Een van de vele verbeteringen aan uitvoeringsplannen in SQL Server 2012 was de toevoeging van threadreserverings- en gebruiksinformatie voor parallelle uitvoeringsplannen. Dit bericht kijkt naar wat deze cijfers precies betekenen en biedt aanvullende inzichten in het begrijpen van parallelle uitvoering.
Overweeg de volgende query die wordt uitgevoerd op een vergrote versie van de AdventureWorks-database:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; De query-optimizer kiest een parallel uitvoeringsplan:
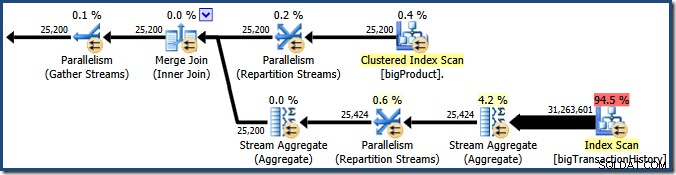
Plan Explorer toont details over het gebruik van parallelle threads in de knopinfo van het hoofdknooppunt. Om dezelfde informatie in SSMS te zien, klikt u op het hoofdknooppunt van het plan, opent u het venster Eigenschappen en vouwt u de ThreadStat uit. knooppunt. Met behulp van een machine met acht logische processors die beschikbaar zijn voor SQL Server, wordt de threadgebruiksinformatie van een typische uitvoering van deze query hieronder weergegeven, Plan Explorer aan de linkerkant, SSMS-weergave aan de rechterkant:
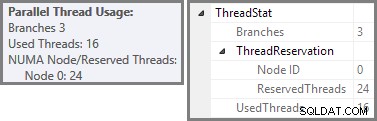
De schermafbeelding toont de uitvoeringsengine die 24 threads voor deze query heeft gereserveerd en er 16 van heeft gebruikt. Het laat ook zien dat het zoekplan drie vertakkingen . heeft , al staat er niet precies bij wat een filiaal is. Als je mijn Simple Talk-artikel over het uitvoeren van parallelle query's hebt gelezen, weet je dat branches secties zijn van een parallel queryplan dat wordt begrensd door exchange-operators. Het onderstaande diagram tekent de grenzen en nummert de takken (klik om te vergroten):

Tak Twee (Oranje)
Laten we eerst wat meer in detail kijken naar tak twee:
Bij een mate van parallellisme (DOP) van acht, zijn er acht threads die deze tak van het queryplan uitvoeren. Het is belangrijk om te begrijpen dat dit het volledige uitvoeringsplan is wat deze acht threads betreft - ze hebben geen kennis van het bredere plan.
In een serieel uitvoeringsplan leest een enkele thread gegevens uit een gegevensbron, verwerkt de rijen via een aantal planoperators en retourneert de resultaten naar de bestemming (dit kan bijvoorbeeld een SSMS-queryresultatenvenster of een databasetabel zijn).
In een filiaal van een parallel uitvoeringsplan, is de situatie zeer vergelijkbaar:elke thread leest gegevens van een bron, verwerkt de rijen via een aantal planoperators en stuurt de resultaten terug naar de bestemming. De verschillen zijn dat de bestemming een uitwisselingsoperator (parallelisme) is en dat de gegevensbron ook een uitwisseling kan zijn.
In de oranje tak is de gegevensbron een Clustered Index Scan en de bestemming is de rechterkant van een Repartition Streams-uitwisseling. De rechterkant van een beurs staat bekend als de producentenkant , omdat het verbinding maakt met een tak die gegevens aan de centrale toevoegt.
De acht draden in de oranje tak werken samen om de tafel te scannen en rijen toe te voegen aan de uitwisseling. De centrale assembleert rijen tot pakketten ter grootte van een pagina. Zodra een pakket vol is, wordt het over de centrale naar de andere kant geduwd. Als de centrale nog een leeg pakket beschikbaar heeft om te vullen, gaat het proces door totdat alle gegevensbronrijen zijn verwerkt (of de uitwisseling geen lege pakketten meer heeft).
