In 2013 schreef ik over een bug in de optimizer waarbij de 2e en 3e argumenten voor DATEDIFF() kunnen worden verwisseld – wat kan leiden tot onjuiste schattingen van het aantal rijen en, op zijn beurt, een slechte selectie van het uitvoeringsplan:
- Prestatieverrassingen en veronderstellingen:DATEDIFF
Dit afgelopen weekend hoorde ik over een vergelijkbare situatie en ging er meteen vanuit dat het hetzelfde probleem was. De symptomen leken immers bijna identiek:
- Er was een datum/tijd-functie in de
WHEREclausule.- Deze keer was het
DATEADD()in plaats vanDATEDIFF().
- Deze keer was het
- Er was een duidelijk onjuiste schatting van het aantal rijen van 1, vergeleken met een daadwerkelijk aantal rijen van meer dan 3 miljoen.
- Dit was eigenlijk een schatting van 0, maar SQL Server rondt dergelijke schattingen altijd af naar 1.
- Er is een slechte planselectie gemaakt (in dit geval is er een lusverbinding gekozen) vanwege de lage schatting.
Het gewraakte patroon zag er als volgt uit:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
De gebruiker probeerde verschillende variaties, maar er veranderde niets; ze slaagden er uiteindelijk in om het probleem te omzeilen door het predikaat te veranderen in:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Dit kreeg een betere schatting (de typische schatting van 30% ongelijkheid); dus niet helemaal juist. En hoewel het de lus-join heeft geëlimineerd, zijn er twee grote problemen met dit predikaat:
- Het is niet dezelfde vraag, omdat het nu zoekt naar grenzen van 365 dagen die zijn verstreken, in plaats van groter te zijn dan een bepaald tijdstip 365 dagen geleden. Statistisch significant? Misschien niet. Maar technisch gezien niet hetzelfde.
- Toepassen van de functie op de kolom maakt de hele uitdrukking niet-sargable, wat leidt tot een volledige scan. Wanneer de tabel slechts iets meer dan een jaar aan gegevens bevat, is dit niet erg, maar naarmate de tabel groter wordt of het predikaat smaller wordt, wordt dit een probleem.
Nogmaals, ik kwam tot de conclusie dat de DATEADD() operatie was het probleem, en raadde een aanpak aan die niet afhankelijk was van DATEADD() – het bouwen van een datetime van alle delen van de huidige tijd, waardoor ik een jaar kan aftrekken zonder DATEADD() te gebruiken :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Dit was niet alleen omvangrijk, maar had ook zijn eigen problemen, namelijk dat er een heleboel logica moest worden toegevoegd om schrikkeljaren correct te verantwoorden. Ten eerste, zodat het niet faalt als het toevallig op 29 februari loopt, en ten tweede, om in alle gevallen precies 365 dagen op te nemen (in plaats van 366 in het jaar dat volgt op een schrikkeldag). Makkelijke oplossingen natuurlijk, maar ze maken de logica veel lelijker, vooral omdat de query binnen een weergave moest bestaan, waar tussenliggende variabelen en meerdere stappen niet mogelijk zijn.
In de tussentijd heeft de OP een Connect-item ingediend, verbijsterd door de schatting van één rij:
- Connect #2567628:beperking met DateAdd() levert geen goede schattingen op
Toen kwam Paul White (@SQL_Kiwi) langs en wierp, zoals zo vaak eerder, wat extra licht op het probleem. Hij deelde een gerelateerd Connect-item ingediend door Erland Sommarskog in 2011:
- Connect #685903:onjuiste schatting wanneer sysdatetime wordt weergegeven in een dateadd()-expressie
In wezen is het probleem dat er een slechte schatting kan worden gemaakt, niet alleen wanneer SYSDATETIME() (of SYSUTCDATETIME() ) verschijnt, zoals Erland oorspronkelijk meldde, maar wanneer een datetime2 uitdrukking is betrokken bij het predikaat (en misschien alleen wanneer DATEADD() wordt ook gebruikt). En het kan beide kanten op - als we >= swap ruilen voor <= , wordt de schatting de hele tabel, dus het lijkt erop dat de optimizer naar de SYSDATETIME() kijkt waarde als een constante, en alle bewerkingen zoals DATEADD() . volledig negeren die ertegen worden uitgevoerd.
Paul vertelde dat de tijdelijke oplossing is om gewoon een datetime . te gebruiken equivalent bij het berekenen van de datum, voordat deze wordt omgezet in het juiste gegevenstype. In dit geval kunnen we SYSUTCDATETIME() . verwisselen en verander het in GETUTCDATE() :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Ja, dit resulteert in een klein verlies aan precisie, maar dat geldt ook voor een stofdeeltje dat uw vinger vertraagt op weg naar het indrukken van de

De uitlezingen zijn vergelijkbaar omdat de tabel bijna uitsluitend gegevens van het afgelopen jaar bevat, dus zelfs een zoekopdracht wordt een bereikscan van het grootste deel van de tabel. De rijtellingen zijn niet identiek omdat (a) de tweede zoekopdracht om middernacht stopt en (b) de derde zoekopdracht een extra dag aan gegevens bevat vanwege de schrikkeldag eerder dit jaar. Dit laat in ieder geval zien hoe we dichter bij de juiste schattingen kunnen komen door DATEADD() te elimineren. , maar de juiste oplossing is om de directe combinatie te verwijderen van DATEADD() en datetime2 .
