Is SQL DISTINCT goed (of slecht) wanneer u duplicaten in resultaten moet verwijderen?
Sommigen zeggen dat het goed is en voegen DISTINCT toe wanneer duplicaten verschijnen. Sommigen zeggen dat het slecht is en stellen voor om GROUP BY te gebruiken zonder een aggregatiefunctie. Anderen zeggen dat DISTINCT en GROUP BY hetzelfde zijn als je duplicaten moet verwijderen.
Dit bericht zal in de details duiken om de juiste antwoorden te krijgen. Dus uiteindelijk zult u het beste zoekwoord gebruiken op basis van de behoefte. Laten we beginnen.
Een korte herinnering over de basis van de SQL SELECT DISTINCT-instructie
Voordat we dieper duiken, laten we ons herinneren wat de SQL SELECT DISTINCT-instructie is. Een databasetabel kan om vele redenen dubbele waarden bevatten, maar misschien willen we alleen de unieke waarden. In dit geval is SELECT DISTINCT handig. Deze DISTINCT-clausule zorgt ervoor dat de SELECT-instructie alleen unieke records ophaalt.
De syntaxis van de instructie is eenvoudig:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Hier is de WHERE-voorwaarde optioneel.
De verklaring geldt zowel voor een enkele kolom als voor meerdere kolommen. De syntaxis van deze verklaring toegepast op meerdere kolommen is als volgt:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Houd er rekening mee dat het scenario van het doorzoeken van meerdere kolommen zal suggereren om de combinatie van waarden in alle kolommen te gebruiken die door de instructie zijn gedefinieerd om de uniciteit te bepalen.
En laten we nu eens kijken naar het praktische gebruik en de voordelen van het toepassen van de SELECT DISTINCT-instructie.
Hoe SQL DISTINCT werkt om duplicaten te verwijderen
Antwoorden krijgen is niet zo moeilijk te vinden. SQL Server heeft ons uitvoeringsplannen gegeven om te zien hoe een query wordt verwerkt om ons de benodigde resultaten te geven.
De volgende sectie richt zich op het uitvoeringsplan bij gebruik van DISTINCT. U moet op Ctrl-M . drukken in SQL Server Management Studio voordat u de onderstaande query's uitvoert. Of klik op Inclusief daadwerkelijk uitvoeringsplan van de werkbalk.
Queryplannen in SQL DISTINCT
Laten we beginnen met het vergelijken van 2 zoekopdrachten. De eerste gebruikt DISTINCT niet en de tweede wel.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Hier is het uitvoeringsplan:
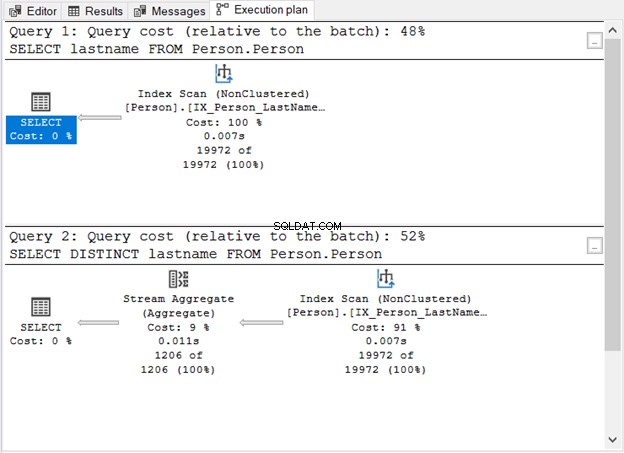
Wat liet figuur 1 ons zien?
- Zonder het trefwoord DISTINCT is de zoekopdracht eenvoudig.
- Er verschijnt een extra stap na het toevoegen van DISTINCT.
- De querykosten van het gebruik van DISTINCT zijn hoger dan zonder.
- Beide hebben Index Scan-operators. Dit is begrijpelijk omdat er geen specifieke WHERE-clausule in onze zoekopdrachten staat.
- De extra stap, de Stream Aggregate-operator, wordt gebruikt om de duplicaten te verwijderen.
Het aantal logische uitlezingen is hetzelfde (107) als u de STATISTICS IO aanvinkt. Toch is het aantal records enorm verschillend. 19.972 rijen worden geretourneerd door de eerste query. Ondertussen worden 1206 rijen geretourneerd door de tweede zoekopdracht.
