Een paar weken geleden was het SQLskills-team in Tampa voor ons Performance Tuning Immersion Event (IE2) en ik behandelde baselines. Baselines is een onderwerp dat mij na aan het hart ligt, omdat ze om vele redenen zo waardevol zijn. Twee van die redenen, die ik altijd aanhaal, of het nu gaat om lesgeven of werken met klanten, zijn het gebruik van baselines om problemen met de prestaties op te lossen, en vervolgens ook trending gebruik en het verstrekken van schattingen van de capaciteitsplanning. Maar ze zijn ook essentieel bij het afstemmen of testen van prestaties, of u uw bestaande prestatiestatistieken nu als basislijnen beschouwt of niet.
Tijdens de module heb ik verschillende bronnen voor gegevens bekeken, zoals Performance Monitor, de DMV's en trace- of XE-gegevens, en er kwam een vraag naar voren met betrekking tot het laden van gegevens. De vraag was met name of het beter is om gegevens in een tabel zonder indexen te laden en deze vervolgens te maken wanneer u klaar bent, in plaats van de indexen op hun plaats te houden tijdens het laden van gegevens. Mijn antwoord was:"Normaal gesproken wel". Mijn persoonlijke ervaring is dat dit altijd het geval is, maar je weet nooit welk voorbehoud of eenmalig scenario iemand kan tegenkomen waarbij de prestatieverandering niet is wat werd verwacht, en zoals bij alle prestatievragen, je weet het pas zeker als je het test. Totdat je een basislijn voor de ene methode vastlegt en vervolgens kijkt of de andere methode die basislijn verbetert, is het alleen maar gissen. Ik dacht dat het leuk zou zijn om te testen dit scenario, niet alleen om te bewijzen wat ik verwacht dat waar is, maar ook om te laten zien welke statistieken ik zou onderzoeken, waarom en hoe ik ze kan vastleggen. Als je eerder prestatietests hebt gedaan, is dit waarschijnlijk ouderwets. van jullie die nieuw zijn in de praktijk, zal ik het proces doorlopen dat ik volg om je op weg te helpen. Realiseer je dat er veel manieren zijn om het antwoord af te leiden op:"Welke methode is beter?" Ik verwacht dat je dit proces zult volgen, het zult aanpassen en het in de loop van de tijd de jouwe zult maken.
Wat probeer je te bewijzen?
De eerste stap is om te beslissen wat u precies aan het testen bent. In ons geval is het eenvoudig:is het sneller om gegevens in een lege tabel te laden en vervolgens de indexen toe te voegen, of is het sneller om de indexen in de tabel te hebben tijdens het laden van gegevens? Maar we kunnen hier wat variatie toevoegen als we willen. Houd rekening met de tijd die nodig is om gegevens in een heap te laden en vervolgens de geclusterde en niet-geclusterde indexen te maken, versus de tijd die nodig is om gegevens in een geclusterde index te laden en vervolgens de niet-geclusterde indexen te maken. Is er een verschil in prestatie? Zou de clusteringsleutel een factor zijn? Ik verwacht dat de gegevensbelasting ervoor zal zorgen dat bestaande niet-geclusterde indexen fragmenteren, dus misschien wil ik zien welke impact het opnieuw opbouwen van de indexen na de belasting heeft op de totale duur. Het is belangrijk om deze stap zoveel mogelijk te volgen en heel specifiek te zijn over wat u wilt meten, omdat dit bepaalt welke gegevens u vastlegt. Voor ons voorbeeld zijn onze vier tests:
Test 1: Laad gegevens op een hoop, maak de geclusterde index, maak de niet-geclusterde indexen
Test 2: Laad gegevens in een geclusterde index, maak de niet-geclusterde indexen
Test 3: Maak de geclusterde index en niet-geclusterde indexen, laad de gegevens
Test 4: Maak de geclusterde index en niet-geclusterde indexen, laad de gegevens, herbouw de niet-geclusterde indexen
Wat moet u weten?
