Het toevoegen van een gefilterde index kan verrassende neveneffecten hebben op bestaande zoekopdrachten, zelfs als het lijkt alsof de nieuwe gefilterde index niets met elkaar te maken heeft. Dit bericht bekijkt een voorbeeld dat de DELETE-instructies beïnvloedt en dat resulteert in slechte prestaties en een verhoogd risico op een impasse.
Testomgeving
De volgende tabel wordt in dit bericht gebruikt:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Deze volgende instructie creëert 499.999 rijen met voorbeeldgegevens:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Dat gebruikt een Numbers-tabel als bron van opeenvolgende gehele getallen van 1 tot 499.999. Als je er geen hebt in je testomgeving, kan de volgende code worden gebruikt om er op een efficiënte manier een te maken met gehele getallen van 1 tot 1.000.000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); De basis van de latere tests is het verwijderen van rijen uit de testtabel voor een bepaalde StartDate. Om het proces van het identificeren van te verwijderen rijen efficiënter te maken, voegt u deze niet-geclusterde index toe:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); De voorbeeldgegevens
Zodra deze stappen zijn voltooid, ziet het voorbeeld er als volgt uit:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
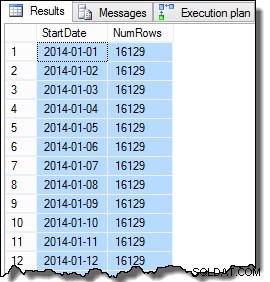
De SomeValue-kolomgegevens kunnen enigszins afwijken vanwege de pseudo-willekeurige generatie, maar dit verschil is niet belangrijk. In totaal bevatten de voorbeeldgegevens 16.129 rijen voor elk van de 31 StartDate-datums in januari 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
De laatste stap die we moeten uitvoeren om de gegevens enigszins realistisch te maken, is om de CurrentFlag-kolom in te stellen op true voor de hoogste RowID voor elke StartDate. Het volgende script voert deze taak uit:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Het uitvoeringsplan voor deze update bevat een Segment-Top-combinatie om efficiënt de hoogste RowID per dag te lokaliseren:

Merk op hoe het uitvoeringsplan weinig lijkt op de geschreven vorm van de query. Dit is een goed voorbeeld van hoe de optimizer werkt vanuit de logische SQL-specificatie, in plaats van de SQL rechtstreeks te implementeren. Mocht je je afvragen:de Eager Table Spool in dat plan is vereist voor Halloween-bescherming.
Een dag aan gegevens verwijderen
Ok, dus als de voorbereidende werkzaamheden zijn voltooid, is het de taak om rijen voor een bepaalde StartDate te verwijderen. Dit is het soort zoekopdracht dat u routinematig uitvoert op de vroegste datum in een tabel, waarbij de gegevens het einde van hun nuttige levensduur hebben bereikt.
Als we 1 januari 2014 als voorbeeld nemen, is de testverwijderquery eenvoudig:
DELETE dbo.Data WHERE StartDate = '20140101';
Het uitvoeringsplan is eveneens vrij eenvoudig, hoewel het de moeite waard is om in detail te bekijken:

Plananalyse
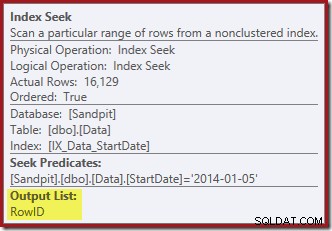
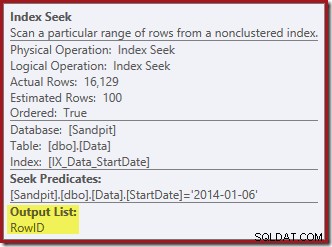
De Index Seek aan de rechterkant gebruikt de niet-geclusterde index om rijen te vinden voor de opgegeven StartDate-waarde. Het retourneert alleen de RowID-waarden die het vindt, zoals de tooltip van de operator bevestigt:
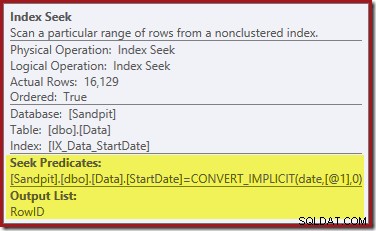
Als u zich afvraagt hoe de StartDate-index erin slaagt om de RowID te retourneren, onthoud dan dat RowID de unieke geclusterde index voor de tabel is, zodat deze automatisch wordt opgenomen in de niet-geclusterde StartDate-index.