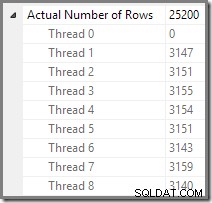
We kunnen het aantal rijen zien dat op elke thread is verwerkt met behulp van de Plan Tree-weergave in Plan Explorer:
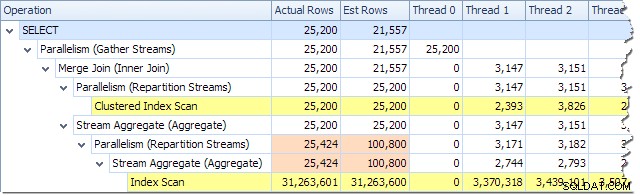
Plan Explorer maakt het gemakkelijk om te zien hoe rijen zijn verdeeld over threads voor allen de fysieke handelingen in het plan. In SSMS bent u beperkt tot het zien van rijdistributie voor een enkele planoperator. Klik hiervoor op een operatorpictogram, open het venster Eigenschappen en vouw vervolgens het knooppunt Werkelijk aantal rijen uit. De onderstaande afbeelding toont SSMS-informatie voor het knooppunt Repartition Streams op de grens tussen de oranje en paarse takken:
Tak drie (groen)
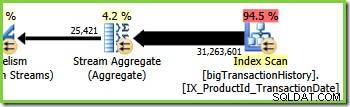
Tak drie is vergelijkbaar met tak twee, maar bevat een extra Stream Aggregate-operator. De groene tak heeft ook acht draden, dus er zijn er tot nu toe zestien gezien. De acht groene vertakkingen lezen gegevens van een niet-geclusterde indexscan, voeren een soort aggregatie uit en geven de resultaten door aan de producentenkant van een andere Repartition Streams-uitwisseling.
De Plan Explorer-tooltip voor de Stream Aggregate laat zien dat het wordt gegroepeerd op product-ID en een uitdrukking berekent met het label partialagg1005 :
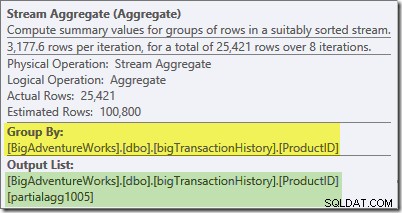
Het tabblad Uitdrukkingen laat zien dat de uitdrukking het resultaat is van het tellen van de rijen in elke groep:

De Stream Aggregate berekent een gedeeltelijk (ook bekend als 'lokaal') aggregaat. De gedeeltelijke (of lokale) kwalificatie betekent eenvoudigweg dat elke thread het aggregaat berekent op de rijen die hij ziet. Rijen uit de Index Scan worden verdeeld tussen threads met behulp van een op vraag gebaseerd schema:er is geen vaste verdeling van rijen van tevoren; threads ontvangen een reeks rijen van de scan als ze erom vragen. Welke rijen in welke threads terechtkomen, is in wezen willekeurig omdat het afhangt van timingproblemen en andere factoren.
Elke thread ziet verschillende rijen van de scan, maar rijen met de dezelfde product-ID kan door meer dan één draad worden gezien. Het totaal is 'gedeeltelijk' omdat subtotalen voor een bepaalde product-ID-groep op meer dan één thread kunnen voorkomen; het is 'lokaal' omdat elke thread zijn resultaat berekent alleen op basis van de rijen die het toevallig ontvangt. Stel dat er bijvoorbeeld 1000 rijen zijn voor product-ID #1 in de tabel. Een thread kan 432 van die rijen zien, terwijl een andere 568 kan zien. Beide threads hebben een gedeeltelijke aantal rijen voor product-ID #1 (432 in de ene thread, 568 in de andere).
Gedeeltelijke aggregatie is een prestatie-optimalisatie omdat het het aantal rijen eerder vermindert dan anders mogelijk zou zijn. In de groene tak resulteert vroege aggregatie in minder rijen die in pakketten worden samengevoegd en over de Repartition Stream-uitwisseling worden gepusht.
