Typische zoekopdrachten in de tabelindeling SELECT * FROM zijn soms niet voldoende. Wanneer de gegevens voor een zoekopdracht niet in één tabel staan, maar in meerdere, of wanneer het nodig is om meerdere selectieparameters tegelijk op te geven, hebt u meer geavanceerde zoekopdrachten nodig.
In dit artikel wordt uitgelegd hoe u dergelijke query's kunt maken en worden voorbeelden gegeven van complexe SQL-query's.
Hoe ziet een complexe zoekopdracht eruit?
Laten we eerst de voorwaarden definiëren voor het samenstellen van de SQL-query. In het bijzonder moet u de volgende selectieparameters gebruiken:
- de namen van de tabellen waaruit u gegevens wilt extraheren;
- de waarden van velden die moeten worden teruggezet naar de originele nadat er wijzigingen in de database zijn aangebracht;
- de relaties tussen tabellen;
- de bemonsteringsvoorwaarden;
- de aanvullende selectiecriteria (beperkingen, manieren om informatie te presenteren, soort sortering).
Laten we, om het onderwerp beter te begrijpen, een voorbeeld bekijken waarin de volgende vier eenvoudige tabellen worden gebruikt. De eerste regel is de naam van de tabel die bij complexe query's als externe sleutel fungeert. We zullen dit verder in detail bekijken met een voorbeeld:
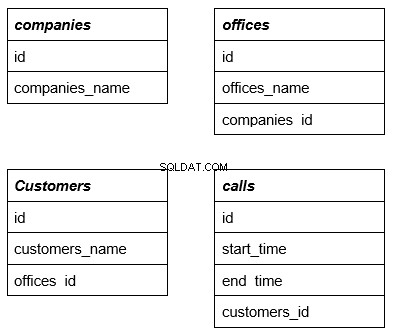
Elke tabel heeft rijen die gerelateerd zijn aan enkele andere tabellen. We zullen verder uitleggen waarom het nodig is.
Laten we nu eens kijken naar de basis SQL-query:
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';De %STARTSWITH predikaat selecteert rijen die beginnen met het opgegeven teken/de opgegeven tekens.
Het resultaat ziet er als volgt uit:

Laten we nu eens kijken naar een complexe SQL-query:
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
Het resultaat is de volgende tabel:

De tabel toont de bedrijven, het bijbehorende aantal telefoontjes en hun geschatte duur.
Verder worden alleen de bedrijfsnamen vermeld waarvan de gemiddelde gespreksduur groter is dan de gemiddelde gespreksduur in andere bedrijven.
Wat zijn de belangrijkste regels voor het maken van complexe SQL-query's?
Laten we proberen een multifunctioneel algoritme te maken voor het samenstellen van complexe zoekopdrachten.
Allereerst moet u beslissen over de tabellen die bestaan uit de gegevens die deelnemen aan de query.
Het bovenstaande voorbeeld betreft de bedrijven en oproepen tafels. Als de tabellen met de vereiste gegevens niet direct aan elkaar gerelateerd zijn, moet u ook de tussenliggende tabellen opnemen die ze samenvoegen.
Om deze reden verbinden we ook tabellen, zoals kantoren en klanten , met behulp van buitenlandse sleutels. Daarom zal elk resultaat van de query met tabellen uit dit voorbeeld altijd de onderstaande regels bevatten:
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
Een gecombineerde tabel suggereert de drie belangrijkste punten:
- Let op de lijst met velden na SELECT. De bewerking van het lezen van gegevens uit samengevoegde tabellen vereist dat u de naam opgeeft van de tabel die moet worden samengevoegd in de naam veld.
- Uw complexe zoekopdracht heeft altijd de hoofdtabel (bedrijven ). De meeste velden worden daaruit gelezen. De bijgevoegde tabel gebruikt in ons voorbeeld drie tabellen - kantoren , klanten , en oproepen . De naam wordt bepaald na de JOIN-operator.