Daarom kunt u DISTINCT niet op elk gewenst moment toevoegen. Maar als u unieke waarden nodig heeft, is dit een noodzakelijke overhead.
Er zijn operators die worden gebruikt om unieke waarden uit te voeren. Laten we er een paar bekijken.
STREAM AGGREGATE
Dit is de operator die u in figuur 1 zag. Het accepteert een enkele invoer en geeft een geaggregeerd resultaat af. In figuur 1 is de invoer afkomstig van de Index Scan-operator. Stream Aggregate heeft echter een gesorteerde invoer nodig.
Zoals u kunt zien in afbeelding 1, gebruikt het de IX_Person_LastName_FirstName_MiddleName , een niet-unieke index op namen. Omdat de index de records al op naam sorteert, accepteert de Stream Aggregate de invoer. Zonder de index kan de query-optimizer ervoor kiezen om een extra sorteeroperator in het plan te gebruiken. En dat wordt duurder. Of het kan een Hash Match gebruiken.
HASH-MATCH (AGGREGATE)
Een andere operator die door DISTINCT wordt gebruikt, is Hash Match. Deze operator wordt gebruikt voor samenvoegingen en aggregaties.
Bij gebruik van DISTINCT voegt Hash Match de resultaten samen om unieke waarden te produceren. Hier is een voorbeeld.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
En hier is het uitvoeringsplan:
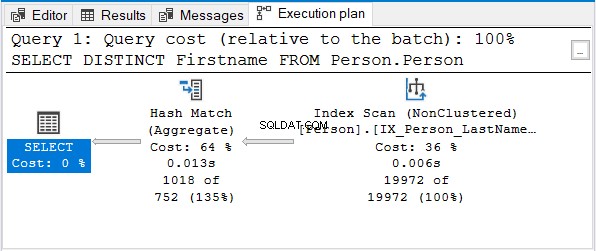
Maar waarom niet Stream Aggregate?
Merk op dat dezelfde naamindex wordt gebruikt. Die index sorteert met Achternaam eerst. Dus een Voornaam alleen de zoekopdracht wordt ongesorteerd.
Hash Match (Aggregate) is de volgende logische keuze om de duplicaten te verwijderen.
HASH-MATCH (FLOW DISTINCT)
De Hash Match (Aggregate) is een blokkerende operator. Het zal dus niet de uitvoer produceren die het de hele invoerstroom heeft verwerkt. Als we het aantal rijen beperken (zoals het gebruik van TOP met DISTINCT), zal het een unieke uitvoer produceren zodra die rijen beschikbaar zijn. Dat is waar het bij Hash Match (Flow Distinct) om draait.
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
De query gebruikt TOP 100 samen met DISTINCT. Hier is het uitvoeringsplan:
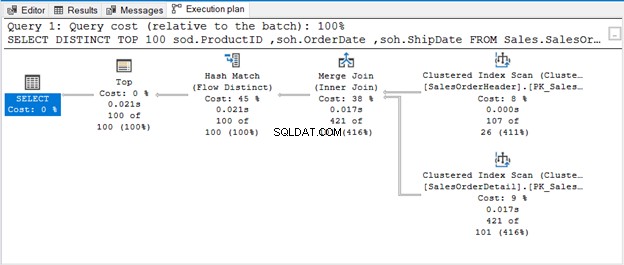
WANNEER ER GEEN OPERATOR IS OM DUPLICATES TE VERWIJDEREN
JEP. Dit kan gebeuren. Bekijk het onderstaande voorbeeld.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Controleer vervolgens het uitvoeringsplan:
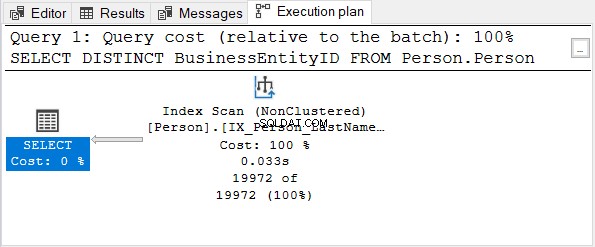
De BusinessEntityID kolom is de primaire sleutel. Aangezien die kolom al uniek is, heeft het geen zin om DISTINCT toe te passen. Probeer DISTINCT uit de SELECT-instructie te verwijderen – het uitvoeringsplan is hetzelfde als in figuur 4.