Tak 1 (paars)

De paarse tak heeft nog acht draden, dus tot nu toe vierentwintig. Elke thread in deze vertakking leest rijen van de twee Repartition Streams-uitwisselingen en schrijft rijen naar een Gather Streams-uitwisseling. Deze tak lijkt misschien ingewikkeld en onbekend, maar het is gewoon het lezen van rijen uit een gegevensbron en het verzenden van resultaten naar een bestemming, zoals elk ander queryplan.
De rechterkant van het plan toont gegevens die worden gelezen vanaf de andere kant van de twee Repartition Streams-uitwisselingen, te zien in de oranje en groene takken. Deze (linker) kant van de beurs staat bekend als de consument kant, omdat de hier bijgevoegde threads lezen (consumerende) rijen zijn. De acht paarse draadjes zijn consumenten van gegevens op de twee Repartition Streams-uitwisselingen.
De linkerkant van de paarse tak toont rijen die worden geschreven naar de producent kant van een Gather Streams-uitwisseling. De dezelfde acht threads (dat zijn consumenten op de Repartition Streams-beurzen) voeren een producer uit rol hier.
Elke thread in de paarse vertakking voert elke operator in de vertakking uit, net zoals een enkele thread elke bewerking uitvoert in een serieel uitvoeringsplan. Het belangrijkste verschil is dat er acht threads tegelijk actief zijn, die elk op een bepaald moment aan een andere rij werken en verschillende instanties gebruiken. van de queryplan-operators.
Het stroomaggregaat in deze tak is een algemeen totaal. Het combineert de gedeeltelijke (lokale) aggregaten die zijn berekend in de groene tak (denk aan het voorbeeld van een telling van 432 in de ene thread en 568 in de andere) om een gecombineerd totaal voor elke product-ID te produceren. De knopinfo van Planverkenner toont de globale resultaatuitdrukking, gelabeld Expr1004:
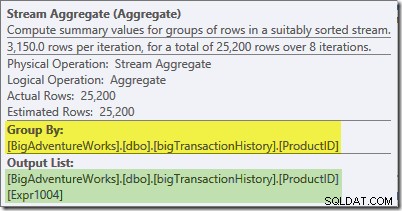
Het juiste globale resultaat per product-ID wordt berekend door de gedeeltelijke aggregaten op te tellen, zoals het tabblad Uitdrukkingen illustreert:
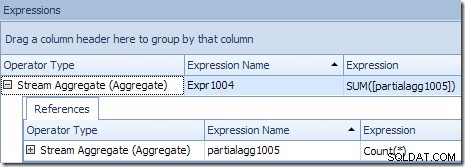
Om ons (denkbeeldige) voorbeeld voort te zetten:het juiste resultaat van 1.000 rijen voor product-ID #1 wordt verkregen door de twee subtotalen van 432 en 568 bij elkaar op te tellen.
Elk van de acht paarse vertakkingsthreads leest gegevens van de consumentenkant van de twee Gather Streams-uitwisselingen, berekent de globale aggregaten, voert de Merge Join uit op product-ID en voegt rijen toe aan de Gather Streams-uitwisseling helemaal links van de paarse vertakking. Het kernproces verschilt niet veel van een gewoon serieel plan; de verschillen zitten in waar rijen worden gelezen, waar ze naartoe worden gestuurd en hoe rijen worden verdeeld tussen de threads...
Rijverdeling wisselen
De oplettende lezer zal zich op dit punt een aantal details afvragen. Hoe slaagt de paarse tak erin om correcte resultaten te berekenen per product-ID maar de groene tak niet (resultaten voor dezelfde product-ID waren verspreid over veel threads)? Als er acht afzonderlijke merge-joins zijn (één per thread), hoe garandeert SQL Server dan dat rijen die worden samengevoegd, op hetzelfde exemplaar terechtkomen van de join?