In ons scenario is onze primaire vraag "welke methode is het snelst"? Daarom willen we de duur meten en daarvoor moeten we een begintijd en een eindtijd vastleggen. We zouden het daarbij kunnen laten, maar misschien willen we weten hoe het gebruik van hulpbronnen eruit ziet voor elke methode, of misschien willen we weten wat de hoogste wachttijden zijn, of het aantal transacties, of het aantal deadlocks. Welke gegevens het meest interessant en relevant zijn, hangt af van de processen die u vergelijkt. Het aantal transacties vastleggen is niet zo interessant voor onze dataload; maar voor een codewijziging kan het zijn. Omdat we indexen maken en opnieuw opbouwen, ben ik geïnteresseerd in hoeveel IO elke methode genereert. Hoewel de totale duur uiteindelijk waarschijnlijk de beslissende factor is, kan het nuttig zijn om naar IO te kijken om niet alleen te begrijpen welke optie de meeste IO genereert, maar ook of de databaseopslag presteert zoals verwacht.
Waar zijn de gegevens die u nodig hebt?
Nadat u hebt bepaald welke gegevens u nodig heeft, kunt u beslissen waar deze worden vastgelegd. We zijn geïnteresseerd in de duur, dus we willen de tijd vastleggen waarop elke test voor het laden van gegevens begint en wanneer deze eindigt. We zijn ook geïnteresseerd in IO en we kunnen deze gegevens van meerdere locaties halen - Prestatiemetertellers en de sys.dm_io_virtual_file_stats DMV komen voor de geest.
Begrijp dat we deze gegevens handmatig kunnen krijgen. Voordat we een test uitvoeren, kunnen we selecteren tegen sys.dm_io_virtual_file_stats en de huidige waarden opslaan in een bestand. We kunnen de tijd noteren en dan de test starten. Als het klaar is, noteren we opnieuw de tijd, bevragen we sys.dm_io_virtual_file_stats opnieuw en berekenen we verschillen tussen waarden om IO te meten.
Er zijn tal van tekortkomingen in deze methodologie, namelijk dat het veel ruimte laat voor fouten; wat als u vergeet de starttijd te noteren of bestandsstatistieken vast te leggen voordat u begint? Een veel betere oplossing is om niet alleen de uitvoering van het script, maar ook het vastleggen van gegevens te automatiseren. We kunnen bijvoorbeeld een tabel maken met onze testinformatie - een beschrijving van wat de test is, hoe laat deze is begonnen en hoe laat deze is voltooid. We kunnen de bestandsstatistieken in dezelfde tabel opnemen. Als we andere statistieken verzamelen, kunnen we die aan de tabel toevoegen. Of het is misschien makkelijker om een aparte tabel te maken voor elke set gegevens die we vastleggen. Als we bijvoorbeeld bestandsstatistieken in een andere tabel opslaan, moeten we elke test een unieke id geven, zodat we onze test kunnen matchen met de juiste bestandsstatistieken. Bij het vastleggen van bestandsstatistieken moeten we de waarden voor onze database vastleggen voordat we beginnen, en daarna, en het verschil berekenen. We kunnen die informatie dan opslaan in een eigen tabel, samen met de unieke test-ID.
