Elke programmeur zal je vertellen dat het schrijven van veilige multi-threaded code moeilijk kan zijn. Het vereist grote zorgvuldigheid en een goed begrip van de technische problemen die ermee gemoeid zijn. Als database-persoon zou je kunnen denken dat dit soort moeilijkheden en complicaties niet van toepassing zijn bij het schrijven van T-SQL. Het kan dus als een schok komen om te beseffen dat T-SQL-code ook kwetsbaar is voor het soort race-omstandigheden en andere gegevensintegriteitsrisico's die het meest worden geassocieerd met multi-threaded programmeren. Dit is waar, of we het nu hebben over een enkele T-SQL-instructie of een groep verklaringen ingesloten in een expliciete transactie.
De kern van het probleem is het feit dat databasesystemen het mogelijk maken om meerdere transacties tegelijkertijd uit te voeren. Dit is een bekende (en zeer wenselijke) stand van zaken, maar toch gaat een groot deel van de productie-T-SQL-code er stilletjes van uit dat de onderliggende gegevens niet veranderen tijdens het uitvoeren van een transactie of een enkele DML-instructie zoals SELECT , INSERT , UPDATE , DELETE , of MERGE .
Zelfs als de auteur van de code zich bewust is van de mogelijke effecten van gelijktijdige gegevenswijzigingen, wordt te vaak aangenomen dat het gebruik van expliciete transacties meer bescherming biedt dan eigenlijk gerechtvaardigd is. Deze aannames en misvattingen kunnen subtiel zijn en zijn zeker in staat om zelfs ervaren databasebeoefenaars te misleiden.
Nu zijn er gevallen waarin deze problemen in praktische zin niet veel uitmaken. De database kan bijvoorbeeld alleen-lezen zijn, of er kan een andere echte garantie zijn dat niemand anders de onderliggende gegevens zal wijzigen terwijl we ermee werken. Evenzo is het mogelijk dat de bewerking in kwestie niet vereist resultaten die exact . zijn juist; onze gegevensconsumenten zijn misschien heel tevreden met een geschat resultaat (zelfs een resultaat dat niet de toegewijde status van de database op elke vertegenwoordigt tijdstip).
Gelijktijdigheidsproblemen
De kwestie van interferentie tussen gelijktijdig uitgevoerde taken is een bekend probleem voor applicatieontwikkelaars die in programmeertalen zoals C# of Java werken. De oplossingen zijn talrijk en gevarieerd, maar omvatten over het algemeen het gebruik van atomaire operaties of het verkrijgen van een wederzijds uitsluitende hulpbron (zoals een slot ) terwijl een gevoelige bewerking wordt uitgevoerd. Als de juiste voorzorgsmaatregelen niet worden genomen, zijn de waarschijnlijke resultaten beschadigde gegevens, een fout of misschien zelfs een volledige crash.
Veel van dezelfde concepten (bijv. atomaire operaties en sloten) bestaan in de databasewereld, maar helaas hebben ze vaak cruciale verschillen in betekenis . De meeste databasemensen zijn op de hoogte van de ACID-eigenschappen van databasetransacties, waarbij de A staat voor atomic . SQL Server gebruikt ook sloten (en andere apparaten voor wederzijdse uitsluiting intern). Geen van deze termen betekent precies wat een ervaren C#- of Java-programmeur redelijkerwijs zou verwachten, en veel databaseprofessionals hebben ook een verward begrip van deze onderwerpen (zoals een snelle zoekopdracht met uw favoriete zoekmachine zal bewijzen).
Ik herhaal, soms zullen deze problemen geen praktische zorg zijn. Als u een query schrijft om het aantal actieve bestellingen in een databasesysteem te tellen, hoe belangrijk is het dan als de telling een beetje uit de pas loopt? Of als het de status van de database op een ander moment weerspiegelt?
Het is gebruikelijk dat echte systemen een afweging maken tussen gelijktijdigheid en consistentie (zelfs als de ontwerper zich daar op dat moment niet van bewust was - op de hoogte compromissen zijn misschien een zeldzamer dier). Echte systemen werken vaak goed genoeg , waarbij eventuele anomalieën van korte duur zijn of als onbelangrijk worden beschouwd. Een gebruiker die een inconsistente status op een webpagina ziet, lost het probleem vaak op door de pagina te vernieuwen. Als het probleem wordt gemeld, wordt het hoogstwaarschijnlijk gesloten als niet-reproduceerbaar. Ik zeg niet dat dit een wenselijke situatie is, ik erken alleen dat het gebeurt.
Desalniettemin is het enorm nuttig om gelijktijdigheidskwesties op een fundamenteel niveau te begrijpen. Als we ons hiervan bewust zijn, kunnen we correct (of geïnformeerd correct-genoeg) T-SQL als de omstandigheden dit vereisen. Wat nog belangrijker is, het stelt ons in staat om te voorkomen dat we T-SQL schrijven die de logische integriteit van onze gegevens in gevaar zou kunnen brengen.
