De SQL Server-engine voor het uitvoeren van query's heeft twee manieren om een logische 'union all'-bewerking te implementeren, met behulp van de fysieke operators Concatenation en Merge Join Concatenation. Hoewel de logische bewerking hetzelfde is, zijn er belangrijke verschillen tussen de twee fysieke operators die een enorm verschil kunnen maken voor de efficiëntie van uw uitvoeringsplannen.
De query-optimizer kan in veel gevallen redelijk tussen de twee opties kiezen, maar op dit gebied is het nog lang niet perfect. Dit artikel beschrijft de mogelijkheden voor het afstemmen van zoekopdrachten die worden geboden door Merge Join Concatenation en beschrijft het interne gedrag en de overwegingen waarmee u rekening moet houden om er het beste van te maken.
Aaneenschakeling

De aaneenschakelingsoperator is relatief eenvoudig:de uitvoer is het resultaat van het volledig lezen van elk van zijn invoer in volgorde. De aaneenschakelingsoperator is een n-ary fysieke operator, wat betekent dat het '2...n'-ingangen kan hebben. Laten we ter illustratie eens kijken naar het op AdventureWorks gebaseerde voorbeeld uit mijn vorige artikel, "Query's herschrijven om de prestaties te verbeteren":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
De volgende zoekopdracht bevat product- en transactie-ID's voor zes specifieke producten:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Het produceert een uitvoeringsplan met een aaneenschakelingsoperator met zes ingangen, zoals te zien is in SQL Sentry Plan Explorer:
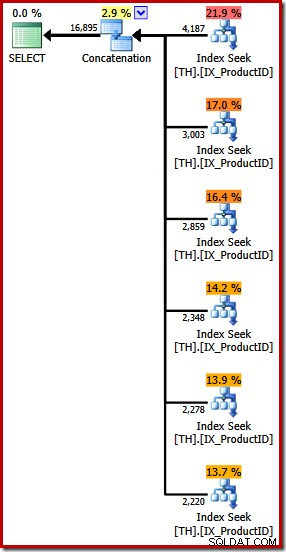
Het bovenstaande plan heeft een aparte Index Seek voor elke vermelde product-ID, in dezelfde volgorde als gespecificeerd in de zoekopdracht (lees van boven naar beneden). De bovenste Index Seek is voor product 870, de volgende naar beneden is voor product 873, dan 921 enzovoort. Niets van dat alles is natuurlijk gegarandeerd gedrag, het is gewoon iets interessants om te observeren.
Ik heb eerder vermeld dat de concatenatie-operator zijn uitvoer vormt door op volgorde van zijn invoer te lezen. Wanneer dit plan wordt uitgevoerd, is de kans groot dat de resultatenset eerst de rijen voor product 870 toont, dan 873, 921, 712, 707 en tenslotte product 711. Nogmaals, dit is niet gegarandeerd omdat we geen BESTELLING hebben opgegeven BY-clausule, maar het laat wel zien hoe Concatenation intern werkt.