Een voorbeeldoefening
Voor deze test heb ik een lege kopie gemaakt van de Sales.SalesOrderHeader-tabel met de naam Sales.Big_SalesOrderHeader, en ik heb een variant van een script gebruikt dat ik in mijn partitioneringsbericht heb gebruikt om gegevens in de tabel te laden in batches van ongeveer 25.000 rijen. U kunt het script voor het laden van gegevens hier downloaden. Ik heb het vier keer uitgevoerd voor elke variatie en ik heb ook het totale aantal ingevoegde rijen gevarieerd. Voor de eerste set tests heb ik 20 miljoen rijen ingevoegd en voor de tweede set 60 miljoen rijen. De duurgegevens zijn niet verrassend:
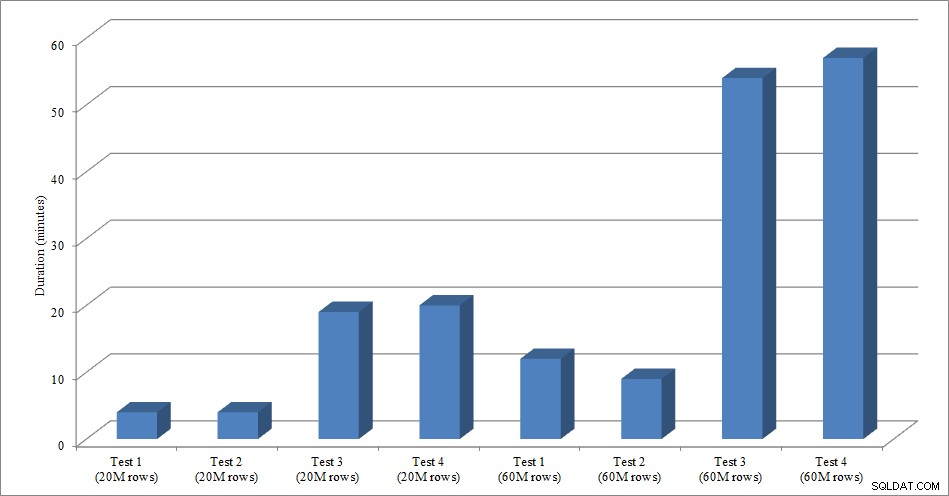
Duur gegevens laden
Het laden van gegevens, zonder de niet-geclusterde indexen, gaat veel sneller dan het laden met de niet-geclusterde indexen die al aanwezig zijn. Wat ik wel interessant vond, is dat voor het laden van 20 miljoen rijen de totale duur ongeveer hetzelfde was tussen Test 1 en Test 2, maar Test 2 was sneller bij het laden van 60 miljoen rijen. In onze test was onze clustersleutel SalesOrderID, wat een identiteit is en daarom een goede clustersleutel voor onze belasting, aangezien deze oplopend is. Als we in plaats daarvan een clustersleutel hadden die een GUID was, zou de laadtijd hoger kunnen zijn vanwege willekeurige invoegingen en paginasplitsingen (een andere variatie die we konden testen).
Nabootsen de IO-gegevens de trend in duurgegevens? Ja, met de verschillen als de indexen al aanwezig zijn, of niet, zelfs nog meer overdreven:
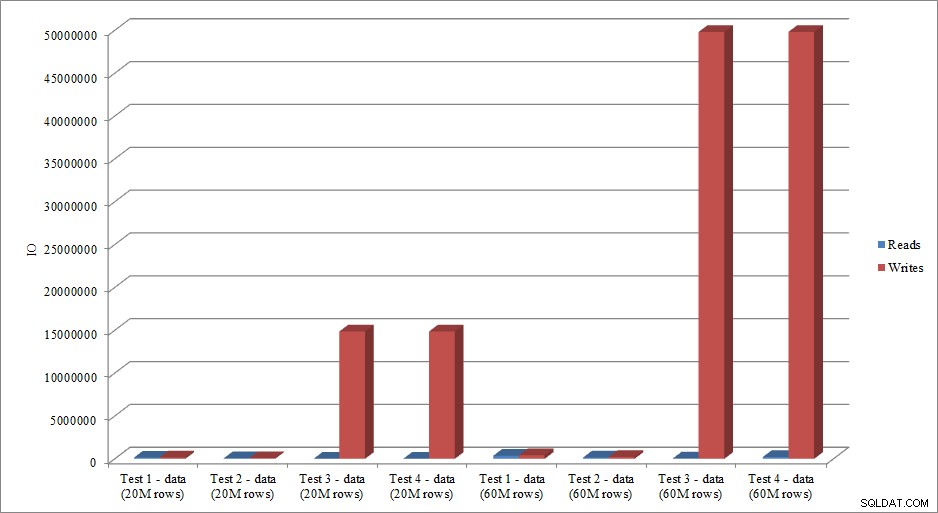
Gegevens laden lezen en schrijven