Maar SQL Server biedt ACID-garanties!
Ja, dat doet het, maar ze zijn niet altijd wat je zou verwachten, en ze beschermen niet alles. Vaker wel dan niet lezen mensen veel meer in ACID dan gerechtvaardigd is.
De meest verkeerd begrepen componenten van het ACID-acroniem zijn de woorden Atomic, Consistent en Isolated - daar komen we zo op terug. De andere, Duurzaam , is intuïtief genoeg, zolang u het zich herinnert, is het alleen van toepassing op persistente (herstelbare) gebruiker gegevens.
Dat gezegd hebbende, begint SQL Server 2014 de grenzen van de eigenschap Durable enigszins te vervagen met de introductie van algemene vertraagde duurzaamheid en in-memory OLTP-schema-only duurzaamheid. Ik noem ze alleen voor de volledigheid, we zullen deze nieuwe features niet verder bespreken. Laten we verder gaan met de meer problematische ACID-eigenschappen:
De atoomeigenschap
Veel programmeertalen bieden atomaire bewerkingen die kan worden gebruikt om te beschermen tegen race-omstandigheden en andere ongewenste gelijktijdigheidseffecten, waarbij meerdere uitvoeringsdraden toegang kunnen krijgen tot gedeelde gegevensstructuren of deze kunnen wijzigen. Voor de applicatieontwikkelaar wordt een atomaire operatie geleverd met een expliciete garantie van volledige isolatie van de effecten van andere gelijktijdige verwerking in een programma met meerdere threads.
Een analoge situatie doet zich voor in de databasewereld, waar meerdere T-SQL-query's gelijktijdig toegang krijgen tot gedeelde gegevens (d.w.z. de database) van verschillende threads en deze wijzigen. Merk op dat we het hier niet hebben over parallelle queries; gewone single-threaded queries zijn routinematig gepland om gelijktijdig te draaien binnen SQL Server op aparte worker-threads.
Helaas is de atomaire eigenschap van SQL-transacties garandeert alleen dat gegevenswijzigingen die binnen een transactie worden uitgevoerd als een geheel slagen of mislukken . Niets meer dan dat. Er is zeker geen garantie voor volledige isolatie van de effecten van andere gelijktijdige verwerking. Merk ook terloops op dat de atomaire transactie-eigenschap niets zegt over garanties over lezen gegevens.
Enkele verklaringen
Er is ook niets bijzonders aan een enkele verklaring in SQL-server. Waar een expliciet bevattende transactie (BEGIN TRAN...COMMIT TRAN ) niet bestaat, wordt er nog steeds een enkele DML-instructie uitgevoerd binnen een autocommit-transactie. Dezelfde ACID-garanties zijn van toepassing op een enkele verklaring, en ook dezelfde beperkingen. In het bijzonder wordt een enkele verklaring niet geleverd met speciale garanties dat gegevens niet zullen veranderen terwijl ze worden verwerkt.
Overweeg de volgende speelgoedvraag van AdventureWorks:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); De query is bedoeld om informatie weer te geven over de Order die als eerste is gerangschikt op Aantal. Het uitvoeringsplan is als volgt:
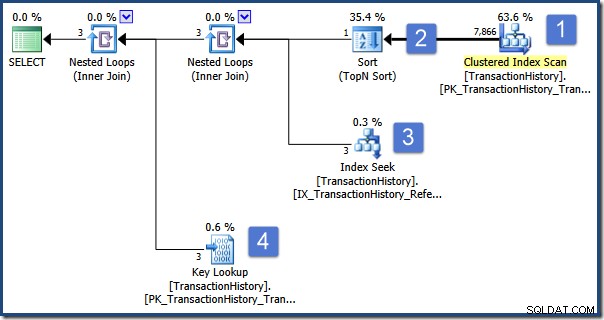
De belangrijkste operaties in dit plan zijn:
- Scan de tabel om rijen met het vereiste transactietype te vinden
- Zoek de Order-ID die het hoogst sorteert volgens de specificatie in de subquery
- Zoek de rijen (in dezelfde tabel) met de geselecteerde Order-ID met behulp van een niet-geclusterde index
- Zoek de resterende kolomgegevens op met behulp van de geclusterde index
Stel je nu voor dat een gelijktijdige gebruiker Order 495 wijzigt, het transactietype verandert van P in W, en die wijziging in de database vastlegt. Het toeval wil dat deze wijziging wordt doorgevoerd terwijl onze query de sorteerbewerking uitvoert (stap 2).
Wanneer de sortering is voltooid, vindt de indexzoekopdracht bij stap 3 de rijen met de geselecteerde Order-ID (die toevallig 495) is en haalt de Key Lookup bij stap 4 de resterende kolommen op uit de basistabel (waar het transactietype nu W is) .
Deze opeenvolging van gebeurtenissen betekent dat onze zoekopdracht een schijnbaar onmogelijk resultaat oplevert:

In plaats van orders te vinden met transactietype P als de opgegeven zoekopdracht, tonen de resultaten transactietype W.