Een SSIS "Uitvoeringsplan"
Overweeg om redenen die zo meteen logisch zijn, hoe we een SSIS-pakket kunnen ontwerpen om dezelfde taak uit te voeren. We zouden het geheel zeker ook als een enkele T-SQL-instructie in SSIS kunnen schrijven, maar de interessantere optie is om voor elk product een afzonderlijke gegevensbron te maken en een SSIS "Union All" -component te gebruiken in plaats van de SQL Server-aaneenschakeling operator:
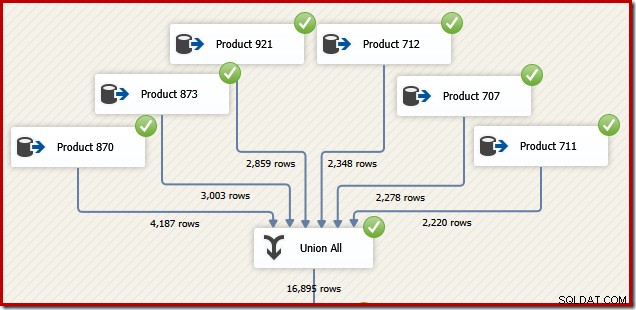
Stel je nu voor dat we de uiteindelijke uitvoer van die gegevensstroom in transactie-ID-volgorde nodig hebben. Een optie zou zijn om een expliciete Sort-component toe te voegen na de Union All:
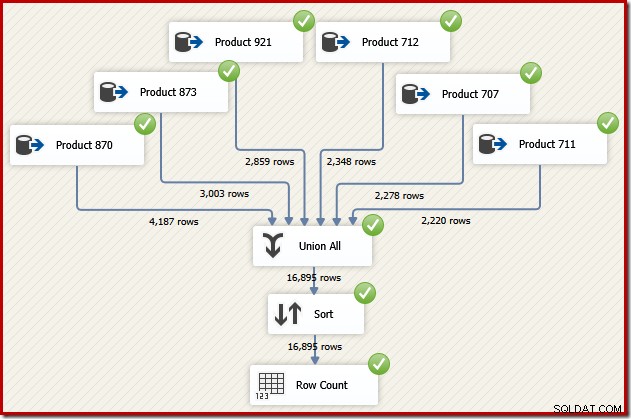
Dat zou zeker het werk doen, maar een bekwame en ervaren SSIS-ontwerper zou beseffen dat er een betere optie is:lees de brongegevens voor elk product in transactie-ID-volgorde (gebruikmakend van de index) en gebruik vervolgens een orderbehoudbewerking om de sets te combineren .
In SSIS wordt het onderdeel dat rijen van twee gesorteerde gegevensstromen combineert tot één gesorteerde gegevensstroom "Samenvoegen" genoemd. Een opnieuw ontworpen SSIS-gegevensstroom die samenvoegen gebruikt om de gewenste rijen in transactie-ID-volgorde te retourneren, volgt:
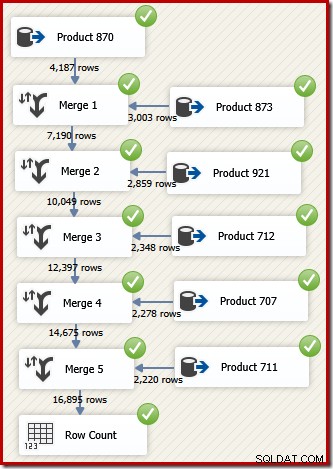
Merk op dat we vijf afzonderlijke Merge-componenten nodig hebben omdat Merge een binaire component is, in tegenstelling tot de SSIS "Union All"-component, die n-ary was . De nieuwe Merge-stroom levert resultaten op in transactie-ID-volgorde, zonder dat een dure (en blokkerende) sorteercomponent nodig is. Inderdaad, als we proberen een Sorteer op transactie-ID toe te voegen na de laatste samenvoeging, toont SSIS een waarschuwing om ons te laten weten dat de stream al op de gewenste manier is gesorteerd:
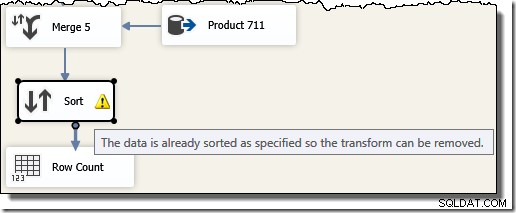
Het punt van het SSIS-voorbeeld kan nu worden onthuld. Kijk naar het uitvoeringsplan dat is gekozen door de SQL Server-query-optimizer wanneer we hem vragen om de originele T-SQL-queryresultaten in transactie-ID-volgorde te retourneren (door een ORDER BY-clausule toe te voegen):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
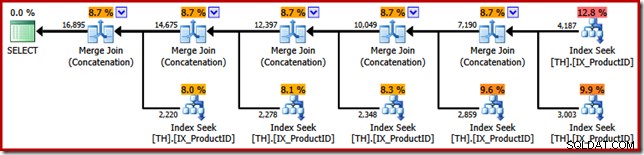
De overeenkomsten met het SSIS Merge-pakket zijn opvallend; zelfs tot aan de behoefte aan vijf binaire "Merge"-operators. Het enige belangrijke verschil is dat SSIS afzonderlijke componenten heeft voor "Merge Join" en "Merge", terwijl SQL Server voor beide dezelfde core-operator gebruikt.