- Naast het specificeren van de naam van de tweede tabel, moet u ook de voorwaarde specificeren voor het uitvoeren van de join. We zullen deze voorwaarde verder bespreken.
- De query geeft een tabel weer met een groot aantal rijen. Het is niet nodig om het hier te publiceren, omdat het tussenresultaten weergeeft. U kunt de uitvoer echter altijd zelf controleren. Dit is erg belangrijk, omdat het helpt om fouten in het eindresultaat te voorkomen.
Laten we nu eens kijken naar het deel van de zoekopdracht dat de gespreksduur binnen elk bedrijf en tussen alle bedrijven vergelijkt. We moeten de gemiddelde duur van alle oproepen berekenen. Gebruik de volgende zoekopdracht:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
Merk op dat we de DATEDIFF . hebben gebruikt functie die het verschil tussen de opgegeven perioden uitvoert. In ons geval is de gemiddelde gespreksduur gelijk aan 335 seconden.
Laten we nu gegevens over oproepen van alle bedrijven aan de zoekopdracht toevoegen.
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
In deze zoekopdracht,
- SUM (GEVAL WANNEER calls.id NIET NULL IS, DAN 1 ELSE 0 EINDE) – om onnodige handelingen te voorkomen, vatten we alleen bestaande oproepen samen – wanneer het aantal oproepen in een bedrijf niet nul is. Dit is erg belangrijk in grote tabellen met mogelijke null-waarden.
- AVG (ISNULL (DATEDIFF (TWEEDE, calls.start_time, calls.end_time), 0)) – de query is identiek aan de AVG-query hierboven. Hier gebruiken we echter de ISNULL operator die NULL vervangt door 0. Het is noodzakelijk voor bedrijven die helemaal geen oproepen hebben.
Onze resultaten:
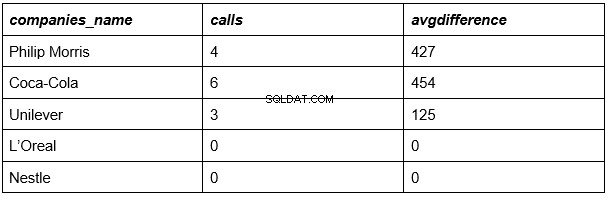
We zijn bijna klaar. De bovenstaande tabel geeft de lijst met bedrijven weer, het bijbehorende aantal oproepen voor elk van hen en de gemiddelde gespreksduur in elk van hen.
Het enige dat overblijft is om de nummers uit de laatste kolom te vergelijken met de gemiddelde duur van alle oproepen van alle bedrijven (335 seconden).
Als u de zoekopdracht invoert die we aan het begin hebben gepresenteerd, voegt u gewoon de HAVING . toe deel, je krijgt wat je nodig hebt.
We raden ten zeerste aan om op elke regel commentaar toe te voegen, zodat u in de toekomst niet in de war raakt wanneer u enkele bestaande complexe SQL-query's moet corrigeren.
Laatste gedachten
Hoewel elke complexe SQL-query een individuele aanpak vereist, zijn enkele aanbevelingen geschikt voor de voorbereiding van de meeste van dergelijke query's.
- bepaal welke tabellen zullen deelnemen aan de zoekopdracht;
- complexe zoekopdrachten maken van eenvoudigere onderdelen;
- controleer de nauwkeurigheid van zoekopdrachten achtereenvolgens, in delen;
- test de nauwkeurigheid van uw zoekopdracht met kleinere tabellen;
- schrijf gedetailleerd commentaar op elke regel die de operand bevat, met de symbolen '-'.
Gespecialiseerde tools maken deze taak veel eenvoudiger. Onder hen raden we aan om de Query Builder te gebruiken - een visuele tool waarmee zelfs de meest complexe zoekopdrachten veel sneller kunnen worden gebouwd in een visuele modus. Deze tool is beschikbaar als een zelfstandige oplossing of als onderdeel van de veelzijdige dbForge Studio voor SQL Server.
We hopen dat dit artikel u heeft geholpen dit specifieke probleem te verduidelijken.