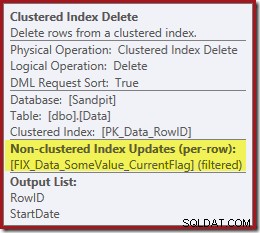
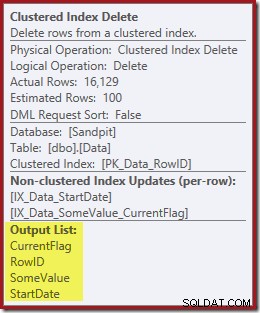
De volgende operator in het plan is de Clustered Index Delete. Dit gebruikt de RowID-waarde die is gevonden door de Index Seek om rijen te lokaliseren die moeten worden verwijderd.
De laatste operator in het plan is een Index Delete. Dit verwijdert rijen uit de niet-geclusterde index IX_Data_StartDate die gerelateerd zijn aan de RowID die is verwijderd door de Clustered Index Delete. Om deze rijen in de niet-geclusterde index te vinden, heeft de queryprocessor de StartDate nodig (de sleutel voor de niet-geclusterde index).
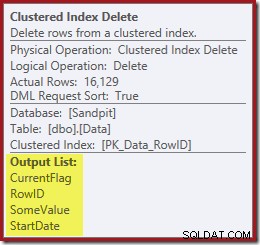
Onthoud dat de originele Index Seek niet de startdatum retourneerde, alleen de RowID. Dus hoe krijgt de queryprocessor de StartDate voor het verwijderen van de index? In dit specifieke geval heeft de optimizer misschien gemerkt dat de StartDate-waarde een constante is en heeft hij deze weg geoptimaliseerd, maar dit is niet wat er is gebeurd. Het antwoord is dat de operator Clustered Index Delete leest de StartDate-waarde voor de huidige rij en voegt deze toe aan de stream. Vergelijk de outputlijst van de hieronder getoonde geclusterde indexverwijdering met die van de indexzoekopdracht er net boven:
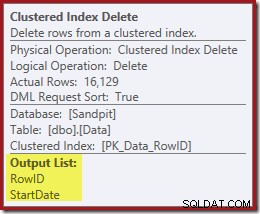
Het lijkt misschien verrassend om een Delete-operator gegevens te zien lezen, maar dit is de manier waarop het werkt. De queryprocessor weet dat hij de rij in de geclusterde index moet lokaliseren om deze te verwijderen, dus het kan net zo goed het lezen van kolommen die nodig zijn om niet-geclusterde indexen te behouden tot die tijd uitstellen, als dat kan.
Een gefilterde index toevoegen
Stel je nu voor dat iemand een cruciale query heeft tegen deze tabel die slecht presteert. De behulpzame DBA voert een analyse uit en voegt de volgende gefilterde index toe:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; De nieuwe gefilterde index heeft het gewenste effect op de problematische zoekopdracht en iedereen is tevreden. Merk op dat de nieuwe index helemaal niet verwijst naar de StartDate-kolom, dus we verwachten niet dat dit van invloed zal zijn op onze dagverwijderingsquery.
Een dag verwijderen met de gefilterde index op zijn plaats
We kunnen die verwachting testen door gegevens voor de tweede keer te verwijderen:
DELETE dbo.Data WHERE StartDate = '20140102';
Plots is het uitvoeringsplan veranderd in een parallelle Clustered Index Scan:

Merk op dat er geen aparte Index Delete-operator is voor de nieuwe gefilterde index. De optimizer heeft ervoor gekozen om deze index binnen de Clustered Index Delete-operator te behouden. Dit wordt gemarkeerd in SQL Sentry Plan Explorer zoals hierboven weergegeven ("+1 niet-geclusterde indexen") met volledige details in de tooltip:
Als de tabel groot is (denk aan datawarehouse), kan deze wijziging naar een parallelle scan erg belangrijk zijn. Wat is er gebeurd met de mooie Index Seek op StartDate, en waarom heeft een volledig ongerelateerde gefilterde index de zaken zo drastisch veranderd?
Het probleem vinden
De eerste aanwijzing komt van het kijken naar de eigenschappen van de Clustered Index Scan:
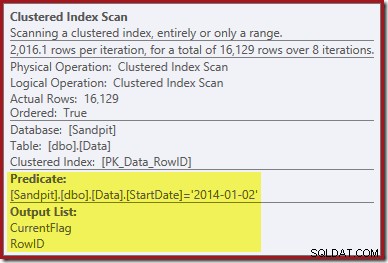
Naast het vinden van RowID-waarden voor de Clustered Index Delete-operator om te verwijderen, leest deze operator nu CurrentFlag-waarden. De noodzaak van deze kolom is onduidelijk, maar het verklaart in ieder geval de beslissing om te scannen:de CurrentFlag-kolom maakt geen deel uit van onze niet-geclusterde StartDate-index.