Voor alle duidelijkheid:de operators voor het samenvoegen van samenvoegen (aaneenschakeling) in het uitvoeringsplan van SQL Server zijn niet een join uitvoeren; de engine hergebruikt alleen dezelfde fysieke operator om de order-behoudende unie allemaal te implementeren.
Uitvoeringsplannen schrijven in SQL Server
SSIS heeft geen specificatietaal voor gegevensstromen, noch een optimalisatieprogramma om een dergelijke specificatie om te zetten in een uitvoerbare gegevensstroomtaak. Het is aan de SSIS-pakketontwerper om te beseffen dat een samenvoeging met behoud van de volgorde mogelijk is, componenteigenschappen (zoals sorteersleutels) op de juiste manier in te stellen en vervolgens de prestaties te vergelijken. Dit vereist meer inspanning (en vaardigheid) van de ontwerper, maar biedt wel een zeer fijne mate van controle.
De situatie in SQL Server is het tegenovergestelde:we schrijven een query specificatie met behulp van de T-SQL-taal, vertrouw dan op de query-optimizer om implementatieopties te verkennen en een efficiënte te kiezen. We hebben niet de mogelijkheid om direct een uitvoeringsplan op te stellen. Meestal is dit zeer wenselijk:SQL Server zou ongetwijfeld wat minder populair zijn als we voor elke zoekopdracht een pakket in SSIS-stijl moesten schrijven.
Desalniettemin (zoals uitgelegd in mijn vorige post), kan het door de optimizer gekozen plan gevoelig zijn voor de T-SQL die wordt gebruikt om de gewenste resultaten te beschrijven. Als we het voorbeeld uit dat artikel herhalen, hadden we de oorspronkelijke T-SQL-query kunnen schrijven met een alternatieve syntaxis:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Deze query specificeert exact dezelfde resultatenset als voorheen, maar de optimizer houdt geen rekening met een plan om de volgorde te behouden (samenvoegen) en kiest ervoor om in plaats daarvan de geclusterde index te scannen (een veel minder efficiënte optie):
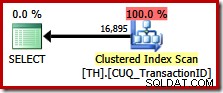
Gebruikmaken van orderbehoud in SQL Server
Het vermijden van onnodig sorteren kan leiden tot aanzienlijke efficiëntiewinsten, of we het nu hebben over SSIS of SQL Server. Het bereiken van dit doel kan ingewikkelder en moeilijker zijn in SQL Server omdat we niet zo'n fijnmazige controle hebben over het uitvoeringsplan, maar er zijn nog steeds dingen die we kunnen doen.
In het bijzonder kan het begrijpen van hoe de SQL Server Merge Join Concatenation-operator intern werkt, ons helpen om duidelijke, relationele T-SQL te blijven schrijven, terwijl we de query-optimizer aanmoedigen om waar nodig orderbehoudende (samenvoegende) verwerkingsopties te overwegen.
Hoe samenvoegen samenvoegen werkt

Voor een normale Merge Join moeten beide invoer worden gesorteerd op de join-toetsen. Samenvoegen Samenvoegen daarentegen voegt eenvoudig twee reeds geordende streams samen tot een enkele geordende stream - er is geen samenvoeging als zodanig.
Dit roept de vraag op:wat is precies de 'volgorde' die wordt bewaard?
In SSIS moeten we sorteersleuteleigenschappen instellen op de Merge-invoer om de volgorde te definiëren. SQL Server heeft hier geen equivalent voor. Het antwoord op de bovenstaande vraag is een beetje ingewikkeld, dus we zullen het stap voor stap doen.