Beide vragen kunnen worden beantwoord door te kijken naar de manier waarop de twee Repartition Streams routerijen uitwisselen van de producentenkant (in de groene en oranje tak) naar de consumentenkant (in de paarse tak). We zullen eerst kijken naar de Repartition Streams-uitwisseling die grenst aan de oranje en paarse takken:
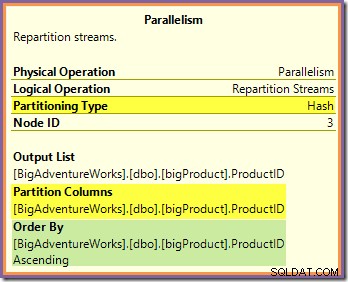
Deze uitwisseling routeert inkomende rijen (van de oranje tak) met behulp van een hash-functie die is toegepast op de product-ID-kolom. Het effect is dat alle rijen voor een bepaalde product-ID gegarandeerd zijn om naar dezelfde paars-takdraad te worden geleid. De oranje en paarse draden weten niets van deze routing; dit alles wordt intern afgehandeld door de centrale.
Het enige dat de oranje threads weten, is dat ze rijen terugsturen naar de bovenliggende iterator die erom heeft gevraagd (de producentenkant van de uitwisseling). Evenzo, alle paarse threads 'weten' dat ze rijen lezen uit een gegevensbron. De centrale bepaalt in welk pakket een inkomende rij met oranje draden wordt geplaatst, en het kan een van de acht kandidaatpakketten zijn. Op dezelfde manier bepaalt de centrale uit welk pakket een rij moet worden gelezen om te voldoen aan een leesverzoek van een paarse draad.
Pas op dat u geen mentaal beeld krijgt van een bepaalde oranje (producent)draad die rechtstreeks is gekoppeld aan een bepaalde paarse (consumenten)draad. Zo werkt dit queryplan niet. Een sinaasappelproducent mag uiteindelijk sturen ze rijen naar alle paarse consumenten - de routering hangt volledig af van de waarde van de product-ID-kolom in elke rij die wordt verwerkt.
Houd er ook rekening mee dat een pakket met rijen bij de centrale alleen wordt overgedragen als het vol is (of wanneer de kant van de producent geen gegevens meer heeft). Stel je voor dat de uitwisseling pakketten rij voor rij vult, waarbij rijen voor een bepaald pakket afkomstig kunnen zijn van een van de (oranje) threads aan de producentzijde. Zodra een pakket vol is, wordt het doorgegeven aan de consumentenkant, waar een bepaalde (paarse) consumentendraad kan beginnen met lezen.
De uitwisseling van Repartition Streams die grenst aan de groene en paarse takken werkt op een vergelijkbare manier:
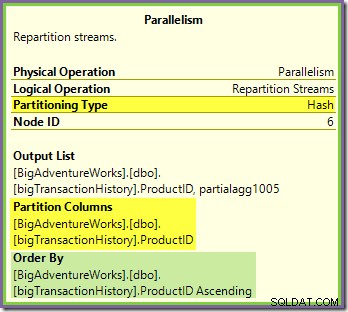
Rijen worden gerouteerd naar pakketten in deze uitwisseling met behulp van de dezelfde hash-functie op de dezelfde partitiekolom wat betreft de oranje-paarse uitwisseling die we eerder hebben gezien. Dit betekent dat beide Repartition Streams wisselt routerijen met dezelfde product-ID uit naar dezelfde paarse vertakkingsdraad.
Dit legt uit hoe de Stream Aggregate in de paarse tak globale aggregaten kan berekenen - als een rij met een bepaald product-ID wordt gezien op een bepaalde paarse-takdraad, zal die draad gegarandeerd alle rijen voor die product-ID zien (en geen andere thread wel).
De common exchange-partitioneringskolom is ook de join-sleutel voor de merge-join, dus alle rijen die mogelijk kunnen joinen, worden gegarandeerd door dezelfde (paarse) thread verwerkt.
Een laatste ding om op te merken is dat beide uitwisselingen orderbehoudend zijn (ook wel 'samenvoegen' genoemd) uitwisselingen, zoals weergegeven in het kenmerk Order By in de tooltips. Dit voldoet aan de merge-join-vereiste dat invoerrijen worden gesorteerd op de join-sleutels. Merk op dat uitwisselingen nooit zelf rijen sorteren, ze kunnen alleen worden geconfigureerd om behouden bestaande bestelling.