Om verder te illustreren hoe de schattingen het mis hebben, kun je zien dat als we verschillende argumenten en richtingen doorgeven aan de oorspronkelijke vraag en Paul's herschrijving, het aantal geschatte rijen voor de eerste altijd gebaseerd is op de huidige tijd - ze verandert niet met het aantal verstreken dagen (terwijl dat van Paul elke keer relatief nauwkeurig is):
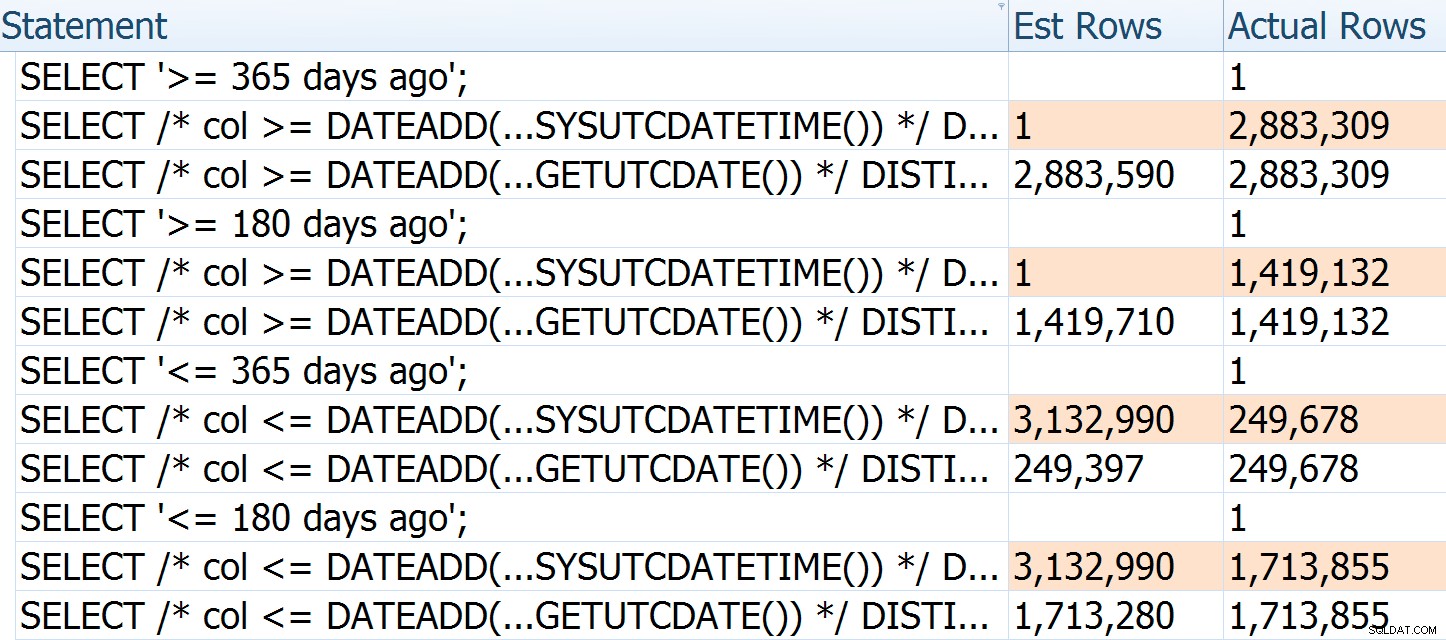 De werkelijke rijen voor de eerste query zijn iets lager omdat deze werd uitgevoerd na een lang dutje
De werkelijke rijen voor de eerste query zijn iets lager omdat deze werd uitgevoerd na een lang dutje
De schattingen zullen niet altijd zo goed zijn; mijn tafel heeft gewoon een relatief stabiele distributie. Ik heb het ingevuld met de volgende vraag en vervolgens de statistieken bijgewerkt met fullscan, voor het geval je dit zelf wilt uitproberen:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Ik heb gereageerd op het nieuwe Connect-item en zal waarschijnlijk terugkomen en mijn Stack Exchange-antwoord bijwerken.
De moraal van het verhaal
Probeer het combineren van DATEADD() . te vermijden met uitdrukkingen die datetime2 . opleveren , vooral op oudere versies van SQL Server (dit was op SQL Server 2012). Het kan ook een probleem zijn, zelfs op SQL Server 2016, bij gebruik van het oudere schattingsmodel voor kardinaliteit (vanwege een lager compatibiliteitsniveau of expliciet gebruik van traceringsvlag 9481). Dit soort problemen zijn subtiel en niet altijd meteen duidelijk, dus hopelijk dient dit als een herinnering (misschien zelfs voor mij de volgende keer dat ik een soortgelijk scenario tegenkom). Zoals ik in de vorige post suggereerde, als je dergelijke zoekpatronen hebt, controleer dan of je de juiste schattingen krijgt en maak ergens een notitie om ze opnieuw te controleren wanneer er belangrijke wijzigingen in het systeem optreden (zoals een upgrade of een servicepack).