Groeperen is een belangrijke functie die helpt bij het organiseren en ordenen van gegevens. Er zijn veel manieren om dit te doen, en een van de meest effectieve methoden is de SQL GROUP BY-clausule.
U kunt SQL GROUP BY gebruiken om rijen in resultaten in groepen te verdelen met een aggregatiefunctie . Het klinkt gemakkelijk om er records mee op te tellen, te middelen of te tellen.
Maar doe je het goed?
"Juist" kan subjectief zijn. Als het werkt zonder kritieke fouten met een correcte uitvoer, wordt het als goed beschouwd. Het moet echter ook snel zijn.
In dit artikel wordt ook gekeken naar snelheid. U zult in alle punten veel query-analyse zien met behulp van logische reads en uitvoeringsplannen.
Laten we beginnen.
1. Vroeg filteren
Als je niet zeker weet wanneer je WHERE en HAVING moet gebruiken, dan is deze iets voor jou. Omdat, afhankelijk van de voorwaarde die u opgeeft, beide hetzelfde resultaat kunnen geven.
Maar ze zijn anders.
HAVING filtert de groepen met behulp van de kolommen in de SQL GROUP BY-component. WHERE filtert de rijen voordat groepering en aggregaties plaatsvinden. Dus als u filtert met de HAVING-component, vindt groepering plaats voor alle rijen geretourneerd.
En dat is slecht.
Waarom? Het korte antwoord is:het is traag. Laten we dit bewijzen met 2 queries. Bekijk de onderstaande code. Voordat u het in SQL Server Management Studio uitvoert, drukt u eerst op Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analyse
De 2 SELECT-instructies hierboven zullen dezelfde rijen retourneren. Beide zijn correct in het retourneren van productbestellingen per maand in het jaar 2012. Maar de eerste SELECT duurde 136 ms. om op mijn laptop te draaien, terwijl een andere 764 ms duurde.!
Waarom?
Laten we eerst de logische waarden in figuur 1 controleren. De STATISTICS IO heeft deze resultaten geretourneerd. Daarna heb ik het in StatisticsParser.com geplakt voor de geformatteerde uitvoer.
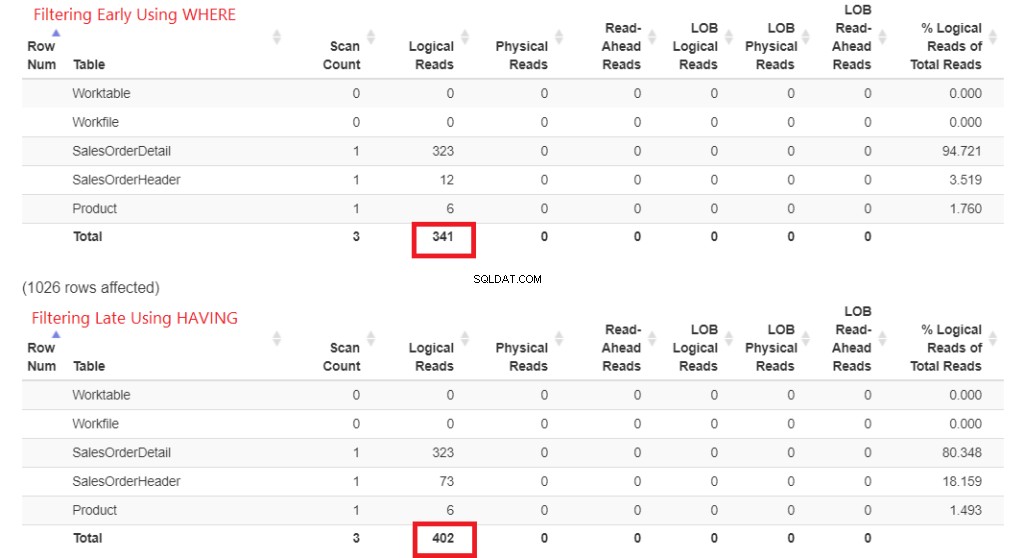
Figuur 1 . Logisch lezen van vroeg filteren met WHERE versus laat filteren met HAVING.
