Dit artikel gebruikt een eenvoudige zoekopdracht om enkele diepgaande informatie over updatequery's te onderzoeken.
Voorbeeldgegevens en configuratie
Voor het onderstaande script voor het maken van voorbeeldgegevens is een tabel met getallen vereist. Als je er nog geen hebt, kan het onderstaande script worden gebruikt om er een efficiënt te maken. De resulterende getallentabel zal een enkele integerkolom bevatten met getallen van één tot één miljoen:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Het onderstaande script maakt een geclusterde voorbeeldgegevenstabel met 10.000 ID's, met ongeveer 100 verschillende startdatums per ID. De kolom einddatum is aanvankelijk ingesteld op de vaste waarde '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Hoewel de punten in dit artikel vrij algemeen van toepassing zijn op alle huidige versies van SQL Server, kan de onderstaande configuratie-informatie worden gebruikt om ervoor te zorgen dat u vergelijkbare uitvoeringsplannen en prestatie-effecten ziet:
- SQL Server 2012 Service Pack 3 x64 Developer Edition
- Maximum servergeheugen ingesteld op 2048 MB
- Vier logische processors beschikbaar voor de instantie
- Geen traceervlaggen ingeschakeld
- Standaard leescommitt isolatieniveau
- RCSI- en SI-database-opties uitgeschakeld
Gemorste hash-aggregatie
Als u het bovenstaande script voor het maken van gegevens uitvoert terwijl de daadwerkelijke uitvoeringsplannen zijn ingeschakeld, kan de hash-aggregaat naar tempdb gaan, waardoor een waarschuwingspictogram wordt gegenereerd:

Wanneer uitgevoerd op SQL Server 2012 Service Pack 3, wordt aanvullende informatie over de lekkage weergegeven in de knopinfo:
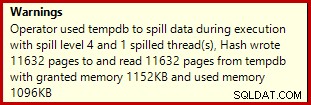
Deze verspilling kan verrassend zijn, aangezien de schattingen van de invoerrij voor de Hash Match precies correct zijn:
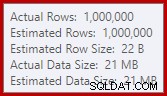
We zijn gewend om schattingen te vergelijken op de invoer voor sorts en hash-joins (alleen build-invoer), maar enthousiaste hash-aggregaten zijn anders. Een hash-aggregaat werkt door gegroepeerde resultaatrijen in de hashtabel te verzamelen, dus het is het aantal uitvoer rijen die belangrijk zijn:
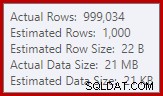
De kardinaliteitsschatter in SQL Server 2012 maakt een nogal slechte schatting van het aantal verwachte verschillende waarden (1.000 versus 999.034 werkelijk); het hashaggregaat loopt daardoor recursief naar niveau 4 tijdens runtime. De 'nieuwe' kardinaliteitsschatter die beschikbaar is in SQL Server 2014 en later, produceert een nauwkeurigere schatting voor de hash-uitvoer in deze query, dus in dat geval ziet u geen hash-mors:

Het aantal werkelijke rijen kan voor u iets afwijken, gezien het gebruik van een pseudo-willekeurige nummergenerator in het script. Het belangrijke punt is dat het gemorste hash-aggregaat afhankelijk is van het aantal unieke waarden dat wordt uitgevoerd, niet van de invoergrootte.
De updatespecificatie
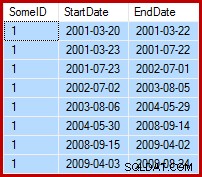
Het is de taak om de voorbeeldgegevens zo bij te werken dat de einddatums worden ingesteld op de dag vóór de volgende startdatum (per SomeID). De eerste paar rijen van de voorbeeldgegevens kunnen er bijvoorbeeld als volgt uitzien vóór de update (alle einddatums zijn ingesteld op 9999-12-31):

Doe dan zo na de update:
1. Basislijn update-query
Een redelijk natuurlijke manier om de vereiste update in T-SQL uit te drukken is als volgt:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Het (werkelijke) uitvoeringsplan na de uitvoering is:
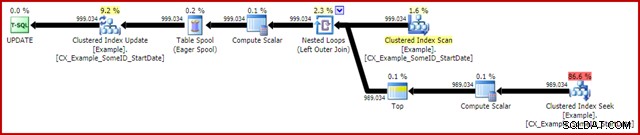
Het meest opvallende kenmerk is het gebruik van een Eager Table Spool om Halloween-bescherming te bieden. Dit is nodig voor een correcte werking hier vanwege de self-join van de update-doeltabel. Het effect is dat alles rechts van de spool wordt voltooid, waarbij alle informatie wordt opgeslagen die nodig is om wijzigingen aan te brengen in een tempdb-werktabel. Zodra de leesbewerking is voltooid, wordt de inhoud van de werktabel opnieuw afgespeeld om de wijzigingen toe te passen in de iterator Clustered Index Update.