De methode die ik hier heb gepresenteerd voor het testen van prestaties, of het meten van prestatieveranderingen op basis van wijzigingen in code, ontwerp, enz., is slechts één optie voor het vastleggen van basislijninformatie. In sommige scenario's kan dit overdreven zijn. Als u één query heeft die u probeert af te stemmen, kan het instellen van dit proces om gegevens vast te leggen langer duren dan het zou zijn om de query aan te passen! Als u enige hoeveelheid query-afstemming hebt uitgevoerd, heeft u waarschijnlijk de gewoonte om STATISTICS IO- en STATISTICS TIME-gegevens vast te leggen, samen met het queryplan, en vervolgens de uitvoer te vergelijken terwijl u wijzigingen aanbrengt. Ik doe dit al jaren, maar ik heb onlangs een betere manier ontdekt... SQL Sentry Plan Explorer PRO. Nadat ik alle belastingtests had voltooid die ik hierboven heb beschreven, heb ik zelfs mijn tests opnieuw uitgevoerd via PE en ontdekte dat ik de informatie kon vastleggen die ik wilde, zonder dat ik mijn tabellen voor gegevensverzameling hoefde op te zetten.
Binnen Plan Explorer PRO heb je de mogelijkheid om het daadwerkelijke plan op te halen - PE voert de query uit op de geselecteerde instantie en database en retourneert het plan. En daarmee krijg je alle andere geweldige gegevens die PE biedt (tijdstatistieken, lezen en schrijven, IO per tabel), evenals de wachtstatistieken, wat een mooi voordeel is. Met ons voorbeeld begon ik met de eerste test - het maken van de heap, het laden van gegevens en het toevoegen van de geclusterde index en niet-geclusterde indexen - en voerde vervolgens de optie Get Actual Plan uit. Toen het voltooid was, heb ik mijn scripttest 2 aangepast en de optie Get Actual Plan opnieuw uitgevoerd. Ik herhaalde dit voor de derde en vierde test, en toen ik klaar was, had ik dit:
