In een vorig artikel bespraken we het star schema model. Het sneeuwvlokschema staat naast het sterschema wat betreft het belang ervan in datawarehouse-modellering. Het is ontwikkeld vanuit het sterrenschema en biedt enkele voordelen ten opzichte van zijn voorganger. Maar aan deze voordelen hangt een prijskaartje. In dit artikel bespreken we wanneer en hoe het sneeuwvlokschema te gebruiken.
Het sneeuwvlokschema
De naam van het sneeuwvlokschema komt van het feit dat dimensietabellen vertakken en er ongeveer als een sneeuwvlok uitzien. Als we naar het bovenstaande model kijken, zullen we zien dat het een feitentabel is, omringd door een paar dimensietabellen, waarvan sommige de bovengenoemde vertakkingen doen. In tegenstelling tot het sterschema kunnen dimensietabellen in het sneeuwvlokschema hun eigen categorieën hebben.
Het overheersende idee achter het sneeuwvlokschema is dat dimensietabellen volledig genormaliseerd zijn. Elke dimensietabel kan worden beschreven door een of meer opzoektabellen. Elke opzoektabel kan worden beschreven door een of meer aanvullende opzoektabellen. Dit wordt herhaald totdat het model volledig is genormaliseerd. Het proces van het normaliseren van dimensietabellen met sterschema's wordt sneeuwvlokken genoemd.
U zult in dit artikel veel horen over normalisatie. Wat is normalisatie? Kortom, het organiseert een database op een manier die redundanties minimaliseert en de gegevensintegriteit beschermt. Bekijk dit bericht voor meer informatie over normalisatie en denormalisatie.
Voorbeeld sneeuwvlokschema:verkoopmodel
Voorheen gebruikten we een sterschema om een fictieve verkoopafdeling te modelleren - dit zou vergelijkbaar zijn met een datamart die wordt gebruikt om verkoopactiviteiten en resultaten bij te houden. Het model heeft vijf dimensies:product , tijd , winkel , verkoop type en werknemer . In de fact_sales tafel, prijs en hoeveelheid worden opgeslagen en gegroepeerd op basis van waarden in dimensietabellen. Bekijk voor een opfriscursus het onderstaande verkoopmodel met sterschema's:
Hier is hetzelfde model georganiseerd als een sneeuwvlokschema:
De dim_employee en dim_sales_type dimensietabellen zijn precies hetzelfde als in het sterschemamodel omdat ze al genormaliseerd zijn.
Aan de andere kant hebben we normalisatieregels toegepast op de rest van de dimensietabellen.


Het dim_product dimensietabel uit het sterschema wordt in het sneeuwvlokmodel in twee tabellen gesplitst. De dim_product_type tabel is toegevoegd om te verwijzen naar het overeenkomende type in de dim_product tafel. Hiermee hebben we enkele problemen met de gegevensintegriteit vermeden.
Het is logisch om aan te nemen dat we alle productnamen en hun gerelateerde typen al hebben ingevoegd als onderdeel van het ETL-proces, maar stel dat we meer productnamen en -typen moeten toevoegen. In een sterrenschema kunnen we per ongeluk het verkeerde producttype in de tabel invoeren. In het sneeuwvlokschema:
- Als we een nieuwe producttypenaam tegenkomen, kunnen we een nieuw producttype toevoegen en dat type vervolgens relateren aan een nieuw toegevoegd record. Dit kan er echter toe leiden dat de gebruiker verkeerde informatie invoert, net als in het sterrenschema.
- We kunnen controleren of de productnaam die we willen toevoegen al bestaat. Als dat zo is, kunnen we de ID ervan krijgen; zo niet, dan verschijnt er een waarschuwing met de vraag of we een nieuw product en een gerelateerd type willen toevoegen.

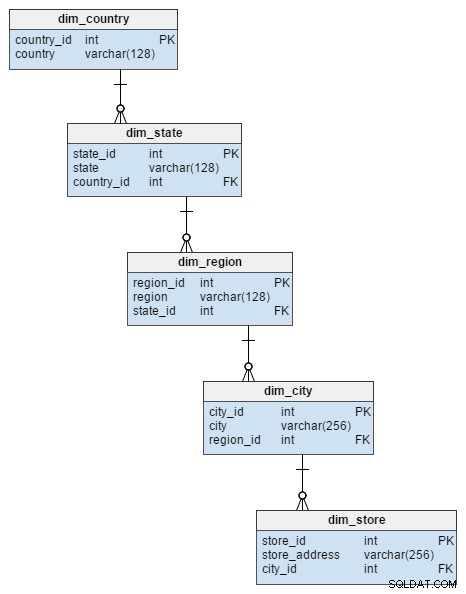
De dim_store dimensietabel uit het sterrenschema wordt weergegeven door 5 tabellen in het sneeuwvlokschema. Deze verdelen de stad-, regio-, staats- en landkenmerken die zijn opgeslagen in de dim_store tafel. Door deze tabel te normaliseren werd niet alleen het risico op gegevensintegriteit vermeden, maar werd ook wat schijfruimte bespaard.