Prestaties
Om ons te concentreren op het maximale prestatiepotentieel van dit uitvoeringsplan, kunnen we dezelfde updatequery meerdere keren uitvoeren. Het is duidelijk dat alleen de eerste run zal resulteren in eventuele wijzigingen in de gegevens, maar dit blijkt een ondergeschikte overweging te zijn. Als dit je stoort, voel je vrij om de einddatumkolom opnieuw in te stellen voor elke run met behulp van de volgende code. De algemene punten die ik zal maken, zijn niet afhankelijk van het aantal daadwerkelijk aangebrachte gegevenswijzigingen.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Met het verzamelen van uitvoeringsplan uitgeschakeld, alle vereiste pagina's in de bufferpool en geen resetten van de einddatumwaarden tussen uitvoeringen, wordt deze query meestal uitgevoerd in ongeveer 5700 ms op mijn laptop. De statistische IO-uitvoer is als volgt:(lees vooruit leest en LOB-tellers waren nul en worden weggelaten om ruimteredenen)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
De scantelling vertegenwoordigt het aantal keren dat een scanbewerking is gestart. Voor de voorbeeldtabel is dit 1 voor de geclusterde indexscan en 999.034 voor elke keer dat de gecorreleerde geclusterde indexzoekactie wordt teruggekaatst. De werktafel die door de Eager Spool wordt gebruikt, heeft slechts één keer een scanbewerking gestart.
Logische uitlezingen
De interessantere informatie in de IO-uitvoer is het aantal logische leesbewerkingen:meer dan 6 miljoen voor de voorbeeldtabel, en bijna 3 miljoen voor de werktafel.
De logische uitlezingen van de voorbeeldtabel worden meestal geassocieerd met de zoekactie en de update. De Seek maakt 3 logische leesbewerkingen voor elke iteratie:1 elk voor de root-, intermediate- en leaf-niveaus van de index. De update kost eveneens 3 keer gelezen per rij wordt bijgewerkt, terwijl de engine door de b-tree navigeert om de doelrij te lokaliseren. De Clustered Index Scan is verantwoordelijk voor slechts een paar duizend keer gelezen, één per pagina lees.
De werktafel van de spoel is ook intern gestructureerd als een b-boom en telt meerdere keren gelezen als de spoel de invoegpositie lokaliseert terwijl de invoer wordt verbruikt. Misschien contra-intuïtief, telt de spool geen logische reads terwijl deze wordt gelezen om de Clustered Index Update aan te sturen. Dit is gewoon een gevolg van de implementatie:een logische read wordt geteld wanneer de code de BPool::Get uitvoert methode. Schrijven naar de spool roept deze methode op elk niveau van de index aan; lezen van de spoel volgt een ander codepad dat BPool::Get . niet aanroept helemaal niet.
Merk ook op dat de statistische IO-uitvoer een enkel totaal rapporteert voor de voorbeeldtabel, ondanks het feit dat deze door drie verschillende iterators in het uitvoeringsplan wordt benaderd (de Scan, Seek en Update). Dit laatste feit maakt het moeilijk om logische reads te correleren met de iterator die ze heeft veroorzaakt. Ik hoop dat deze beperking wordt aangepakt in een toekomstige versie van het product.