De hoofdoorzaak is duidelijk:onze query ging er impliciet van uit dat de gegevens niet konden veranderen terwijl onze single-statement query aan de gang was. In dit geval was de kans in dit geval relatief groot vanwege de blokkerende soort, maar in het algemeen kan dezelfde soort race-conditie optreden in elk stadium van de uitvoering van de query. Natuurlijk zijn de risico's meestal groter met meer gelijktijdige wijzigingen, grotere tabellen en waar blokkerende operators voorkomen in het queryplan.
Een andere hardnekkige mythe in hetzelfde algemene gebied is dat MERGE verdient de voorkeur boven aparte INSERT , UPDATE en DELETE verklaringen omdat de enkelvoudige verklaring MERGE is atomair. Dat is natuurlijk onzin. Op dit soort redeneringen komen we later in de serie terug.
De algemene boodschap op dit punt is dat, tenzij expliciete stappen worden ondernomen om anders te garanderen, gegevensrijen en indexitems op elk moment tijdens het uitvoeringsproces kunnen veranderen, van positie kunnen veranderen of volledig kunnen verdwijnen. Een mentaal beeld van constante en willekeurige veranderingen in de database is goed om in gedachten te houden bij het schrijven van T-SQL-query's.
De consistentie-eigenschap
Het tweede woord van het ACID-acroniem heeft ook een reeks mogelijke interpretaties. In een SQL Server-database betekent Consistentie alleen dat een transactie de database verlaat in een staat die geen actieve beperkingen schendt. Het is belangrijk om volledig te beseffen hoe beperkt die verklaring is:de enige ACID-garanties voor gegevensintegriteit en logische consistentie worden geboden door actieve beperkingen.
SQL Server biedt een beperkt aantal beperkingen om logische integriteit af te dwingen, waaronder PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE , en NOT NULL . Deze worden allemaal gegarandeerd vervuld op het moment dat een transactie wordt uitgevoerd. Bovendien garandeert SQL Server de fysieke integriteit van de database te allen tijde natuurlijk.
De ingebouwde beperkingen zijn niet altijd voldoende om alle bedrijfs- en data-integriteitsregels af te dwingen die we zouden willen. Creatief zijn met de standaardvoorzieningen is zeker mogelijk, maar deze worden al snel complex en kunnen leiden tot de opslag van dubbele data.
Als gevolg hiervan bevatten de meeste echte databases ten minste enkele T-SQL-routines die zijn geschreven om aanvullende regels af te dwingen, bijvoorbeeld in opgeslagen procedures en triggers. De verantwoordelijkheid om ervoor te zorgen dat deze code correct werkt, ligt volledig bij de auteur - de eigenschap Consistentie biedt geen specifieke beveiligingen.
Om dit punt te benadrukken, moeten pseudo-beperkingen die zijn geschreven in T-SQL correct werken, ongeacht welke gelijktijdige wijzigingen er plaatsvinden. Een applicatieontwikkelaar kan zo'n gevoelige operatie beschermen met een lock-instructie. Het dichtst dat T-SQL-programmeurs hebben voor die faciliteit voor risicovolle opgeslagen procedure en triggercode is de relatief zelden gebruikte sp_getapplock systeem opgeslagen procedure. Dat wil niet zeggen dat het de enige optie is, of zelfs de voorkeur heeft, alleen dat het bestaat en in sommige omstandigheden de juiste keuze kan zijn.
De isolatie-eigenschap
Dit is gemakkelijk de meest verkeerd begrepen van de ACID-transactie-eigenschappen.
In principe een volledig geïsoleerd transactie wordt uitgevoerd als de enige taak die tijdens de levensduur van de database wordt uitgevoerd. Andere transacties kunnen pas starten als de huidige transactie volledig is voltooid (d.w.z. vastgelegd of teruggedraaid). Op deze manier uitgevoerd, zou een transactie echt een atomaire operatie zijn , in de strikte zin die een niet-databasepersoon zou toeschrijven aan de zin.
In de praktijk werken databasetransacties in plaats daarvan met een mate van isolatie gespecificeerd door het momenteel effectieve transactie-isolatieniveau (dat evenzeer van toepassing is op stand-alone verklaringen, onthoud). Dit compromis (de graad van isolatie) is het praktische gevolg van de eerder genoemde afwegingen tussen gelijktijdigheid en correctheid. Een systeem dat transacties letterlijk één voor één verwerkt, zonder overlap in de tijd, zou volledige isolatie bieden, maar de algehele systeemdoorvoer zou waarschijnlijk slecht zijn.
Volgende keer
Het volgende deel in deze serie gaat verder met het onderzoek van gelijktijdigheidsproblemen, ACID-eigenschappen en transactie-isolatie met een gedetailleerde blik op het serialiseerbare isolatieniveau, nog een voorbeeld van iets dat misschien niet betekent wat u denkt dat het doet.
[ Zie de index voor de hele serie ]