Beschouw het volgende voorbeeld, waarin wordt verzocht om een samenvoeging van twee niet-geïndexeerde heaptabellen (het eenvoudigste geval):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Deze twee tabellen hebben geen indexen en er is geen ORDER BY-clausule. Welke volgorde zal de samenvoeging samenvoegen aaneenschakeling 'behouden'? Laten we, om u een moment te geven om daarover na te denken, eerst kijken naar het uitvoeringsplan dat voor de bovenstaande query is gemaakt in SQL Server-versies voor 2012:
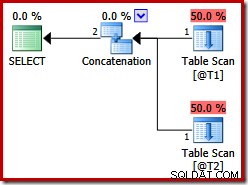
Er is geen samenvoeging van samenvoegingen, ondanks de query-hint:vóór SQL Server 2012 werkt deze hint alleen met UNION, niet met UNION ALL. Om een plan met de gewenste merge-operator te krijgen, moeten we de implementatie van een logische UNION ALL (UNIA) uitschakelen met behulp van de fysieke operator Concatenation (CON). Houd er rekening mee dat het volgende niet is gedocumenteerd en niet wordt ondersteund voor productiegebruik:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Die query levert hetzelfde plan op als SQL Server 2012 en 2014 met alleen de MERGE UNION-queryhint:
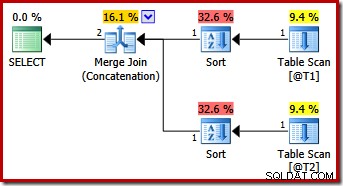
Misschien onverwacht, bevat het uitvoeringsplan expliciete sorteringen op beide invoer van de samenvoeging. De sorteereigenschappen zijn:
Het is logisch dat een samenvoeging die de volgorde behoudt een consistente invoervolgorde vereist, maar waarom is gekozen voor (c1, c2, c3) in plaats van bijvoorbeeld (c3, c1, c2) of (c2, c3, c1)? Als uitgangspunt worden samenvoegingsconcatenatie-invoer gesorteerd op de uitvoerprojectielijst. De select-star in de query breidt uit naar (c1, c2, c3), dus dat is de gekozen volgorde.
Sorteren op Samenvoegen Uitvoerprojectielijst
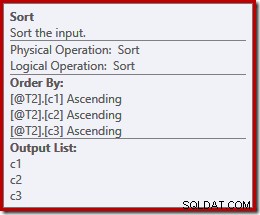
Om het punt verder te illustreren, kunnen we de select-star zelf uitbreiden (zoals we zouden moeten!) en een andere volgorde kiezen (c3, c2, c1) terwijl we toch bezig zijn:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
De sorteringen veranderen nu om overeen te komen (c3, c2, c1):
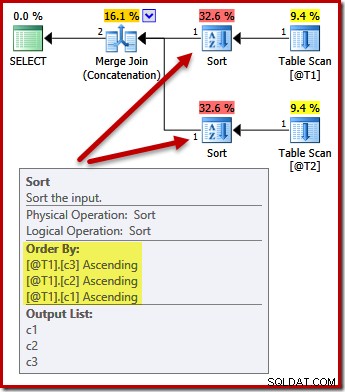
Nogmaals, de zoekopdracht uitvoer order (ervan uitgaande dat we wat gegevens aan de tabellen zouden toevoegen) wordt niet gegarandeerd gesorteerd zoals weergegeven, omdat we geen ORDER BY-clausule hebben. Deze voorbeelden zijn alleen bedoeld om te laten zien hoe de optimizer een initiële sorteervolgorde voor invoer selecteert, bij gebrek aan enige andere reden om te sorteren.
Conflicterende sorteervolgorde
Overweeg nu wat er gebeurt als we de projectielijst verlaten als (c3, c2, c1) en een vereiste toevoegen om de queryresultaten te ordenen op (c1, c2, c3). Zullen de invoer voor de samenvoeging nog steeds sorteren op (c3, c2, c1) met een sortering na de samenvoeging op (c1, c2, c3) om te voldoen aan de ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Nee. De optimizer is slim genoeg om dubbel sorteren te voorkomen:
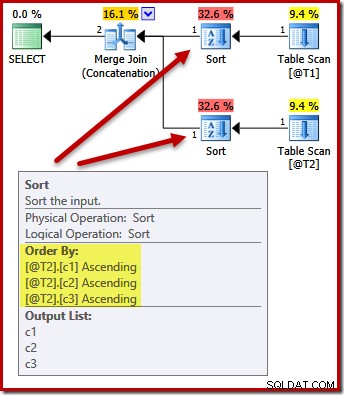
Het sorteren van beide ingangen op (c1, c2, c3) is volkomen acceptabel voor de samenvoegconcatenatie, dus er is geen dubbele sortering vereist.