Draad nul
Het laatste deel van het uitvoeringsplan ligt links van de Gather Streams-beurs. Het draait altijd op een enkele thread - dezelfde die werd gebruikt om het hele regulier serieel plan uit te voeren. Deze thread heeft altijd het label 'Thread 0' in uitvoeringsplannen en wordt soms de 'coordinator'-thread genoemd (een aanduiding die ik niet bijzonder nuttig vind).
Thread zero leest rijen van de consumentenkant (links) van de Gather Streams-uitwisseling en stuurt ze terug naar de client. Er zijn geen thread zero iterators behalve de uitwisseling in dit voorbeeld, maar als die er waren, zouden ze allemaal op dezelfde enkele thread draaien. Merk op dat de Gather Streams ook een samenvoegingsuitwisseling is (het heeft een Order By-attribuut):

Complexere parallelle plannen kunnen andere seriële uitvoeringszones bevatten dan die aan de linkerkant van de laatste Gather Streams-uitwisseling. Deze seriële zones worden niet in thread nul uitgevoerd, maar dat is een detail om een andere keer te onderzoeken.
Gereserveerde en gebruikte threads opnieuw bezocht
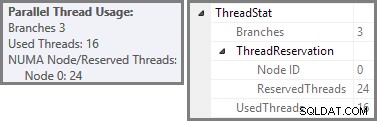
We hebben gezien dat dit parallelle plan drie takken bevat. Dit verklaart waarom SQL Server gereserveerd 24 draden (drie takken bij DOP 8). De vraag is waarom er in de bovenstaande schermafbeelding slechts 16 threads als 'gebruikt' worden gerapporteerd.
Het antwoord bestaat uit twee delen. Het eerste deel is niet van toepassing op dit plan, maar het is toch belangrijk om te weten. Het aantal gerapporteerde vertakkingen is het maximale aantal dat gelijktijdig kan worden uitgevoerd .
Zoals u wellicht weet, 'blokkeren' bepaalde planoperators - wat betekent dat ze al hun invoerrijen moeten verbruiken voordat ze de eerste uitvoerrij kunnen produceren. Het duidelijkste voorbeeld van een blokkerende (ook wel stop-and-go)-operator is Sorteren. Een sortering kan de eerste rij niet in gesorteerde volgorde retourneren voordat deze elke invoerrij heeft gezien, omdat de laatste invoerrij als eerste kan worden gesorteerd.
Operators met meerdere ingangen (bijvoorbeeld joins en unions) kunnen blokkerend zijn met betrekking tot de ene ingang, maar niet-blokkerend ('pipelined') met betrekking tot de andere. Een voorbeeld hiervan is hash-join - de build-invoer blokkeert, maar de probe-invoer is gepijplijnd. De build-invoer blokkeert omdat het de hash-tabel creëert waartegen proberijen worden getest.
De aanwezigheid van blokkerende operators betekent dat een of meer parallelle vertakkingen mogelijk gegarandeerd voltooid zijn voordat anderen kunnen beginnen. Waar dit gebeurt, kan SQL Server hergebruiken de threads die worden gebruikt om een voltooide vertakking te verwerken voor een latere vertakking in de reeks. SQL Server is erg conservatief wat betreft het reserveren van threads, dus alleen branches die gegarandeerd zijn om te voltooien voordat een ander begint, maak gebruik van deze optimalisatie voor het reserveren van threads. Ons zoekplan bevat geen blokkerende operators, dus het gerapporteerde aantal vertakkingen is slechts het totale aantal vertakkingen.
Het tweede deel van het antwoord is dat threads nog steeds kunnen worden hergebruikt als ze gebeurt om te voltooien voordat een thread in een andere branch wordt gestart. Het volledige aantal threads is in dit geval nog steeds gereserveerd, maar het werkelijke gebruik kan lager zijn. Hoeveel threads een parallel plan daadwerkelijk gebruikt, hangt onder andere af van timingproblemen en kan variëren tussen uitvoeringen.