Hetzelfde geldt voor het gebruik van DISTINCT op kolommen met een unieke index.
SQL DISTINCT werkt op ALLE kolommen in de SELECT-lijst
Tot nu toe hebben we in onze voorbeelden slechts 1 kolom gebruikt. DISTINCT werkt echter op ALLE kolommen die u opgeeft in de SELECT-lijst.
Hier is een voorbeeld. Deze zoekopdracht zorgt ervoor dat de waarden van alle 3 de kolommen uniek zijn.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Let op de eerste paar rijen in de resultatenset in Afbeelding 5.
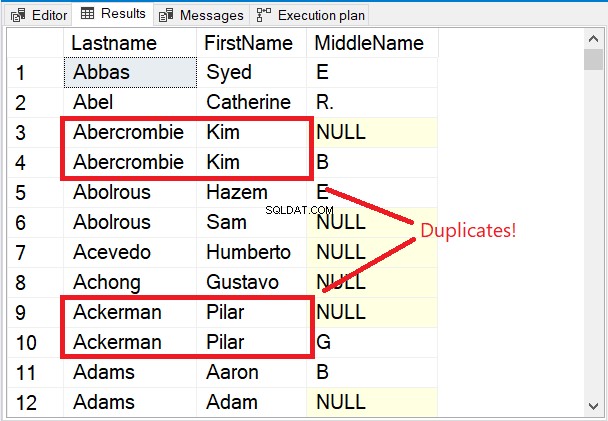
De eerste paar rijen zijn allemaal uniek. Het DISTINCT-sleutelwoord zorgde ervoor dat de Middelnaam kolom wordt ook overwogen. Let op de 2 namen in het rood. Gezien de Achternaam en Voornaam zal ze alleen duplicaten maken. Maar het toevoegen van Middelnaam door de mix veranderde alles.
Wat als u unieke voor- en achternaam wilt, maar de middelste naam in het resultaat wilt opnemen?
Je hebt 2 opties:
- Voeg een WHERE-component toe om NULL middelste namen te verwijderen. Dit zal alle namen met een NULL middelste naam verwijderen.
- Of voeg een GROUP BY-clausule toe aan Achternaam en Voornaam kolommen. Gebruik vervolgens de MIN-aggregatiefunctie op de Middennaam kolom. Dit krijgt 1 middelste naam met dezelfde achternaam en voornaam.
SQL DISTINCT vs. GROUP BY
Bij gebruik van GROUP BY zonder een aggregatiefunctie, werkt het als DISTINCT. Hoe weten we? Een manier om erachter te komen is door een voorbeeld te gebruiken.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Voer ze uit en bekijk het uitvoeringsplan. Is het zoals de onderstaande schermafbeelding?
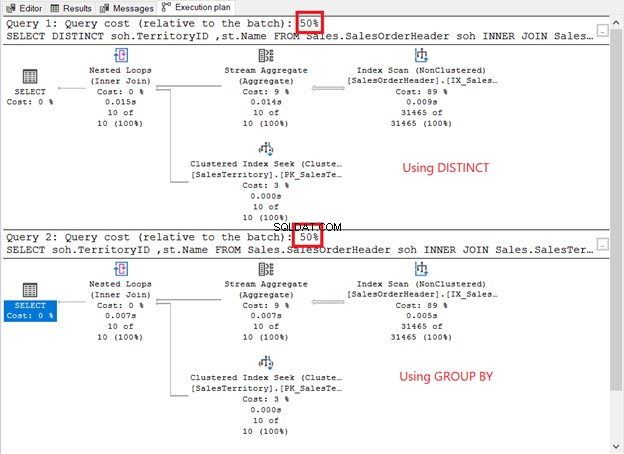
Hoe vergelijken ze?
- Ze hebben dezelfde planoperators en volgorde.
- De operatorkosten van elk en de querykosten zijn hetzelfde.
Als u de QueryPlanHash . aanvinkt eigenschappen van de 2 SELECT-operators, zijn ze hetzelfde. Daarom gebruikte de query-optimizer hetzelfde proces om dezelfde resultaten te retourneren.