Merk op dat dit plan doet garanderen dat de volgorde van de resultaten zal zijn (c1, c2, c3). Het plan ziet er hetzelfde uit als de eerdere plannen zonder ORDER BY, maar niet alle interne details worden gepresenteerd in voor de gebruiker zichtbare uitvoeringsplannen.
Het effect van uniciteit
Bij het kiezen van een sorteervolgorde voor de samenvoeginvoer, wordt de optimizer ook beïnvloed door eventuele uniciteitsgaranties die er zijn. Beschouw het volgende voorbeeld met vijf kolommen, maar let op de verschillende kolomvolgorde in de bewerking UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Het uitvoeringsplan bevat sorteringen op (c5, c1, c2, c4, c3) voor tabel @T1 en (c5, c4, c3, c2, c1) voor tabel @T2:
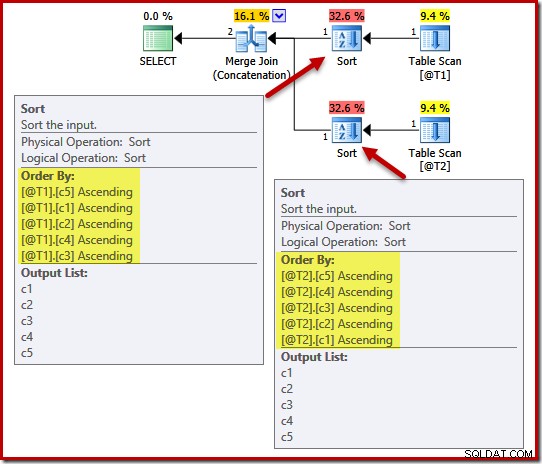
Om het effect van uniciteit op deze soorten aan te tonen, voegen we een UNIEKE beperking toe aan kolom c1 in tabel T1 en kolom c4 in tabel T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
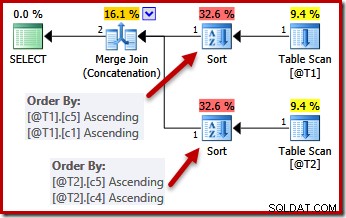
Het punt van uniciteit is dat de optimizer weet dat hij kan stoppen met sorteren zodra hij een kolom tegenkomt die gegarandeerd uniek is. Sorteren op extra kolommen nadat een unieke sleutel is gevonden, heeft per definitie geen invloed op de uiteindelijke sorteervolgorde.
Met de UNIQUE-beperkingen kan de optimizer de (c5, c1, c2, c4, c3) sorteerlijst voor T1 vereenvoudigen tot (c5, c1) omdat c1 uniek is. Evenzo is de (c5, c4, c3, c2, c1) sorteerlijst voor T2 vereenvoudigd tot (c5, c4) omdat c4 een sleutel is:
Parallelisme
De vereenvoudiging door een unieke sleutel is niet perfect doorgevoerd. In een parallel plan worden de streams gepartitioneerd zodat alle rijen voor hetzelfde exemplaar van de samenvoeging op dezelfde thread terechtkomen. Deze gegevenssetpartitionering is gebaseerd op de samenvoegkolommen en niet vereenvoudigd door de aanwezigheid van een sleutel.