Kijk naar de totale logische uitlezingen van elk. Om deze getallen te begrijpen, geldt:hoe logischer het was om te lezen, hoe langzamer de zoekopdracht zal zijn. Het bewijst dus dat het gebruik van HAVING langzamer is en vroeg filteren met WHERE sneller is.
Dit betekent natuurlijk niet dat HEBBEN nutteloos is. Een uitzondering is bij het gebruik van HAVING met een aggregaat zoals HAVING SUM(sod.Linetotal)> 100000 . U kunt een WHERE-component en een HAVING-component in één zoekopdracht combineren.
Zie het uitvoeringsplan in figuur 2.
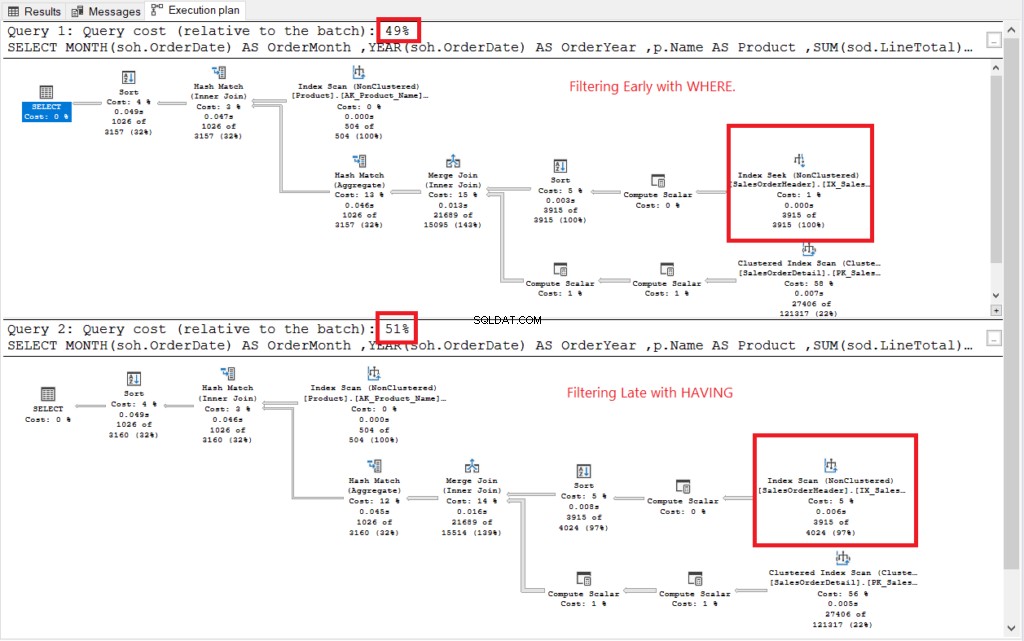
Figuur 2 . Uitvoeringsplannen van vroeg filteren versus laat filteren.
Beide uitvoeringsplannen leken op elkaar, behalve de in het rood omkaderde plannen. Vroeg filteren gebruikte de Index Seek-operator, terwijl een andere Index Scan gebruikte. Zoekopdrachten zijn sneller dan scans in grote tabellen.
Nee te: Vroeg filteren kost minder dan laat filteren. Het komt er dus op neer dat het vroegtijdig filteren van de rijen de prestaties kan verbeteren.
2. Eerst groeperen, later meedoen
Deelnemen aan enkele van de tabellen die u later nodig heeft, kan ook de prestaties verbeteren.
Stel dat u maandelijkse productverkoop wilt hebben. U moet ook de productnaam, het nummer en de subcategorie allemaal in dezelfde zoekopdracht krijgen. Deze kolommen staan in een andere tabel. En ze moeten allemaal worden toegevoegd aan de GROUP BY-clausule om een succesvolle uitvoering te hebben. Hier is de code.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Dit zal prima verlopen. Maar er is een betere, snellere manier. Hiervoor hoeft u de 3 kolommen voor productnaam, nummer en subcategorie niet toe te voegen aan de GROUP BY-clausule. Dit vereist echter wat meer toetsaanslagen. Hier is het.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analyse
Waarom is dit sneller? De joins naar Product en ProductSubcategory worden later gedaan. Beide zijn niet betrokken bij de GROUP BY-clausule. Laten we dit bewijzen met cijfers in de STATISTICS IO. Zie figuur 4.