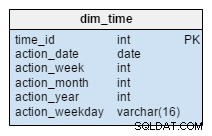
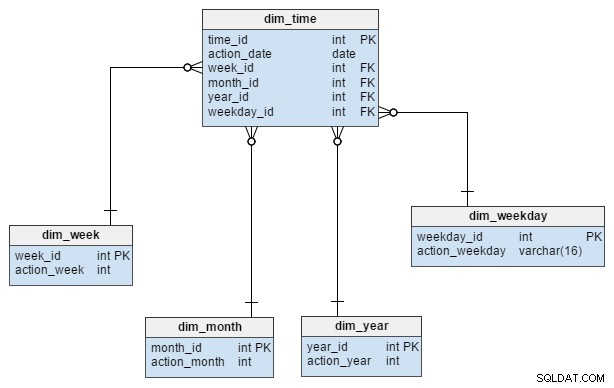
De dim_time dimensie wordt weergegeven met vijf tabellen. We kunnen denken aan dim_week , dim_month , dim_year en de dim_weekday tabellen als woordenboeken die de dim_time tafel.
De dim_week , dim_month , dim_year en dim_weekday tabellen zijn vier verschillende hiërarchieën die worden gebruikt om onze tijddimensie te beschrijven. We zouden meer dimensies kunnen toevoegen, zoals kwartalen of andere gerelateerde tabellen als we ze nodig hadden. In dit voorbeeld dim_month is een woordenboek met 12 maanden; vanuit deze dimensie alleen kunnen we niet weten tot welk jaar die maand behoort; dat is de functie van de dim_year tafel.
Voorbeeld sneeuwvlokschema:model voor leveringsorders
De andere datamart die we bespraken, was voor leveringsorders. Het idee is om alle leveringsordergegevens voor de volgende vier dimensies op te slaan en samen te voegen:product , tijd , leverancier en werknemer . We bekijken nogmaals het relevante sterrenschema:
Als we dit omzetten naar het sneeuwvlokschema, krijgen we het volgende model:
Dezelfde normalisatieregels als beschreven voor het verkoopmodel werden gebruikt op de dim_product , dim_time en dim_supplier maattabellen.
Voor- en nadelen van het sneeuwvlokschema
Er zijn twee belangrijke voordelen naar het sneeuwvlokschema:
- Betere gegevenskwaliteit (gegevens zijn meer gestructureerd, dus problemen met gegevensintegriteit worden verminderd)
- Er wordt minder schijfruimte gebruikt dan in een gedenormaliseerd model
Het meest opvallende nadeel voor het sneeuwvlokmodel is dat het complexere zoekopdrachten vereist. Deze zoekopdrachten, met hun toegenomen aantal joins, kunnen de prestaties aanzienlijk verminderen.
We herschrijven dezelfde query die is gebruikt in het artikel over sterschema's voor het verkoopmodel voor sneeuwvlokschema's. Dit is de vraag die nodig is om de hoeveelheid te retourneren van alle typen telefoonproducten die in 2016 in Berlijnse winkels zijn verkocht:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Het Starflake-schema
Een starflake-schema is een combinatie van het sneeuwvlok- en het sterrenschema. We kunnen het zien als een sneeuwvlokschema waarin sommige dimensietabellen gedenormaliseerd zijn. Bij correct gebruik kan het starflake-schema een benadering van het beste van twee werelden bieden. Het is duidelijk dat het sneeuwvlokgedeelte van het model schijfruimte moet besparen, terwijl het stergedeelte de prestaties moet verbeteren.
Het bovenstaande model is in feite een sneeuwvlokmodel met een gedenormaliseerde dim_time tafel. Aangezien dit schema het aantal benodigde query-joins vermindert, kan het de prestaties verbeteren. Aan de andere kant zullen we geen noemenswaardige hoeveelheid schijfruimte verliezen, aangezien de meeste tabelattributen en refererende sleutelattributen de int delen. typ.
Het Melkwegschema
Bij datawarehousing is er sprake van een melkwegschema wanneer twee of meer feitentabellen een of meer dimensietabellen delen. Een reden om dit schema te gebruiken is om schijfruimte te besparen. We hebben hieronder een voorbeeld van een melkwegstelsel gemaakt:
Hier hebben we twee feitentabellen, fact_sales en fact_supply_order , die rechtstreeks drie dimensietabellen delen:dim_product , dim_employee en dim_time . Merk op dat zelfs dim_store en dim_supplier deel dezelfde opzoektabel, dim_city .
Op deze manier besparen we ruimte, maar we moeten een paar dingen in gedachten hebben voordat we twee datamarts (in dit geval verkoop- en leveringsorders) samenvoegen tot één melkwegschema:
- Is er enige logica om zich bij hen aan te sluiten? Bijvoorbeeld Zouden beide datamarts door dezelfde afdeling worden gebruikt?
- Weten we zeker dat we precies dezelfde dimensie en granulatie nodig hebben voor beide datamarts?
Het sneeuwvlokschema wordt vaak gebruikt bij gegevensmodellering. Het kan de juiste keuze zijn in situaties waarin schijfruimte belangrijker is dan prestaties. Als we een balans willen tussen ruimtebesparing en prestaties, kunnen we het starflake-schema gebruiken. Toch hangt de juiste pasvorm voor elk specifiek probleem af van veel parameters. Dit is een van de gebieden in de IT waar we met factoren kunnen ‘spelen’ om tot de beste oplossing te komen.