2. Update met rijnummers
Een andere manier om de update-query uit te drukken, is door de rijen per ID te nummeren en samen te voegen:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Het post-uitvoeringsplan is als volgt:
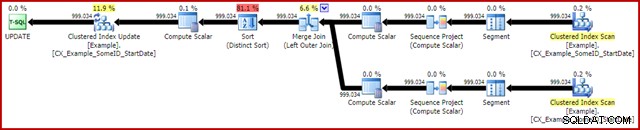
Deze zoekopdracht wordt doorgaans uitgevoerd in 2950 ms op mijn laptop, wat gunstig afsteekt bij de 5700ms (in dezelfde omstandigheden) die werd gezien voor de originele update-verklaring. De statistische IO-uitvoer is:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Dit toont twee scans die zijn gestart voor de voorbeeldtabel (één voor elke geclusterde indexscan-iterator). De logische uitlezingen zijn opnieuw een aggregaat over alle iterators die toegang hebben tot deze tabel in het queryplan. Net als voorheen maakt het ontbreken van een uitsplitsing het onmogelijk om te bepalen welke iterator (van de twee Scans en de Update) verantwoordelijk was voor de 3 miljoen reads.
Desalniettemin kan ik je vertellen dat de Clustered Index Scans elk slechts een paar duizend logische reads tellen. De overgrote meerderheid van de logische uitlezingen wordt veroorzaakt door de geclusterde indexupdate die door de index b-tree navigeert om de updatepositie te vinden voor elke rij die wordt verwerkt. U zult mij voorlopig op mijn woord moeten geloven; meer uitleg volgt binnenkort.
De nadelen
Dat is zo'n beetje het einde van het goede nieuws voor deze vorm van de zoekopdracht. Het presteert veel beter dan het origineel, maar is om een aantal andere redenen veel minder bevredigend. Het belangrijkste probleem wordt veroorzaakt door een optimalisatiebeperking, wat betekent dat het niet herkent dat de rijnummeringsbewerking een uniek nummer produceert voor elke rij binnen een SomeID-partitie.
Dit simpele feit leidt tot een aantal ongewenste gevolgen. Om te beginnen is de merge-join geconfigureerd om in de veel-op-veel-join-modus te worden uitgevoerd. Dit is de reden voor de (ongebruikte) werktabel in de statistiek-IO (veel-op-veel-samenvoeging vereist een werktabel voor het terugspoelen van dubbele join-sleutels). Als u een veel-op-veel-join verwacht, betekent dit ook dat de schatting van de kardinaliteit voor de join-output hopeloos verkeerd is:
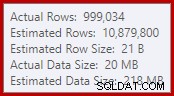
Als gevolg daarvan vraagt de Sort veel te veel geheugentoelage. De eigenschappen van het rootknooppunt laten zien dat Sort graag 812.752 KB geheugen had willen hebben, hoewel het slechts 379.440 KB had gekregen vanwege de beperkte maximale servergeheugeninstelling (2048 MB). De soort gebruikte tijdens runtime maximaal 58.968 KB:
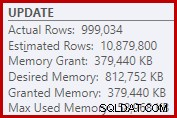
Overmatig geheugen zorgt ervoor dat geheugen wordt gestolen voor ander productief gebruik en kan ertoe leiden dat query's wachten totdat er geheugen beschikbaar komt. In veel opzichten kunnen buitensporige geheugentoekenningen meer een probleem zijn dan onderschatten.
De optimalisatiebeperking verklaart ook waarom een hint voor het samenvoegen van joins nodig was voor de query voor de beste prestaties. Zonder deze hint schat de optimizer ten onrechte dat een hash-join goedkoper zou zijn dan de veel-op-veel merge-join. Het hash-deelnameplan loopt gemiddeld in 3350 ms.
Merk als laatste negatief gevolg op dat de Sortering in het plan een Distinct Sort is. Nu zijn er een paar redenen voor die soort (niet in het minst omdat het de vereiste Halloween-bescherming kan bieden), maar het is slechts een onderscheiden Sorteer omdat de optimizer de uniciteitsinformatie mist. Over het algemeen is het moeilijk om veel van dit uitvoeringsplan te waarderen dat verder gaat dan de uitvoering.