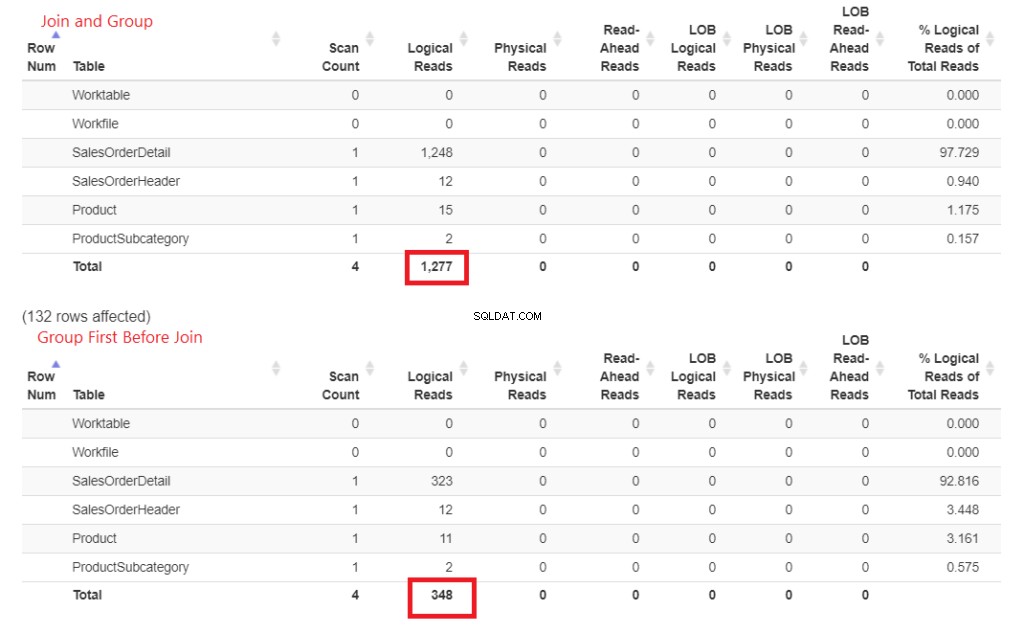
Figuur 3 . Vroeg deelnemen en vervolgens groeperen vergde meer logische leesbewerkingen dan later meedoen.
Zie je die logische leest? Het verschil is groot en de winnaar is duidelijk.
Laten we het uitvoeringsplan van de 2 query's vergelijken om de reden achter de bovenstaande cijfers te zien. Zie eerst Afbeelding 4 voor het uitvoeringsplan van de query met alle tabellen samengevoegd wanneer ze gegroepeerd zijn.
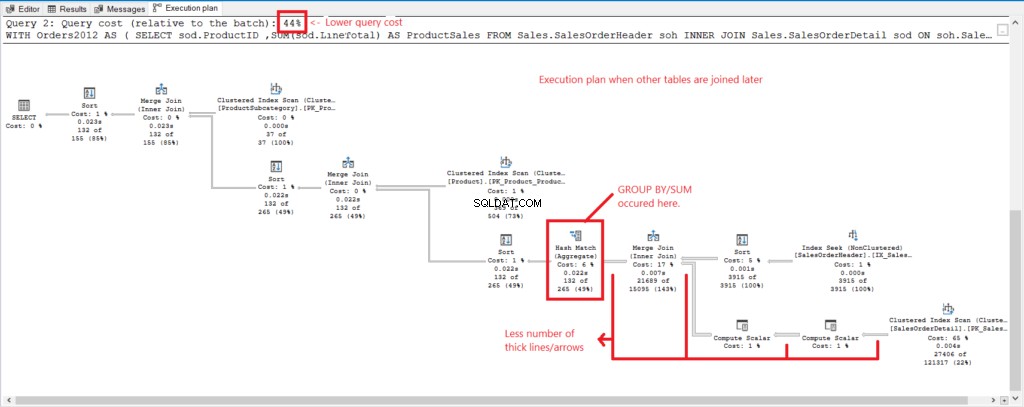
Figuur 4 . Uitvoeringsplan wanneer alle tafels zijn samengevoegd.
En we hebben de volgende opmerkingen:
- GROUP BY en SUM werden laat in het proces gedaan nadat ze alle tabellen hadden samengevoegd.
