëren met het commando SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Opmerking:er zijn unieke indexen gemaakt op twee tabellen. Het voorkomt dat we later dubbele records invoegen. Beperkingen maken deze reis een beetje moeilijker maar spannend.
Nu we er klaar voor zijn, gaan we erin duiken.
5 eenvoudige manieren om duplicaten te verwerken met SQL INSERT INTO SELECT
De gemakkelijkste manier om met duplicaten om te gaan, is door unieke beperkingen te verwijderen, toch?
Verkeerd!
Nu de unieke beperkingen zijn verdwenen, is het gemakkelijk om een fout te maken en de gegevens twee keer of vaker in te voeren. Wij willen dat niet. En wat als we een gebruikersinterface hebben met een vervolgkeuzelijst om de oorsprong van de pastaschotel te kiezen? Zullen de duplicaten uw gebruikers blij maken?
Daarom is het verwijderen van de unieke beperkingen niet een van de vijf manieren om dubbele records in SQL af te handelen of te verwijderen. We hebben betere opties.
1. INSERT INTO SELECT DISTINCT gebruiken
De eerste optie voor het identificeren van SQL-records in SQL is om DISTINCT te gebruiken in uw SELECT. Om de zaak te onderzoeken, vullen we de Origin tafel. Maar laten we eerst de verkeerde methode gebruiken:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Dit zal de volgende dubbele fouten veroorzaken:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Er is een probleem wanneer u dubbele rijen in SQL probeert te selecteren. Om de SQL-controle op duplicaten te starten die eerder bestonden, heb ik het SELECT-gedeelte van de INSERT INTO SELECT-instructie uitgevoerd:
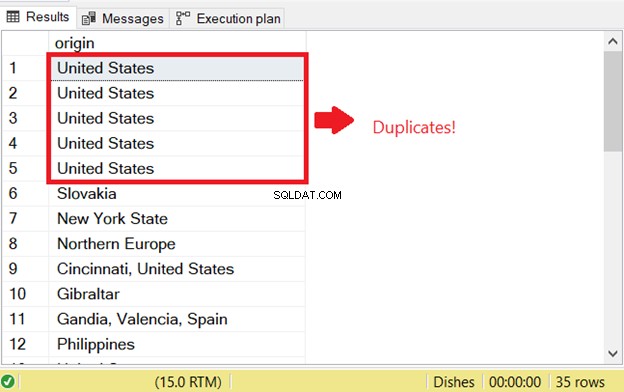
Dat is de reden voor de eerste SQL-duplicaatfout. Om dit te voorkomen, voegt u het sleutelwoord DISTINCT toe om de resultatenset uniek te maken. Dit is de juiste code:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Het voegt de records met succes in. En we zijn klaar met de Origin tafel.
Door DISTINCT te gebruiken, worden unieke records gemaakt van de SELECT-instructie. Het garandeert echter niet dat er geen duplicaten in de doeltabel voorkomen. Het is goed als u zeker weet dat de doeltabel niet de waarden heeft die u wilt invoegen.
Voer deze instructies dus niet meer dan één keer uit.
2. WHERE NOT IN
. gebruikenVervolgens vullen we de PastaDishes tafel. Daarvoor moeten we eerst records invoegen uit de ItalianPastaDishes tafel. Hier is de code:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Sinds ItalianPastaDishes onbewerkte gegevens bevat, moeten we deelnemen aan de Origin tekst in plaats van de OriginID . Probeer nu dezelfde code twee keer uit te voeren. De tweede keer dat het wordt uitgevoerd, worden er geen records ingevoegd. Het gebeurt vanwege de WHERE-component met de NOT IN-operator. Het filtert records die al bestaan in de doeltabel.
Vervolgens moeten we de PastaDishes . invullen tabel uit de NonItalianPastaDishes tafel. Aangezien we pas op het tweede punt van dit bericht zijn, zullen we niet alles invoegen.
We kozen pastagerechten uit de Verenigde Staten en de Filippijnen. Hier gaat het:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Er zijn 9 records ingevoegd uit deze verklaring – zie Afbeelding 2 hieronder:
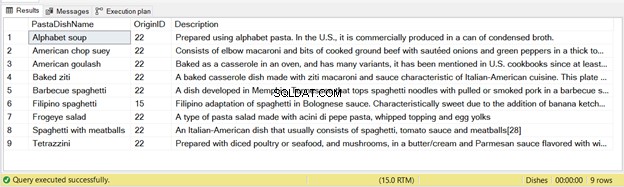
Nogmaals, als je de bovenstaande code twee keer uitvoert, worden er bij de tweede keer geen records ingevoegd.
3. Met behulp van WHERE NOT BESTAAT
Een andere manier om duplicaten in SQL te vinden, is door NOT EXISTS te gebruiken in de WHERE-component. Laten we het proberen met dezelfde voorwaarden als in de vorige sectie:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
De bovenstaande code voegt dezelfde 9 records in die u in Afbeelding 2 zag. Het voorkomt dat dezelfde records meer dan één keer worden ingevoegd.