3. Update met behulp van de LEAD-analysefunctie
Aangezien dit artikel voornamelijk gericht is op SQL Server 2012 en later, kunnen we de updatequery vrij natuurlijk uitdrukken met behulp van de LEAD-analysefunctie. In een ideale wereld zouden we een zeer compacte syntaxis kunnen gebruiken zoals:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Helaas is dit niet legaal. Het resulteert in foutmelding 4108, "Vensterfuncties kunnen alleen voorkomen in de SELECT- of ORDER BY-clausules". Dit is een beetje frustrerend omdat we hoopten op een uitvoeringsplan dat een self-join (en de bijbehorende update Halloween Protection) zou kunnen voorkomen.
Het goede nieuws is dat we de self-join nog steeds kunnen vermijden met behulp van een Common Table Expression of afgeleide tabel. De syntaxis is iets uitgebreider, maar het idee is vrijwel hetzelfde:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Het post-uitvoeringsplan is:

Dit duurt meestal ongeveer 3400ms op mijn laptop, die langzamer is dan de rijnummeroplossing (2950 ms) maar nog steeds veel sneller dan het origineel (5700 ms). Een ding dat opvalt in het uitvoeringsplan is de soort lekkage (nogmaals aanvullende informatie over lekkage dankzij de verbeteringen in SP3):
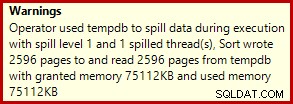
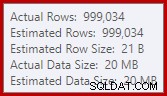
Dit is een vrij kleine lekkage, maar het kan nog steeds de prestaties tot op zekere hoogte beïnvloeden. Het vreemde is dat de invoerschatting voor de Sortering precies correct is:
Gelukkig is er een "oplossing" voor deze specifieke voorwaarde in SQL Server 2012 SP2 CU8 (en andere releases – zie het KB-artikel voor details). Het uitvoeren van de query met de fix en de vereiste traceringsvlag 7470 ingeschakeld, betekent dat de Sort voldoende geheugen vraagt om ervoor te zorgen dat het nooit naar de schijf gaat als de geschatte invoersorteergrootte niet wordt overschreden.
LEAD-updatequery zonder sorteerverspilling
Voor variatie gebruikt de onderstaande fix-enabled query afgeleide tabelsyntaxis in plaats van een CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Het nieuwe plan voor de uitvoering is:

Door de kleine lekkage te elimineren, worden de prestaties verbeterd van 3400 ms naar 3250 ms . De statistische IO-uitvoer is:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Als je dit vergelijkt met de logische reads voor de rijgenummerde query, zul je zien dat de logische reads zijn afgenomen van 3.001.808 naar 2.999.455 – een verschil van 2.353 reads. Dit komt exact overeen met het verwijderen van een enkele Clustered Index Scan (één keer gelezen per pagina).
U herinnert zich misschien dat ik zei dat de overgrote meerderheid van de logische reads voor deze update-query's verband houden met de Clustered Index Update, en dat de scans werden geassocieerd met "slechts een paar duizend reads". We kunnen dit nu wat directer zien door een eenvoudige rij-tellingsquery uit te voeren tegen de voorbeeldtabel:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
De IO-uitgang toont precies het 2.353 logische leesverschil tussen het rijnummer en de afleidingsupdates:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Verdere verbetering?
De 'spill-fixed lead'-query (3250 ms) is nog steeds een stuk langzamer dan de dubbele rij-genummerde query (2950 ms), wat misschien een beetje verrassend is. Intuïtief zou je verwachten dat een enkele scan- en analysefunctie (Window Spool en Stream Aggregate) sneller is dan twee scans, twee sets rijnummers en een join.
Hoe dan ook, het ding dat uit het uitvoeringsplan van de leadquery springt, is de Sort. Het was ook aanwezig in de rijgenummerde query, waar het bijdroeg aan Halloween Protection en een geoptimaliseerde sorteervolgorde voor de Clustered Index Update (waarin de eigenschap DMLRequestSort is ingesteld).
