Kevin Kline (@kekline) en ik hebben onlangs een webinar voor het afstemmen van zoekopdrachten gehouden (nou ja, één in een reeks, eigenlijk), en een van de dingen die naar voren kwamen, is de neiging van mensen om elke ontbrekende index te maken waarvan SQL Server zegt dat ze zullen worden een goede zaak™ . Ze kunnen meer te weten komen over deze ontbrekende indexen via de Database Engine Tuning Advisor (DTA), de ontbrekende index-DMV's of een uitvoeringsplan dat wordt weergegeven in Management Studio of Plan Explorer (die allemaal informatie doorgeven vanaf precies dezelfde plaats):
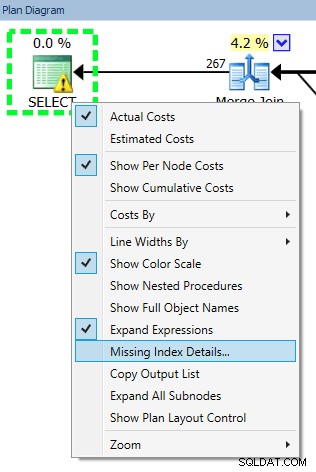
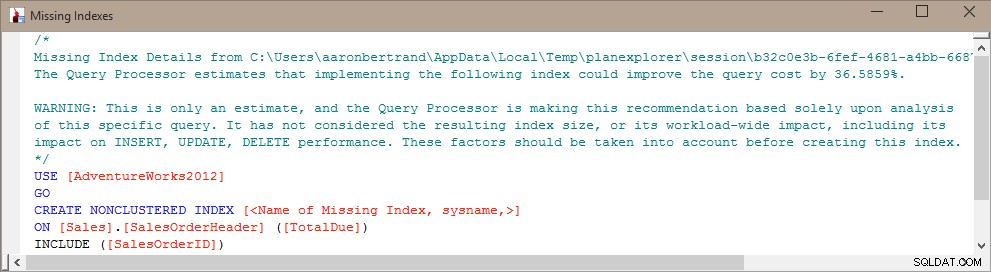
Het probleem met het blindelings maken van deze index is dat SQL Server heeft besloten dat het nuttig is voor een bepaalde query (of een handvol query's), maar de rest van de werklast volledig en eenzijdig negeert. Zoals we allemaal weten, zijn indexen niet "gratis" - u betaalt voor indexen zowel in onbewerkte opslag als voor onderhoud dat nodig is voor DML-bewerkingen. Bij een zware schrijfbelasting heeft het weinig zin om een index toe te voegen die helpt om een enkele query iets efficiënter te maken, vooral als die query niet vaak wordt uitgevoerd. In deze gevallen kan het erg belangrijk zijn om uw algehele werklast te begrijpen en een goede balans te vinden tussen het efficiënt maken van uw zoekopdrachten en niet te veel betalen voor het onderhoud van de index.
Dus een idee dat ik had was om informatie uit de ontbrekende index-DMV's, de indexgebruiksstatistieken DMV en informatie over queryplannen te "masseren", om te bepalen welk type saldo er momenteel bestaat en hoe het toevoegen van de index in het algemeen zou kunnen verlopen.
Ontbrekende indexen
Eerst kunnen we kijken naar de ontbrekende indexen die SQL Server momenteel suggereert:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Dit toont de tabel(len) en kolom(men) die nuttig zouden zijn geweest in een index, hoeveel compilaties/zoekopdrachten/scans zouden zijn gebruikt en wanneer de laatste dergelijke gebeurtenis plaatsvond voor elke potentiële index. U kunt ook kolommen opnemen zoals s.avg_total_user_cost en s.avg_user_impact als je die cijfers wilt gebruiken om prioriteiten te stellen.
Bewerkingen plannen
Laten we vervolgens eens kijken naar de bewerkingen die zijn gebruikt in alle plannen die we in de cache hebben opgeslagen tegen de objecten die zijn geïdentificeerd door onze ontbrekende indexen.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Een vriend op dba.SE, Mikael Eriksson, stelde de volgende twee zoekopdrachten voor die, op een groter systeem, veel beter zullen presteren dan de XML / UNION-query die ik hierboven heb samengevoegd, dus je zou er eerst mee kunnen experimenteren. Zijn laatste opmerking was dat hij "niet verrassend ontdekte dat minder XML een goede zaak is voor de prestaties. :)" Inderdaad.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Nu in de #planops tabel heb je een aantal waarden voor plan_handle zodat je elk van de individuele plannen die in het spel zijn, kunt gaan onderzoeken aan de hand van de objecten waarvan is vastgesteld dat ze een bruikbare index missen. We gaan het daar nu niet voor gebruiken, maar je kunt hier gemakkelijk een kruisverwijzing naar maken met:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Nu kunt u op een van de uitvoerplannen klikken om te zien wat ze momenteel doen tegen uw objecten. Houd er rekening mee dat sommige plannen worden herhaald, omdat een plan meerdere operators kan hebben die verwijzen naar verschillende indexen in dezelfde tabel.