Het volgende script gebruikt niet-ondersteunde traceringsvlag 8649 om een parallel plan te genereren voor de vorige query (die verder ongewijzigd blijft):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
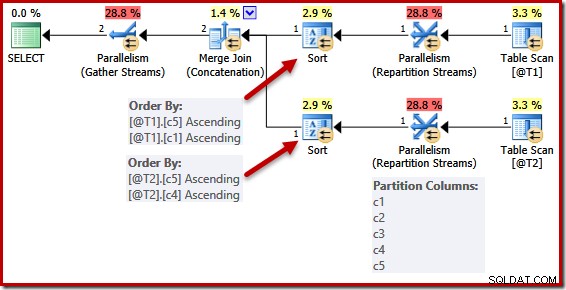
De sorteerlijsten zijn vereenvoudigd zoals voorheen, maar de operators voor Repartition Streams verdelen nog steeds over alle kolommen. Als deze vereenvoudiging consequent zou worden doorgevoerd, zouden de herpartitioneringsoperators ook alleen op (c5, c1) en (c5, c4) werken.
Problemen met niet-unieke indexen
De manier waarop de optimizer redeneert over de sorteervereisten voor samenvoegaaneenschakeling kan leiden tot onnodige sorteerproblemen, zoals het volgende voorbeeld laat zien:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Als we kijken naar de query en beschikbare indexen, zouden we een uitvoeringsplan verwachten dat een geordende scan van de geclusterde indexen uitvoert, waarbij gebruik wordt gemaakt van samenvoeging van samenvoegingen om sorteren te voorkomen. Deze verwachting is volledig gerechtvaardigd, omdat de geclusterde indexen de volgorde bieden die is gespecificeerd in de ORDER BY-clausule. Helaas omvat het plan dat we daadwerkelijk krijgen twee soorten:
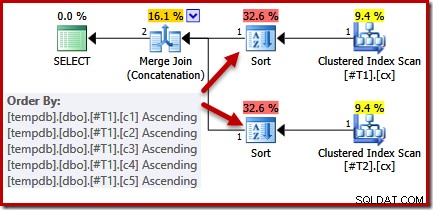
Er is geen goede reden voor deze soorten, ze verschijnen alleen omdat de logica van de query-optimizer onvolmaakt is. De lijst met samengevoegde uitvoerkolommen (c1, c2, c3, c4, c5) is een superset van de ORDER BY, maar er is geen unieke sleutel om die lijst te vereenvoudigen. Als gevolg van deze leemte in de redenering van de optimizer, concludeert deze dat de samenvoeging de invoer moet sorteren op (c1, c2, c3, c4, c5).
We kunnen deze analyse verifiëren door het script aan te passen om een van de geclusterde indexen uniek te maken:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Het uitvoeringsplan heeft nu alleen een sortering boven de tabel met de niet-unieke index:
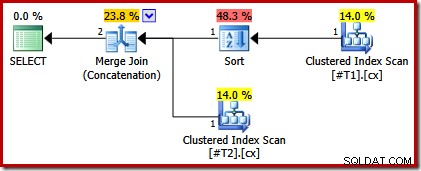
Als we nu beide maken geclusterde indexen uniek, er verschijnen geen sorteringen:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Omdat beide indexen uniek zijn, kunnen de initiële sorteerlijsten voor samenvoeginvoer worden vereenvoudigd tot alleen kolom c1. De vereenvoudigde lijst komt dan exact overeen met de ORDER BY-clausule, dus er zijn geen sorteringen nodig in het definitieve plan:
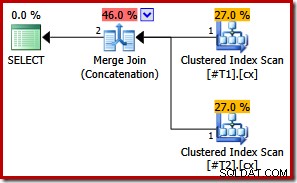
Merk op dat we de vraaghint in dit laatste voorbeeld niet eens nodig hebben om het optimale uitvoeringsplan te krijgen.
Laatste gedachten
Het elimineren van sorteringen in een uitvoeringsplan kan lastig zijn. In sommige gevallen kan het zo simpel zijn als het wijzigen van een bestaande index (of het verstrekken van een nieuwe) om rijen in de vereiste volgorde weer te geven. De query-optimizer doet over het algemeen redelijk werk wanneer geschikte indexen beschikbaar zijn.
In (veel) andere gevallen kan het vermijden van sorteringen echter een veel dieper begrip van de uitvoeringsengine, de query-optimizer en de planoperators zelf vereisen. Het vermijden van sorteringen is ongetwijfeld een geavanceerd onderwerp voor het afstemmen van zoekopdrachten, maar ook ongelooflijk lonend als alles goed komt.