Parallelle threads worden niet allemaal tegelijkertijd uitgevoerd, maar nogmaals, de details daarvan zullen op een andere gelegenheid moeten wachten. Laten we nog eens kijken naar het queryplan om te zien hoe threads kunnen worden hergebruikt, ondanks het ontbreken van blokkerende operators:
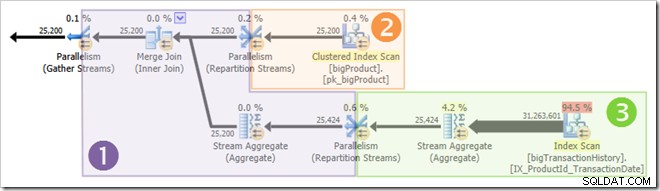
Het is duidelijk dat threads in tak één niet kunnen worden voltooid voordat threads in takken twee of drie starten, dus er is geen kans op hergebruik van threads. Tak drie is ook onwaarschijnlijk te voltooien voordat tak één of tak twee opstarten, omdat er zoveel werk te doen is (bijna 32 miljoen rijen om te aggregeren).
Tak twee is een andere zaak. Door de relatief kleine omvang van de producttabel is er een behoorlijke kans dat het filiaal zijn werk voor kan afronden tak drie wordt opgestart. Als het lezen van de producttabel geen fysieke I/O oplevert, duurt het niet lang voordat acht threads de 25.200 rijen hebben gelezen en deze naar de oranje-paarse grens Repartition Streams-uitwisseling sturen.
Dit is precies wat er gebeurde in de testruns die werden gebruikt voor de schermafbeeldingen die tot nu toe in dit bericht zijn gezien:de acht oranje takthreads waren snel genoeg voltooid om ze opnieuw te kunnen gebruiken voor de groene tak. In totaal zijn er zestien unieke threads gebruikt, dus dat meldt het uitvoeringsplan.
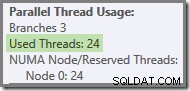
Als de query opnieuw wordt uitgevoerd met een koude cache, is de vertraging die wordt geïntroduceerd door de fysieke I/O voldoende om ervoor te zorgen dat groene vertakkingsthreads worden opgestart voordat de oranje vertakkingsthreads zijn voltooid. Er worden geen threads hergebruikt, dus het uitvoeringsplan meldt dat alle 24 gereserveerde threads in feite zijn gebruikt:
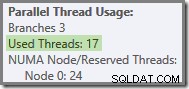
Meer in het algemeen is een willekeurig aantal 'gebruikte threads' tussen de twee uitersten (16 en 24 voor dit queryplan) mogelijk:
Merk ten slotte op dat de thread die het seriële deel van het plan links van de laatste Verzamelstreams uitvoert, niet wordt meegeteld in de parallelle draadtotalen. Het is geen extra thread die is toegevoegd om parallelle uitvoering mogelijk te maken.
Laatste gedachten
Het mooie van het uitwisselingsmodel dat door SQL Server wordt gebruikt om parallelle uitvoering te implementeren, is dat alle complexiteit van het bufferen en verplaatsen van rijen tussen threads verborgen is in uitwisselingsoperatoren (parallellisme). De rest van het plan is opgedeeld in nette 'takken', begrensd door uitwisselingen. Binnen een filiaal gedraagt elke operator zich hetzelfde als in een serieel plan - in bijna alle gevallen weten de filiaaloperators niet dat het bredere plan helemaal geen parallelle uitvoering gebruikt.
De sleutel tot het begrijpen van parallelle uitvoering is om het parallelle plan (mentaal) uit elkaar te halen bij de uitwisselingsgrenzen en om elke vertakking af te beelden als DOP-afzonderlijke serieel plannen, die allemaal gelijktijdigheid uitvoeren op een afzonderlijke subset van rijen. Onthoud in het bijzonder dat elk dergelijk serieel plan alle operators in die tak uitvoert – SQL Server doet niet voer elke operator op zijn eigen thread uit!
Om het meest gedetailleerde gedrag te begrijpen, moet je even nadenken, vooral over hoe rijen binnen uitwisselingen worden gerouteerd en hoe de engine correcte resultaten garandeert, maar dan vereisen de meeste dingen die het waard zijn om te weten een beetje nadenken, nietwaar?