Uiteindelijk kunnen we niet zeggen dat het gebruik van GROUP BY beter is dan DISTINCT bij het retourneren van unieke waarden. U kunt dit bewijzen door de bovenstaande voorbeelden te gebruiken om DISTINCT te vervangen door GROUP BY.
Het is nu een kwestie van voorkeur welke je gaat gebruiken. Ik heb liever DISTINCT. Het vertelt expliciet de bedoeling in de zoekopdracht - om unieke resultaten te produceren. En voor mij is GROUP BY voor het groeperen van resultaten met behulp van een aggregatiefunctie. Die intentie is ook duidelijk en consistent met het trefwoord zelf. Ik weet niet of iemand anders op een dag mijn vragen zal onderhouden. De code moet dus duidelijk zijn.
Maar dat is niet het einde van het verhaal.
Als SQL DISTINCT niet hetzelfde is als GROUP BY
Ik heb net mijn mening geuit, en dan dit?
Het is waar. Ze zullen niet altijd hetzelfde zijn. Overweeg dit voorbeeld.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Hoewel de resultatenset ongesorteerd is, zijn de rijen hetzelfde als in het vorige voorbeeld. Het enige verschil is het gebruik van een subquery:
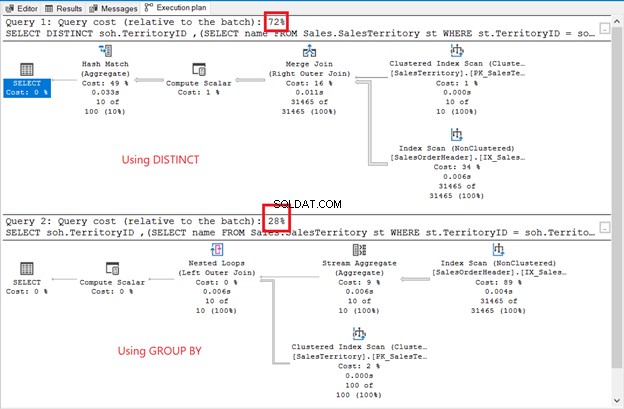
De verschillen zijn duidelijk:operators, querykosten, algemeen plan. Deze keer wint GROUP BY met slechts 28% querykosten. Maar hier is het ding.
Het doel is om je te laten zien dat het ook anders kan. Dat is alles. Dit is geenszins een aanbeveling. Het gebruik van een join heeft een beter uitvoeringsplan (zie opnieuw figuur 6).
De bottomline
Dit is wat we tot nu toe hebben geleerd:
- DISTINCT voegt een plan-operator toe om duplicaten te verwijderen.
- DISTINCT en GROUP BY zonder een aggregatiefunctie resulteren in hetzelfde plan. Kortom, ze zijn meestal hetzelfde.
- Soms kunnen DISTINCT en GROUP BY verschillende plannen hebben wanneer een subquery betrokken is bij de SELECT-lijst.
Dus, is SQL DISTINCT goed of slecht in het verwijderen van duplicaten in resultaten?
De resultaten zeggen dat het goed is. Het is niet beter of slechter dan GROUP BY omdat de plannen hetzelfde zijn. Maar het is een goede gewoonte om het uitvoeringsplan te controleren. Denk vanaf het begin aan optimalisatie. Op die manier zul je ze opmerken als je verschillen tegenkomt in DISTINCT en GROUP BY.
Bovendien maken de moderne tools deze taak veel eenvoudiger. Een populair product dbForge SQL Complete van Devart heeft bijvoorbeeld een specifieke functie die waarden berekent in de geaggregeerde functies in de kant-en-klare resultatenset van het SSMS-resultatenraster. De DISTINCT-waarden zijn daar ook aanwezig.
Vind je het bericht leuk? Verspreid het woord dan door het te delen op uw favoriete sociale-mediaplatforms.
Verwante artikelen voor meer informatie
- SQL GROUP BY:3 eenvoudige tips om resultaten als een professional te groeperen
- SQL INSERT INTO SELECT:5 eenvoudige manieren om met duplicaten om te gaan
- Wat zijn SQL-aggregatiefuncties? (Eenvoudige tips voor beginners)
- SQL-queryoptimalisatie:5 kernfeiten om zoekopdrachten te stimuleren