- Veel dikkere lijnen en pijlen - dit verklaart de 1.277 logische uitlezingen.
- De 2 zoekopdrachten vormen samen 100% van de zoekopdrachtkosten. Maar het plan van deze zoekopdracht heeft hogere kosten voor zoekopdrachten (56%).
Nu, hier is een uitvoeringsplan wanneer we eerst groeperen en lid worden van het Product en ProductSubcategory tafels verderop. Bekijk figuur 5.
Figuur 5 . Uitvoeringsplan wanneer de groep eerst, later deelnemen is klaar.
En we hebben de volgende observaties in figuur 5.
- GROUP BY en SUM waren vroeg klaar.
- Minder aantal dikke lijnen en pijlen - dit verklaart alleen de 348 logische reads.
- Lagere kosten voor zoekopdrachten (44%).
3. Een geïndexeerde kolom groeperen
Telkens wanneer SQL GROUP BY op een kolom wordt uitgevoerd, moet die kolom een index hebben. U verhoogt de uitvoeringssnelheid zodra u de kolom groepeert met een index. Laten we de vorige zoekopdracht aanpassen en de verzenddatum gebruiken in plaats van de besteldatum. De verzenddatumkolom heeft geen index in SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Druk op Ctrl-M en voer de bovenstaande query uit in SSMS. Maak vervolgens een niet-geclusterde index op de ShipDate kolom. Let op de logische uitlezingen en het uitvoeringsplan. Voer ten slotte de bovenstaande query opnieuw uit op een ander querytabblad. Let op de verschillen in logische reads en uitvoeringsplannen.
Hier is de vergelijking van de logische waarden in Afbeelding 6.
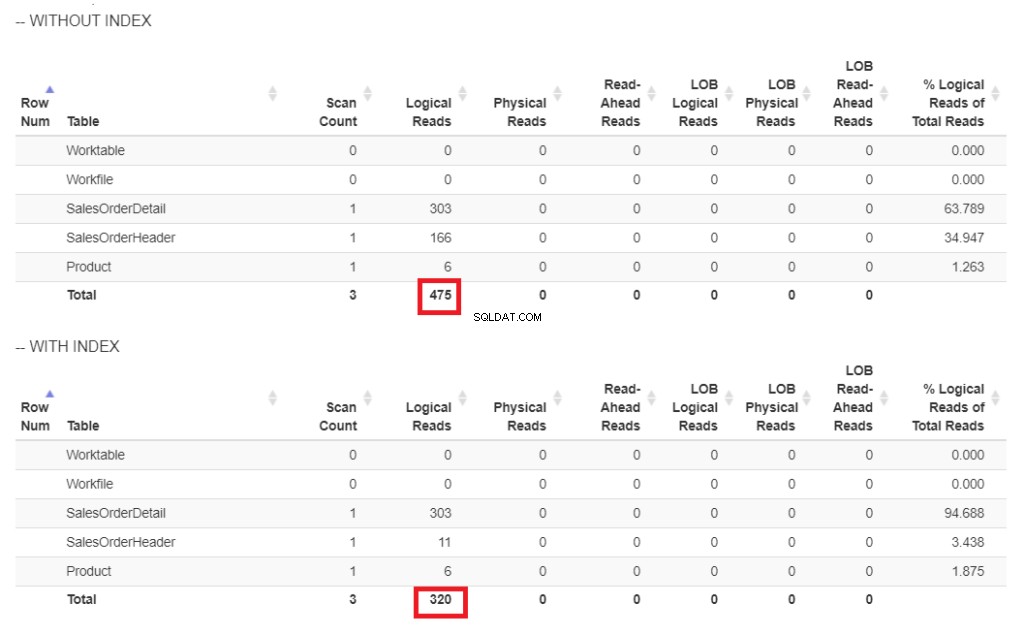
Figuur 6 . Logische lezing van ons vraagvoorbeeld met en zonder index op ShipDate.
In Afbeelding 6 zijn er hogere logische waarden voor de zoekopdracht zonder een index op ShipDate .
Laten we nu het uitvoeringsplan hebben als er geen index is op ShipDate bestaat in figuur 7.