Het punt is dat deze Sortering volledig overbodig is in het leadqueryplan. Het is niet nodig voor Halloween Protection omdat de self-join is verdwenen. Het is ook niet nodig voor een geoptimaliseerde sorteervolgorde voor invoegen:de rijen worden gelezen in geclusterde sleutelvolgorde en er is niets in het plan om die volgorde te verstoren. Het echte probleem kan worden gezien door naar de sorteereigenschappen te kijken:

Let op de sectie Order By daar. De sortering is gerangschikt op SomeID en StartDate (de geclusterde indexsleutels) maar ook op [Uniq1002], de uniquifier. Dit is een gevolg van het feit dat de geclusterde index niet uniek is verklaard, hoewel we stappen hebben ondernomen in de gegevenspopulatiequery om ervoor te zorgen dat de combinatie van SomeID en StartDate in feite uniek zou zijn. (Dit was opzettelijk, dus ik kon hierover praten.)
Toch is dit een beperking. Rijen worden op volgorde uit de geclusterde index gelezen en de nodige interne garanties bestaan zodat de optimizer deze sortering veilig kan vermijden. Het is gewoon een vergissing dat de optimizer niet herkent dat de inkomende stream is gesorteerd op uniquifier, evenals op SomeID en StartDate. Het erkent dat (SomeID, StartDate) volgorde kan worden behouden, maar niet (SomeID, StartDate, uniquifier). Nogmaals, ik hoop dat dit in een toekomstige versie zal worden aangepakt.
Om dit te omzeilen, kunnen we doen wat we in de eerste plaats hadden moeten doen:de geclusterde index als uniek bouwen:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
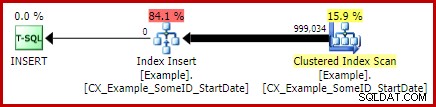
Ik laat het als een oefening voor de lezer om aan te tonen dat de eerste twee (niet-LEAD) zoekopdrachten niet profiteren van deze indexeringswijziging (weggelaten puur om ruimteredenen - er is veel te behandelen).
De definitieve vorm van de leadupdate-query
Met de unieke geclusterde index aanwezig is, produceert exact dezelfde LEAD-query (CTE of afgeleide tabel als u wilt) het geschatte (pre-uitvoerings)plan dat we verwachten:

Dit lijkt redelijk optimaal. Een enkele lees- en schrijfbewerking met een minimum aan operators ertussen. Zeker, het lijkt veel beter dan de vorige versie met de onnodige sortering, die in 3250 ms werd uitgevoerd nadat de vermijdbare lekkage was verwijderd (ten koste van de geheugentoekenning een beetje).
Het (werkelijke) plan na de uitvoering is bijna precies hetzelfde als het plan voor de uitvoering:

Alle schattingen zijn precies correct, behalve de uitvoer van de Window Spool, die 2 rijen ertussen zit. De statistische IO-informatie is precies hetzelfde als voordat de Sortering werd verwijderd, zoals je zou verwachten:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Om het kort samen te vatten, het enige duidelijke verschil tussen dit nieuwe plan en het onmiddellijk vorige is dat de Sort (met een geschatte kostenbijdrage van bijna 80%) is verwijderd.
Het kan dan een verrassing zijn om te horen dat de nieuwe query – zonder de Sortering – wordt uitgevoerd in 5000 ms . Dit is veel erger dan de 3250ms met de Sort, en bijna net zo lang als de originele loop-joinquery van 5700ms. De oplossing voor dubbele rijnummering is nog steeds ver vooruit op 2950ms.
Uitleg
De uitleg is enigszins esoterisch en heeft betrekking op de manier waarop vergrendelingen worden afgehandeld voor de laatste vraag. We kunnen dit effect op verschillende manieren laten zien, maar de eenvoudigste is waarschijnlijk om naar de wacht- en vergrendelingsstatistieken te kijken met behulp van DMV's:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Wanneer de geclusterde index niet uniek is, en er is een sortering in het plan, zijn er geen significante wachttijden, slechts een paar PAGEIOLATCH_UP wachttijden en de verwachte SOS_SCHEDULER_YIELDs.