4. ALS NIET BESTAAT gebruiken
Soms moet u een tabel in de database implementeren en moet u controleren of er al een tabel met dezelfde naam bestaat om duplicaten te voorkomen. In dit geval kan de opdracht SQL DROP TABLE IF EXISTS een grote hulp zijn. Een andere manier om ervoor te zorgen dat u geen duplicaten invoegt, is door IF NOT EXISTS te gebruiken. Nogmaals, we zullen dezelfde voorwaarden uit de vorige sectie gebruiken:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
De bovenstaande code controleert eerst op het bestaan van 9 records. Als het true retourneert, gaat INSERT verder.
5. COUNT(*) =0 gebruiken
Ten slotte kan het gebruik van COUNT(*) in de WHERE-component er ook voor zorgen dat u geen duplicaten invoegt. Hier is een voorbeeld:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Om duplicaten te voorkomen, moet het COUNT of de records die door de bovenstaande subquery worden geretourneerd, nul zijn.
Opmerking :U kunt elke query visueel in een diagram ontwerpen met de functie Query Builder van dbForge Studio voor SQL Server.
Vergelijking van verschillende manieren om duplicaten te verwerken met SQL INSERT INTO SELECT
4 secties gebruikten dezelfde uitvoer maar verschillende benaderingen om bulkrecords in te voegen met een SELECT-instructie. Je kunt je afvragen of het verschil alleen aan de oppervlakte zit. We kunnen hun logische waarden van STATISTICS IO controleren om te zien hoe verschillend ze zijn.
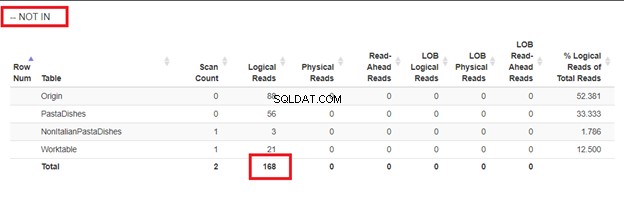
WHERE NOT IN gebruiken:
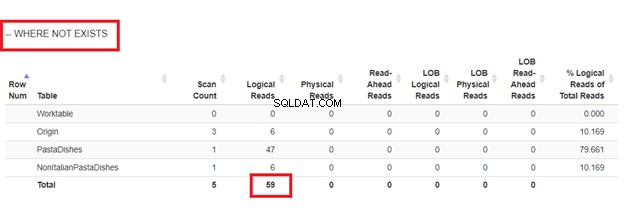
Met NOT EXISTS:
Met IF NOT EXISTS:
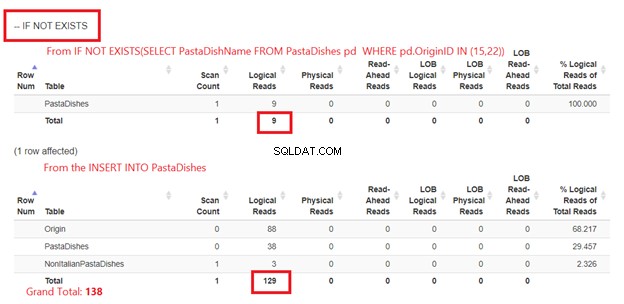
Figuur 5 is een beetje anders. Er verschijnen 2 logische waarden voor de PastaDishes tafel. De eerste is van IF NOT EXISTS(SELECT PastaDishName van PastaDishes WAAR OriginID IN (15,22)). De tweede komt uit de INSERT-instructie.
Gebruik tenslotte COUNT(*) =0
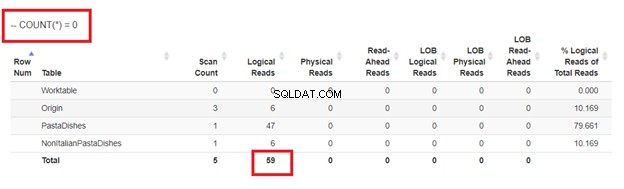
Uit de logische lezing van 4 benaderingen die we hadden, is de beste keuze WHERE NOT EXISTS of COUNT(*) =0. Wanneer we hun uitvoeringsplannen inspecteren, zien we dat ze hetzelfde QueryHashPlan hebben . Ze hebben dus vergelijkbare plannen. Ondertussen gebruikt de minst efficiënte NOT IN.
Betekent dit dat WHERE NOT EXISTS altijd beter is dan NOT IN? Helemaal niet.
Inspecteer altijd de logische uitlezingen en het uitvoeringsplan van uw vragen!
Maar voordat we besluiten, moeten we de taak afmaken. Daarna voegen we de rest van de records toe en inspecteren we de resultaten.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Het bladeren door de lijst met 179 pastagerechten van Azië tot Europa maakt me hongerig. Bekijk hieronder een deel van de lijst uit Italië, Rusland en meer:

Conclusie
Het vermijden van duplicaten in SQL INSERT INTO SELECT is toch niet zo moeilijk. Je hebt operators en functies bij de hand om je naar dat niveau te brengen. Het is ook een goede gewoonte om het Uitvoeringsplan te controleren en logische uitlezingen om te vergelijken welke beter is.
Als je denkt dat iemand anders baat heeft bij dit bericht, deel het dan op je favoriete sociale mediaplatforms. En als je iets toe te voegen hebt dat we zijn vergeten, laat het ons dan weten in het gedeelte Opmerkingen hieronder.