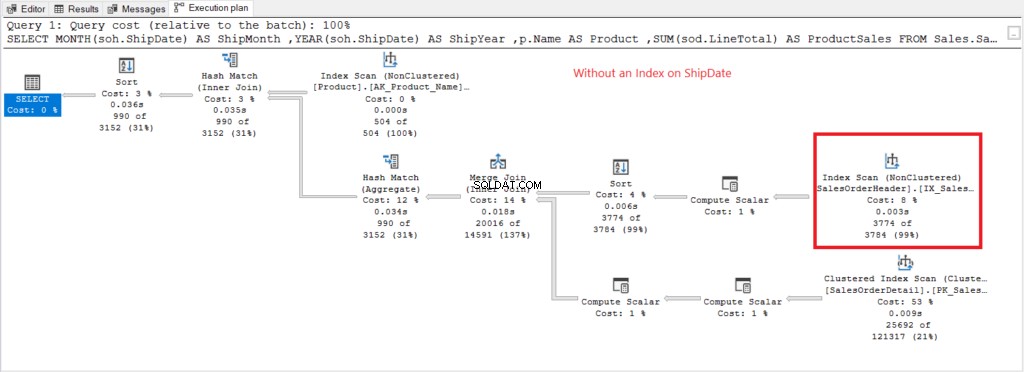
Figuur 7 . Uitvoeringsplan bij gebruik van GROUP BY op ShipDate niet geïndexeerd.
De Indexscan operator gebruikt in het plan in figuur 7 verklaart de hogere logische waarden (475). Hier is een uitvoeringsplan na indexering van de ShipDate kolom.
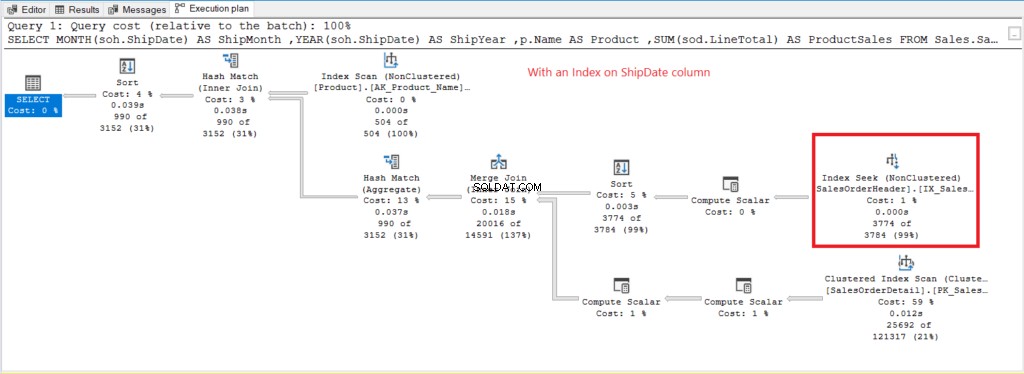
Figuur 8 . Uitvoeringsplan bij gebruik van GROUP BY op ShipDate geïndexeerd.
In plaats van Index Scan wordt een Index Seek gebruikt na indexering van de ShipDate kolom. Dit verklaart de lagere logische waarden in figuur 6.
Dus, om de prestaties bij het gebruik van GROUP BY te verbeteren, kunt u overwegen de kolommen te indexeren die u voor het groeperen hebt gebruikt.
Takeaways bij het gebruik van SQL GROUP BY
SQL GROUP BY is eenvoudig te gebruiken. Maar u moet de volgende stap zetten om verder te gaan dan het samenvatten van de gegevens voor rapporten. Hier zijn de punten nogmaals:
- Filter vroeg . Verwijder de rijen die u niet hoeft samen te vatten met de WHERE-component in plaats van de HAVING-component.
- Eerst groeperen, later meedoen . Soms zijn er kolommen die u moet toevoegen naast de kolommen die u groepeert. In plaats van ze op te nemen in de GROUP BY-component, verdeel je de query met een CTE en voeg je later samen met andere tabellen.
- Gebruik GROUP BY met geïndexeerde kolommen . Dit elementaire ding kan van pas komen als de database zo snel is als een slak.
Ik hoop dat dit je helpt om je spel naar een hoger niveau te tillen bij het groeperen van resultaten.
Als je dit bericht leuk vindt, deel het dan op je favoriete sociale mediaplatforms.