Wanneer de geclusterde index uniek is en de Sortering is verwijderd, zijn de wachttijden:
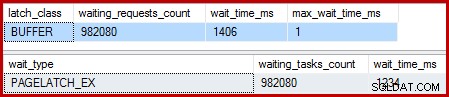
Er zijn 982.080 exclusieve paginavergrendelingen, met een wachttijd die vrijwel alle extra uitvoeringstijd verklaart. Om te benadrukken, dat is bijna één vergrendeling wachten per bijgewerkte rij! We verwachten misschien een vergrendeling per rijwijziging, maar geen vergrendeling wacht , vooral wanneer de testquery de enige activiteit op de instantie is. De vergrendelingswachttijden zijn kort, maar het zijn er ontzettend veel.
Luie vergrendelingen
Na de uitvoering van de query met een debugger en analyser bijgevoegd, is de uitleg als volgt.
De Clustered Index Scan maakt gebruik van luie vergrendelingen - een optimalisatie die betekent dat vergrendelingen alleen worden vrijgegeven wanneer een andere thread toegang tot de pagina vereist. Normaal gesproken worden vergrendelingen onmiddellijk na het lezen of schrijven vrijgegeven. Luie vergrendelingen optimaliseren het geval waarin het scannen van een hele pagina anders voor elke rij dezelfde paginavergrendeling zou verkrijgen en vrijgeven. Wanneer luie vergrendeling zonder strijd wordt gebruikt, wordt slechts één vergrendeling gebruikt voor de hele pagina.
Het probleem is dat het gepijplijnde karakter van het uitvoeringsplan (geen blokkerende operators) betekent dat lezen overlappen met schrijven. Wanneer de Clustered Index Update probeert een EX-latch te verkrijgen om een rij te wijzigen, zal het bijna altijd ontdekken dat de pagina al is vergrendeld SH (de luie grendel die wordt genomen door de Clustered Index Scan). Deze situatie resulteert in een wachtende vergrendeling.
Als onderdeel van het voorbereiden om te wachten en over te schakelen naar het volgende uitvoerbare item in de planner, zorgt de code ervoor dat eventuele luie vergrendelingen worden vrijgegeven. Het loslaten van de luie grendel signaleert de eerste in aanmerking komende ober, die toevallig zichzelf is. We hebben dus de vreemde situatie waarin een thread zichzelf blokkeert, zijn luie vergrendeling loslaat en vervolgens aangeeft dat hij weer kan worden uitgevoerd. De draad pikt weer op, en gaat verder, maar pas nadat al dat verspilde werk met opschorten en schakelen, signaleren en hervatten gedaan is. Zoals ik al eerder zei, de wachttijden zijn kort, maar het zijn er veel.
Voor zover ik weet, is deze vreemde opeenvolging van gebeurtenissen zo ontworpen en om goede interne redenen. Toch is er geen ontkomen aan het feit dat het hier een vrij dramatische invloed heeft op de prestaties. Ik zal hierover navraag doen en het artikel bijwerken als er een openbare verklaring moet worden afgelegd. In de tussentijd kan buitensporig wachten op zelfvergrendeling iets zijn om op te letten bij gepijplijnde updatequery's, hoewel het niet duidelijk is wat eraan gedaan moet worden vanuit het oogpunt van de queryschrijver.
Betekent dit dat de aanpak met dubbele rijnummering het beste is wat we voor deze query kunnen doen? Niet helemaal.
4. Handmatige Halloween-bescherming
Deze laatste optie klinkt en ziet er misschien een beetje gek uit. Het algemene idee is om alle informatie te schrijven die nodig is om de wijzigingen in een tabelvariabele aan te brengen en vervolgens de update als een afzonderlijke stap uit te voeren.
Bij gebrek aan een betere beschrijving, noem ik dit de "handmatige HP"-benadering omdat het conceptueel vergelijkbaar is met het schrijven van alle wijzigingsinformatie naar een Eager Table Spool (zoals te zien in de eerste vraag) voordat de update vanaf die spool wordt aangestuurd.
Hoe dan ook, de code is als volgt:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Die code gebruikt bewust een tabelvariabele om de kosten van automatisch gemaakte statistieken te vermijden die het gebruik van een tijdelijke tabel met zich mee zou brengen. Dit is hier OK omdat ik de planvorm ken die ik wil, en het is niet afhankelijk van kostenramingen of statistische informatie.