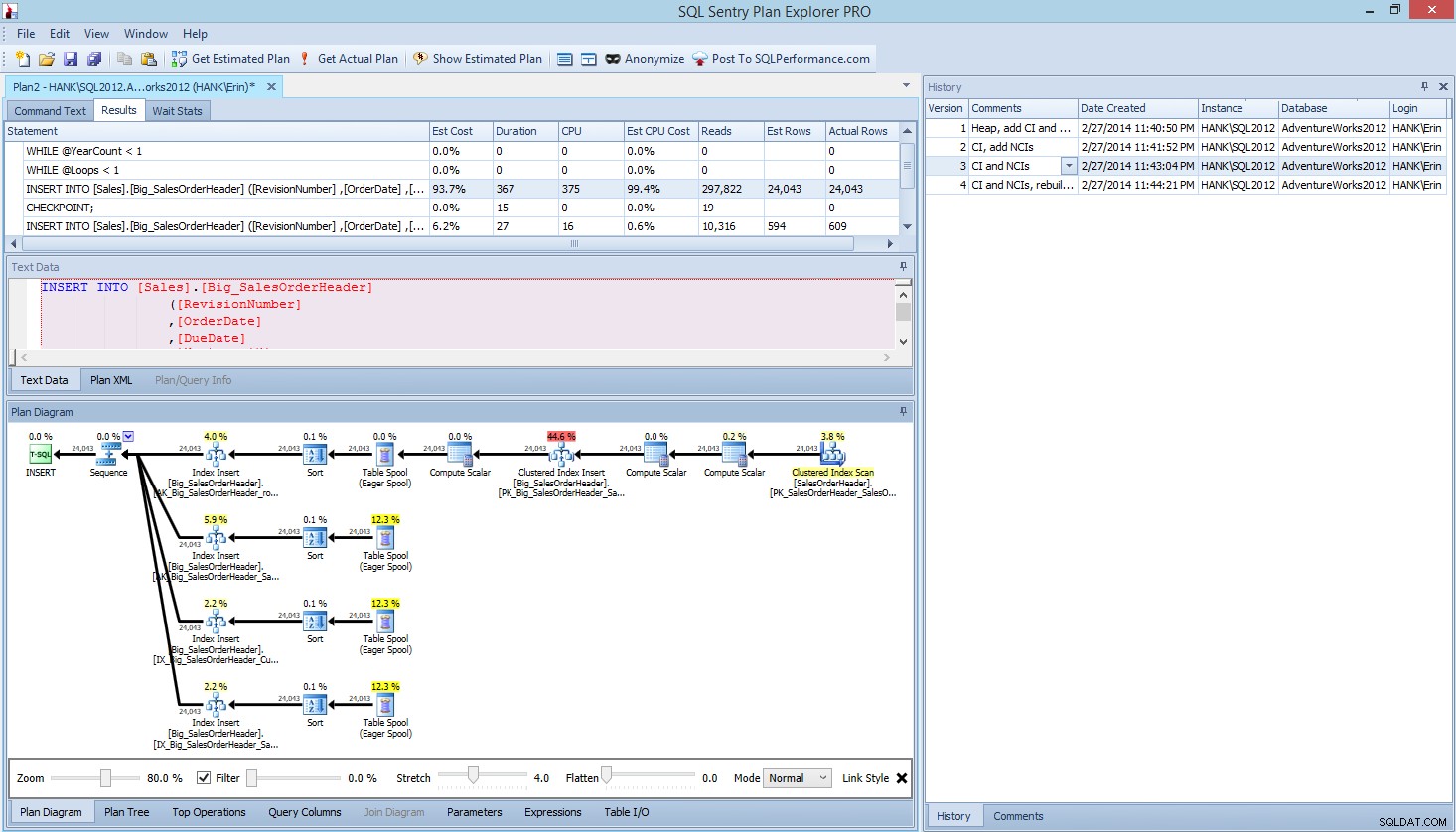
Plan Explorer PRO-weergave na het uitvoeren van 4 tests
Zie je het geschiedenisvenster aan de rechterkant? Elke keer dat ik mijn code aanpaste en het eigenlijke plan heroverde, werd een nieuwe set informatie opgeslagen. Ik heb de mogelijkheid om deze gegevens op te slaan als een .pesession-bestand om te delen met een ander lid van mijn team, of later terug te gaan en door de verschillende tests te bladeren, en indien nodig in te zoomen op verschillende verklaringen binnen de batch, waarbij ik naar verschillende statistieken kijk, zoals zoals duur, CPU en IO. In de bovenstaande schermafbeelding heb ik de INSERT uit Test 3 gemarkeerd en het queryplan toont de updates voor alle vier niet-geclusterde indexen.
Samenvatting
Zoals met zoveel taken in SQL Server, zijn er veel manieren om gegevens vast te leggen en te beoordelen wanneer u prestatietests uitvoert of afstemming uitvoert. Hoe minder handmatige inspanning u hoeft te leveren, hoe beter, omdat er meer tijd overblijft om daadwerkelijk wijzigingen aan te brengen, de impact te begrijpen en vervolgens door te gaan naar uw volgende taak. Of u nu een script aanpast om gegevens vast te leggen, of een hulpprogramma van een derde partij het voor u laat doen, de stappen die ik heb geschetst, zijn nog steeds geldig:
- Definieer wat u wilt verbeteren
- Bereik uw testen
- Bepaal welke gegevens kunnen worden gebruikt om verbetering te meten
- Beslis hoe u de gegevens vastlegt
- Stel waar mogelijk een geautomatiseerde methode in voor testen en vastleggen
- Test, evalueer en herhaal indien nodig
Veel plezier met testen!