Statistieken indexgebruik
Laten we vervolgens eens kijken naar de indexgebruiksstatistieken, zodat we kunnen zien hoeveel daadwerkelijke activiteit momenteel wordt uitgevoerd tegen onze kandidatentabellen (en vooral updates).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Wees niet ongerust als zeer weinig of geen plannen in de cache updates tonen voor een bepaalde index, ook al laten de statistieken van het indexgebruik zien dat die indexen zijn bijgewerkt. Dit betekent alleen dat de updateplannen zich momenteel niet in de cache bevinden, wat verschillende redenen kan hebben - het kan bijvoorbeeld een zeer leeszware werklast zijn en ze zijn verouderd, of ze zijn allemaal single- gebruiken en optimize for ad hoc workloads is ingeschakeld.
Alles bij elkaar
De volgende query toont u, voor elke voorgestelde ontbrekende index, het aantal leesbewerkingen dat een index mogelijk heeft geholpen, het aantal schrijf- en leesbewerkingen dat momenteel is vastgelegd ten opzichte van de bestaande indexen, de verhouding daarvan, het aantal plannen dat is gekoppeld aan dat object, en het totale aantal gebruik telt voor die plannen:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Als je schrijf:lees-ratio tot deze indexen al> 1 (of> 10!), is, denk ik dat het reden is om te pauzeren voordat je blindelings een index maakt die deze verhouding alleen maar kan verhogen. Het aantal potential_read_ops getoond, kan dit echter compenseren naarmate het aantal groter wordt. Als de potential_read_ops aantal erg klein is, wilt u de aanbeveling waarschijnlijk volledig negeren voordat u de moeite neemt om de andere statistieken te onderzoeken - dus u kunt een WHERE toevoegen clausule om enkele van die aanbevelingen eruit te filteren.
Een paar opmerkingen:
- Dit zijn lees- en schrijfbewerkingen, geen individueel gemeten lees- en schrijfbewerkingen van 8K-pagina's.
- De verhouding en vergelijkingen zijn grotendeels educatief; het zou heel goed zo kunnen zijn dat 10.000.000 schrijfbewerkingen allemaal een enkele rij beïnvloedden, terwijl 10 leesbewerkingen aanzienlijk meer impact hadden kunnen hebben. Dit is slechts bedoeld als een ruwe richtlijn en gaat ervan uit dat lees- en schrijfbewerkingen ongeveer hetzelfde worden gewogen.
- U kunt ook kleine variaties op sommige van deze zoekopdrachten gebruiken om erachter te komen - buiten de ontbrekende indexen die SQL Server aanbeveelt - hoeveel van uw huidige indexen verspillend zijn. Er zijn online genoeg ideeën hierover, waaronder dit bericht van Paul Randal (@PaulRandal).
Ik hoop dat dit wat ideeën geeft om meer inzicht te krijgen in het gedrag van uw systeem voordat u besluit een index toe te voegen die een tool u heeft opgedragen. Ik had dit als één enorme vraag kunnen maken, maar ik denk dat de afzonderlijke delen je een aantal konijnenholen zullen geven om te onderzoeken, als je dat wilt.
Andere opmerkingen
Mogelijk wilt u dit ook uitbreiden om de huidige groottestatistieken, de breedte van de tabel en het aantal huidige rijen vast te leggen (evenals eventuele voorspellingen over toekomstige groei); dit kan u een goed idee geven van hoeveel ruimte een nieuwe index in beslag zal nemen, wat een probleem kan zijn, afhankelijk van uw omgeving. Ik kan dit in een toekomstige post behandelen.
Natuurlijk moet u er rekening mee houden dat deze statistieken alleen zo nuttig zijn als uw uptime dicteert. De DMV's worden gewist na een herstart (en soms in andere, minder storende scenario's), dus als u denkt dat deze informatie over een langere periode nuttig zal zijn, kunt u overwegen om periodieke snapshots te maken.