Het enige nadeel van de tabelvariabele (zonder traceringsvlag) is dat de optimizer doorgaans een enkele rij schat en geneste lussen kiest voor de update. Om dit te voorkomen heb ik een merge join hint gebruikt. Nogmaals, dit wordt aangedreven door precies te weten welke planvorm moet worden bereikt.
Het post-uitvoeringsplan voor het invoegen van de tabelvariabele ziet er precies hetzelfde uit als de query die het probleem had met de latch waits:

Het voordeel van dit plan is dat het niet dezelfde tabel verandert als waaruit het leest. Er is geen Halloween-bescherming vereist en er is geen kans op storing door de vergrendeling. Daarnaast zijn er aanzienlijke interne optimalisaties voor tempdb-objecten (locking en logging) en worden ook andere normale bulklaadoptimalisaties toegepast. Onthoud dat bulkoptimalisaties alleen beschikbaar zijn voor invoegingen, niet voor updates of verwijderingen.
Het post-uitvoeringsplan voor de updateverklaring is:
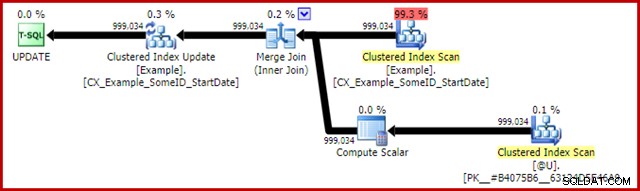
De Merge Join hier is het efficiënte één-op-veel-type. Sterker nog, dit plan komt in aanmerking voor een speciale optimalisatie, wat betekent dat de Clustered Index Scan en Clustered Index Update dezelfde rijenset delen. Het belangrijke gevolg is dat de Update niet langer de rij hoeft te lokaliseren om bij te werken - deze is al correct gepositioneerd door het lezen. Dit scheelt enorm veel logische reads (en andere activiteiten) bij de Update.
Er is niets in normale uitvoeringsplannen om aan te tonen waar deze gedeelde rijenset-optimalisatie wordt toegepast, maar het inschakelen van ongedocumenteerde traceringsvlag 8666 onthult extra eigenschappen op de update en scan die laten zien dat het delen van rijensets in gebruik is, en dat stappen worden ondernomen om ervoor te zorgen dat de update veilig is van het Halloween-probleem.
De statistische IO-uitvoer voor de twee query's is als volgt:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Beide leesbewerkingen van de voorbeeldtabel omvatten een enkele scan en één logische leesbewerking per pagina (zie eerder de eenvoudige query voor het tellen van rijen). De #B9C034B8-tabel is de naam van het interne tempdb-object dat de tabelvariabele ondersteunt. Het totale aantal logische waarden voor beide query's is 3 * 2353 =7.059. De werktafel is de interne opslag in het geheugen die door de Window Spool wordt gebruikt.
De typische uitvoeringstijd voor deze query is 2300ms . Eindelijk hebben we iets dat de dubbele rijnummering (2950 ms) overtreft, hoe onwaarschijnlijk het ook lijkt.
Laatste gedachten
Er zijn misschien nog betere manieren om deze update te schrijven die nog beter presteren dan de "handmatige HP"-oplossing hierboven. De prestatieresultaten kunnen zelfs verschillen op uw hardware- en SQL Server-configuratie, maar geen van beide is het belangrijkste punt van dit artikel. Dat wil niet zeggen dat ik niet geïnteresseerd ben in betere zoekopdrachten of prestatievergelijkingen - dat ben ik wel.
Het punt is dat er veel meer aan de hand is in SQL Server dan wordt onthuld in uitvoeringsplannen. Hopelijk zullen sommige details die in dit nogal lange artikel worden besproken interessant of zelfs nuttig zijn voor sommige mensen.
Het is goed om verwachtingen te hebben van de prestaties en om te weten welke plattegrondvormen en eigenschappen over het algemeen gunstig zijn. Dat soort ervaring en kennis zal u goed van pas komen voor 99% of meer van de vragen die u ooit zult moeten afstemmen. Soms is het echter goed om iets raars of ongebruikelijks te proberen, gewoon om te zien wat er gebeurt en om die verwachtingen te valideren.