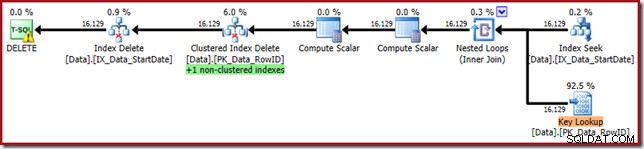
We kunnen dit bevestigen door de verwijderquery te herschrijven om het gebruik van de StartDate niet-geclusterde index te forceren:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Het uitvoeringsplan komt dichter bij zijn oorspronkelijke vorm, maar bevat nu een sleutelzoekopdracht:
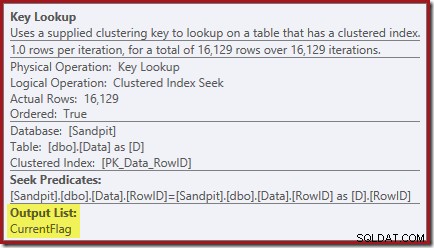
De Key Lookup-eigenschappen bevestigen dat deze operator CurrentFlag-waarden ophaalt:
Je hebt misschien ook de gevarendriehoeken opgemerkt in de laatste twee plannen. Dit zijn ontbrekende indexwaarschuwingen:
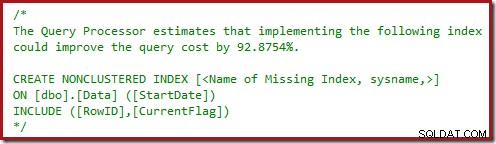
Dit is een verdere bevestiging dat SQL Server graag zou zien dat de CurrentFlag-kolom wordt opgenomen in de niet-geclusterde index. De reden voor de wijziging naar een parallelle Clustered Index Scan is nu duidelijk:de queryprocessor besluit dat het scannen van de tabel goedkoper zal zijn dan het uitvoeren van de Key Lookups.
Ja, maar waarom?
Dit is allemaal heel raar. In het oorspronkelijke uitvoeringsplan kon SQL Server lezen extra kolomgegevens die nodig zijn om niet-geclusterde indexen te onderhouden bij de operator Clustered Index Delete. De waarde van de kolom CurrentFlag is nodig om de gefilterde index te behouden, dus waarom behandelt SQL Server dit niet gewoon op dezelfde manier?
Het korte antwoord is dat het kan, maar alleen als de gefilterde index wordt onderhouden in een aparte Index Delete-operator. We kunnen dit forceren voor de huidige query met behulp van ongedocumenteerde traceringsvlag 8790. Zonder deze vlag kiest de optimizer of elke index in een afzonderlijke operator of als onderdeel van de basistabelbewerking moet worden onderhouden.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Het uitvoeringsplan is terug naar het zoeken naar de StartDate niet-geclusterde index:
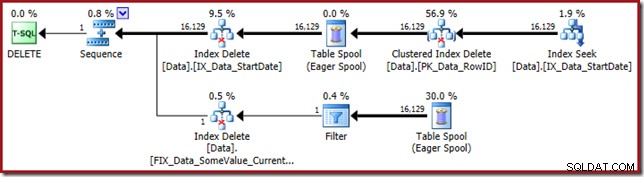
De Index Seek retourneert alleen RowID-waarden (geen CurrentFlag):
En de Clustered Index Delete leest de kolommen die nodig zijn om de niet-geclusterde indexen te onderhouden, inclusief CurrentFlag:
Deze gegevens worden gretig weggeschreven naar een table-spool, die wordt afgespeeld voor elke index die moet worden onderhouden. Let ook op de expliciete Filter-operator vóór de Index Delete-operator voor de gefilterde index.
Nog een patroon om op te letten
Dit probleem resulteert niet altijd in een tabelscan in plaats van een indexzoekopdracht. Om een voorbeeld hiervan te zien, voeg een andere index toe aan de testtabel:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Let op:deze index is niet gefilterd en heeft geen betrekking op de kolom StartDate. Probeer nu opnieuw een dag-verwijder-query:
DELETE dbo.Data WHERE StartDate = '20140104';
De optimizer komt nu met dit monster:
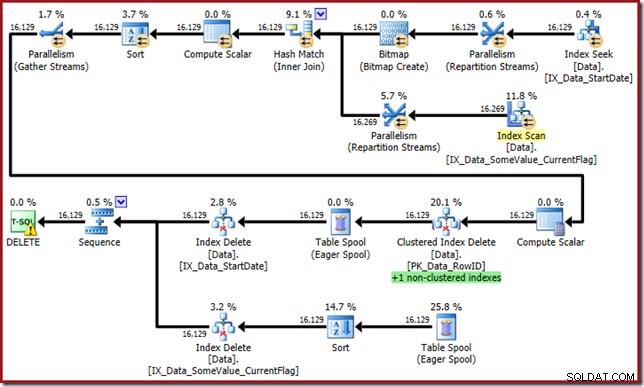
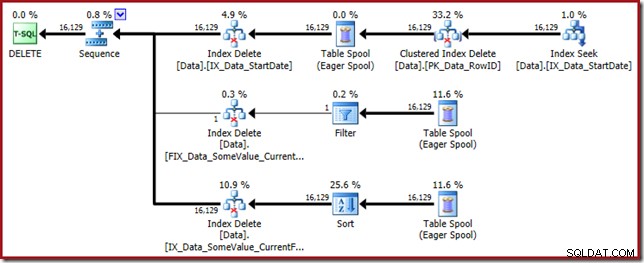
Dit queryplan heeft een hoge verrassingsfactor, maar de hoofdoorzaak is hetzelfde. De CurrentFlag-kolom is nog steeds nodig, maar nu kiest de optimizer een indexkruisingsstrategie om deze te krijgen in plaats van een tabelscan. Het gebruik van de traceringsvlag dwingt een onderhoudsplan per index af en de gezondheid wordt weer hersteld (het enige verschil is een extra spoelherhaling om de nieuwe index te behouden):
Alleen gefilterde indexen veroorzaken dit
Dit probleem treedt alleen op als het optimalisatieprogramma ervoor kiest om een gefilterde index bij te houden in een Clustered Index Delete-operator. Niet-gefilterde indexen worden niet beïnvloed, zoals in het volgende voorbeeld wordt getoond. De eerste stap is om de gefilterde index te verwijderen:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Nu moeten we de query schrijven op een manier die de optimizer overtuigt om alle indexen in de Clustered Index Delete te behouden. Mijn keuze hiervoor is om een variabele en een hint te gebruiken om het aantal rijen van de optimizer te verlagen:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Het uitvoeringsplan is:
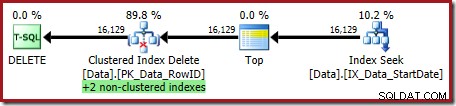
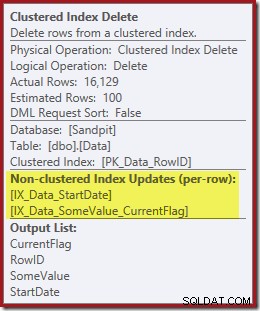
Beide niet-geclusterde indexen worden onderhouden door de Clustered Index Delete:
De Index Seek retourneert alleen de RowID:
De kolommen die nodig zijn voor het indexonderhoud worden intern opgehaald door de delete-operator; deze details worden niet weergegeven in de uitvoer van het toonplan (dus de uitvoerlijst van de verwijderoperator zou leeg zijn). Ik heb een OUTPUT . toegevoegd clausule aan de query om de geclusterde index te tonen Verwijder opnieuw gegevens die het niet bij de invoer heeft ontvangen:
Laatste gedachten
Dit is een lastige beperking om te omzeilen. Aan de ene kant willen we over het algemeen geen ongedocumenteerde traceervlaggen gebruiken in productiesystemen.
De natuurlijke 'oplossing' is om de kolommen die nodig zijn voor gefilterd indexonderhoud toe te voegen aan alle niet-geclusterde indexen die kunnen worden gebruikt om rijen te lokaliseren die moeten worden verwijderd. Dit is in een aantal opzichten niet zo'n aanlokkelijk voorstel. Een ander alternatief is om gewoon helemaal geen gefilterde indexen te gebruiken, maar dat is ook niet ideaal.
Ik heb het gevoel dat de query-optimizer een automatisch onderhoudsalternatief per index zou moeten overwegen voor gefilterde indexen, maar de redenering lijkt op dit moment onvolledig te zijn op dit gebied (en gebaseerd op eenvoudige heuristiek in plaats van de juiste kosten per index/per-rij alternatieven).
Om wat cijfers rond die verklaring te plaatsen, kwam het parallel geclusterde indexscanplan dat door de optimizer was gekozen uit op 5,5 eenheden in mijn tests. Dezelfde zoekopdracht met de traceringsvlag schat de kosten op 1.4 eenheden. Met de derde index op zijn plaats, kostte het door de optimizer gekozen parallelle index-kruispuntplan een geschatte kostprijs van 4,9 , terwijl het traceervlagplan binnenkwam op 2,7 eenheden (alle tests op SQL Server 2014 RTM CU1 build 12.0.2342 onder het 120-kardinaliteitsschattingsmodel en met traceringsvlag 4199 ingeschakeld).
Ik beschouw dit als gedrag dat moet worden verbeterd. Je kunt stemmen om het met mij eens of oneens te zijn over dit Connect-item.